Bem-vindo à documentação do Kubernetes em Português
Como você pode ver, a maior parte da documentação ainda está disponível apenas em inglês, mas não se preocupe, há uma equipe trabalhando na tradução para o português.
Se você quiser participar, você pode entrar no canal Slack #kubernetes-docs-pt e fazer parte da equipe por trás da tradução.
Você também pode acessar o canal para solicitar a tradução de uma página específica ou relatar qualquer erro que possa ter sido encontrado. Qualquer contribuição será bem recebida!
Essa seção lista as diferentes formas de instalar e executar o Kubernetes. Quando você realiza a instalação de um cluster Kubernetes, deve decidir o tipo de instalação baseado em critérios como facilidade de manutenção, segurança, controle, quantidade de recursos disponíveis e a experiência necessária para gerenciar e operar o cluster.
Você pode criar um cluster Kubernetes em uma máquina local, na nuvem, em um datacenter on-premises ou ainda escolher uma oferta de um cluster Kubernetes gerenciado pelo seu provedor de computação em nuvem.
Existem ainda diversos outros tipos de soluções customizadas, que você pode se deparar ao buscar formas de instalação e gerenciamento de seu cluster.
Ambientes de aprendizado
Se você está aprendendo ou pretende aprender mais sobre o Kubernetes, use ferramentas suportadas pela comunidade, ou ferramentas no ecossistema que te permitam criar um cluster Kubernetes em sua máquina virtual.
Ao analisar uma solução para um ambiente de produção, devem ser considerados quais aspectos de operação de um cluster Kubernetes você deseja gerenciar, ou então delegar ao seu provedor.
Temos diversas opções para esse provisionamento, desde o uso de uma ferramenta de deployment de um cluster tal qual o Kubeadm ou o Kubespray quando se trata de um cluster local, ou ainda o uso de um cluster gerenciado por seu provedor de nuvem.
Para a escolha do melhor ambiente e da melhor forma para fazer essa instalação, você deve considerar:
Se você deseja se preocupar com a gestão de backup da sua estrutura do ambiente de gerenciamento
Se você deseja ter um cluster mais atualizado, com novas funcionalidades, ou se deseja seguir a versão suportada pelo fornecedor
Se você deseja ter um cluster com um alto nível de serviço, ou com auto provisionamento de alta disponibilidade
Quanto você deseja pagar por essa produção
2.1 - Instalando a ferramenta kubeadm
Essa página mostra o processo de instalação do conjunto de ferramentas kubeadm.
Para mais informações sobre como criar um cluster com o kubeadm após efetuar a instalação, veja a página Utilizando kubeadm para criar um cluster.
Antes de você começar
Uma máquina com sistema operacional Linux compatível. O projeto Kubernetes provê instruções para distribuições Linux baseadas em Debian e Red Hat, bem como para distribuições sem um gerenciador de pacotes.
2 GB ou mais de RAM por máquina (menos que isso deixará pouca memória para as suas aplicações).
2 CPUs ou mais.
Conexão de rede entre todas as máquinas no cluster. Seja essa pública ou privada.
Nome da máquina na rede, endereço MAC e producy_uuid únicos para cada nó. Mais detalhes podem ser lidos aqui.
Portas específicas abertas nas suas máquinas. Você poderá ler quais são aqui.
Swap desabilitado. Você precisa desabilitar a funcionalidade de swap para que o kubelet funcione de forma correta.
Verificando se o endereço MAC e o product_uiid são únicos para cada nó
Você pode verificar o endereço MAC da interface de rede utilizando o comando ip link ou o comando ipconfig -a.
O product_uuid pode ser verificado utilizando o comando sudo cat /sys/class/dmi/id/product_uuid.
É provável que dispositivos físicos possuam endereços únicos. No entanto, é possível que algumas máquinas virtuais possuam endereços iguais. O Kubernetes utiliza esses valores para identificar unicamente os nós em um cluster. Se esses valores não forem únicos para cada nó, o processo de instalação pode falhar.
Verificando os adaptadores de rede
Se você possuir mais de um adaptador de rede, e seus componentes Kubernetes não forem acessíveis através da rota padrão, recomendamos adicionar o IP das rotas para que os endereços do cluster Kubernetes passem pelo adaptador correto.
Fazendo com que o iptables enxergue o tráfego agregado
Assegure-se de que o módulo br_netfilter está carregado. Isso pode ser feito executando o comando lsmod | grep br_netfilter. Para carrega-lo explicitamente execute sudo modprobe br_netfilter.
Como um requisito para que seus nós Linux enxerguem corretamente o tráfego agregado de rede, você deve garantir que a configuração net.bridge.bridge-nf-call-iptables do seu sysctl está configurada com valor 1. Como no exemplo abaixo:
As portas listadas aqui precisam estar abertas para que os componentes do Kubernetes se comuniquem uns com os outros.
O plugin de rede dos pods que você utiliza também pode requer que algumas portas estejam abertas. Dito que essas portas podem diferir dependendo do plugin, por favor leia a documentação dos plugins sobre quais portas serão necessárias abrir.
Instalando o agente de execução de contêineres
Para executar os contêineres nos Pods, o Kubernetes utiliza um
agente de execução.
Por padrão, o Kubernetes utiliza a interface do agente de execução (CRI) para interagir com o seu agente de execução de contêiner escolhido.
Se você não especificar nenhum agente de execução, o kubeadm irá tentar identifica-lo automaticamente através de uma lista dos sockets Unix mais utilizados. A tabela a seguir lista os agentes de execução e os caminhos dos sockets a eles associados.
Agentes de execução e seus caminhos de socket
Agente de execução
Caminho do socket Unix
Docker
/var/run/dockershim.sock
containerd
/run/containerd/containerd.sock
CRI-O
/var/run/crio/crio.sock
Se tanto o Docker quanto o containerd forem detectados no sistema, o Docker terá precedência. Isso acontece porque o Docker, desde a versão 18.09, já incluí o containerd e ambos são detectaveis mesmo que você só tenha instalado o Docker. Se outros dois ou mais agentes de execução forem detectados, o kubeadm é encerrado com um erro.
O kubelet se integra com o Docker através da implementação CRI dockershim já inclusa.
Você instalará esses pacotes em todas as suas máquinas:
kubeadm: o comando para criar o cluster.
kubelet: o componente que executa em todas as máquinas no seu cluster e cuida de tarefas como a inicialização de pods e contêineres.
kubectl: a ferramenta de linha de comando para interação com o cluster.
O kubeadm não irá instalar ou gerenciar o kubelet ou o kubectl para você, então você
precisará garantir que as versões deles são as mesmas da versão da camada de gerenciamento do Kubernetes
que você quer que o kubeadm instale. Caso isso não seja feito, surge o risco de que uma diferença nas versões
leve a bugs e comportamentos inesperados. Dito isso, uma diferença de menor grandeza nas versões entre o kubelet e a
camada de gerenciamento é suportada, mas a versão do kubelet nunca poderá ser superior à versão do servidor da API.
Por exemplo, um kubelet com a versão 1.7.0 será totalmente compatível com a versão 1.8.0 do servidor da API, mas o contrário não será verdadeiro.
Aviso: Essas instruções removem todos os pacotes Kubernetes de quaisquer atualizações de sistema.
Isso ocorre porque o kubeadm e o Kubernetes requerem alguns cuidados especiais para serem atualizados.
Para mais detalhes sobre compatibilidade entre as versões, veja:
Colocar o SELinux em modo permissivo ao executar setenforce 0 e sed ... efetivamente o desabilita.
Isso é necessário para permitir que os contêineres acessem o sistema de arquivos do hospedeiro, que é utilizado pelas redes dos pods por exemplo.
Você precisará disso até que o suporte ao SELinux seja melhorado no kubelet.
Você pode deixar o SELinux habilitado se você souber como configura-lo, mas isso pode exegir configurações que não são suportadas pelo kubeadm.
Instale os plugins CNI (utilizados por grande parte das redes de pods):
Escolha o diretório para baixar os arquivos de comandos.
Nota: A variável DOWNLOAD_DIR precisa estar configurada para um diretório que permita escrita.
Se você estiver utilizando o Flatcar Container Linux, configure a váriavel de ambiente DOWNLOAD_DIR=/opt/bin.
Instale o crictl (utilizado pelo kubeadm e pela Interface do Agente de execução do Kubelet (CRI))
CRICTL_VERSION="v1.22.0"ARCH="amd64"
curl -L "https://github.com/kubernetes-sigs/cri-tools/releases/download/${CRICTL_VERSION}/crictl-${CRICTL_VERSION}-linux-${ARCH}.tar.gz" | sudo tar -C $DOWNLOAD_DIR -xz
Instale o kubeadm, o kubelet, e o kubectl e adicione o serviço systemd kubelet:
RELEASE="$(curl -sSL https://dl.k8s.io/release/stable.txt)"ARCH="amd64"cd$DOWNLOAD_DIR
sudo curl -L --remote-name-all https://storage.googleapis.com/kubernetes-release/release/${RELEASE}/bin/linux/${ARCH}/{kubeadm,kubelet,kubectl}
sudo chmod +x {kubeadm,kubelet,kubectl}RELEASE_VERSION="v0.4.0"
curl -sSL "https://raw.githubusercontent.com/kubernetes/release/${RELEASE_VERSION}/cmd/kubepkg/templates/latest/deb/kubelet/lib/systemd/system/kubelet.service" | sed "s:/usr/bin:${DOWNLOAD_DIR}:g" | sudo tee /etc/systemd/system/kubelet.service
sudo mkdir -p /etc/systemd/system/kubelet.service.d
curl -sSL "https://raw.githubusercontent.com/kubernetes/release/${RELEASE_VERSION}/cmd/kubepkg/templates/latest/deb/kubeadm/10-kubeadm.conf" | sed "s:/usr/bin:${DOWNLOAD_DIR}:g" | sudo tee /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
Habilite e inicie o kubelet:
systemctl enable --now kubelet
Nota: A distribuição Flatcar Container Linux instala o diretório /usr como um sistema de arquivos apenas para leitura.
Antes de inicializar o seu cluster, você precisa de alguns passos adicionais para configurar um diretório com escrita.
Veja o Guia de solução de problemas do Kubeadm para aprender como configurar um diretório com escrita.
O kubelet agora ficará reiniciando de alguns em alguns segundos, enquanto espera por instruções vindas do kubeadm.
Configurando um driver cgroup
Tanto o agente de execução quanto o kubelet possuem uma propriedade chamada
"driver cgroup", que é importante
para o gerenciamento dos cgroups em máquinas Linux.
Aviso:
A compatibilidade entre os drivers cgroup e o agente de execução é necessária. Sem ela o processo do kubelet irá falhar.
A seção de Conceitos irá te ajudar a aprender mais sobre as partes do ecossistema Kubernetes e as abstrações que o Kubernetes usa para representar seu cluster.
Ela irá lhe ajudar a obter um entendimento mais profundo sobre como o Kubernetes funciona.
3.1 - Visão Geral
Obtenha uma visão em alto-nível do Kubernetes e dos componentes a partir dos quais ele é construído.
3.1.1 - O que é Kubernetes?
Kubernetes é um plataforma de código aberto, portável e extensiva para o gerenciamento de cargas de trabalho e serviços distribuídos em contêineres, que facilita tanto a configuração declarativa quanto a automação. Ele possui um ecossistema grande, e de rápido crescimento. Serviços, suporte, e ferramentas para Kubernetes estão amplamente disponíveis.
Essa página é uma visão geral do Kubernetes.
Kubernetes é um plataforma de código aberto, portável e extensiva para o gerenciamento de cargas de trabalho e serviços distribuídos em contêineres, que facilita tanto a configuração declarativa quanto a automação. Ele possui um ecossistema grande, e de rápido crescimento. Serviços, suporte, e ferramentas para Kubernetes estão amplamente disponíveis.
O Google tornou Kubernetes um projeto de código-aberto em 2014. O Kubernetes combina mais de 15 anos de experiência do Google executando cargas de trabalho produtivas em escala, com as melhores idéias e práticas da comunidade.
O nome Kubernetes tem origem no Grego, significando timoneiro ou piloto. K8s é a abreviação derivada pela troca das oito letras "ubernete" por "8", se tornado K"8"s.
Voltando no tempo
Vamos dar uma olhada no porque o Kubernetes é tão útil, voltando no tempo.
Era da implantação tradicional: No início, as organizações executavam aplicações em servidores físicos. Não havia como definir limites de recursos para aplicações em um mesmo servidor físico, e isso causava problemas de alocação de recursos. Por exemplo, se várias aplicações fossem executadas em um mesmo servidor físico, poderia haver situações em que uma aplicação ocupasse a maior parte dos recursos e, como resultado, o desempenho das outras aplicações seria inferior. Uma solução para isso seria executar cada aplicação em um servidor físico diferente. Mas isso não escalava, pois os recursos eram subutilizados, e se tornava custoso para as organizações manter muitos servidores físicos.
Era da implantação virtualizada: Como solução, a virtualização foi introduzida. Esse modelo permite que você execute várias máquinas virtuais (VMs) em uma única CPU de um servidor físico. A virtualização permite que as aplicações sejam isoladas entre as VMs, e ainda fornece um nível de segurança, pois as informações de uma aplicação não podem ser acessadas livremente por outras aplicações.
A virtualização permite melhor utilização de recursos em um servidor físico, e permite melhor escalabilidade porque uma aplicação pode ser adicionada ou atualizada facilmente, reduz os custos de hardware e muito mais. Com a virtualização, você pode apresentar um conjunto de recursos físicos como um cluster de máquinas virtuais descartáveis.
Cada VM é uma máquina completa que executa todos os componentes, incluindo seu próprio sistema operacional, além do hardware virtualizado.
Era da implantação em contêineres: Contêineres são semelhantes às VMs, mas têm propriedades de isolamento flexibilizados para compartilhar o sistema operacional (SO) entre as aplicações. Portanto, os contêineres são considerados leves. Semelhante a uma VM, um contêiner tem seu próprio sistema de arquivos, compartilhamento de CPU, memória, espaço de processo e muito mais. Como eles estão separados da infraestrutura subjacente, eles são portáveis entre nuvens e distribuições de sistema operacional.
Contêineres se tornaram populares porque eles fornecem benefícios extra, tais como:
Criação e implantação ágil de aplicações: aumento da facilidade e eficiência na criação de imagem de contêiner comparado ao uso de imagem de VM.
Desenvolvimento, integração e implantação contínuos: fornece capacidade de criação e de implantação de imagens de contêiner de forma confiável e frequente, com a funcionalidade de efetuar reversões rápidas e eficientes (devido à imutabilidade da imagem).
Separação de interesses entre Desenvolvimento e Operações: crie imagens de contêineres de aplicações no momento de construção/liberação em vez de no momento de implantação, desacoplando as aplicações da infraestrutura.
A capacidade de observação (Observabilidade) não apenas apresenta informações e métricas no nível do sistema operacional, mas também a integridade da aplicação e outros sinais.
Consistência ambiental entre desenvolvimento, teste e produção: funciona da mesma forma em um laptop e na nuvem.
Portabilidade de distribuição de nuvem e sistema operacional: executa no Ubuntu, RHEL, CoreOS, localmente, nas principais nuvens públicas e em qualquer outro lugar.
Gerenciamento centrado em aplicações: eleva o nível de abstração da execução em um sistema operacional em hardware virtualizado à execução de uma aplicação em um sistema operacional usando recursos lógicos.
Microserviços fracamente acoplados, distribuídos, elásticos e livres: as aplicações são divididas em partes menores e independentes e podem ser implantados e gerenciados dinamicamente - não uma pilha monolítica em execução em uma grande máquina de propósito único.
Isolamento de recursos: desempenho previsível de aplicações.
Utilização de recursos: alta eficiência e densidade.
Por que você precisa do Kubernetes e o que ele pode fazer
Os contêineres são uma boa maneira de agrupar e executar suas aplicações. Em um ambiente de produção, você precisa gerenciar os contêineres que executam as aplicações e garantir que não haja tempo de inatividade. Por exemplo, se um contêiner cair, outro contêiner precisa ser iniciado. Não seria mais fácil se esse comportamento fosse controlado por um sistema?
É assim que o Kubernetes vem ao resgate! O Kubernetes oferece uma estrutura para executar sistemas distribuídos de forma resiliente. Ele cuida do escalonamento e do recuperação à falha de sua aplicação, fornece padrões de implantação e muito mais. Por exemplo, o Kubernetes pode gerenciar facilmente uma implantação no método canário para seu sistema.
O Kubernetes oferece a você:
Descoberta de serviço e balanceamento de carga
O Kubernetes pode expor um contêiner usando o nome DNS ou seu próprio endereço IP. Se o tráfego para um contêiner for alto, o Kubernetes pode balancear a carga e distribuir o tráfego de rede para que a implantação seja estável.
Orquestração de armazenamento
O Kubernetes permite que você monte automaticamente um sistema de armazenamento de sua escolha, como armazenamentos locais, provedores de nuvem pública e muito mais.
Lançamentos e reversões automatizadas
Você pode descrever o estado desejado para seus contêineres implantados usando o Kubernetes, e ele pode alterar o estado real para o estado desejado em um ritmo controlada. Por exemplo, você pode automatizar o Kubernetes para criar novos contêineres para sua implantação, remover os contêineres existentes e adotar todos os seus recursos para o novo contêiner.
Empacotamento binário automático
Você fornece ao Kubernetes um cluster de nós que pode ser usado para executar tarefas nos contêineres. Você informa ao Kubernetes de quanta CPU e memória (RAM) cada contêiner precisa. O Kubernetes pode encaixar contêineres em seus nós para fazer o melhor uso de seus recursos.
Autocorreção
O Kubernetes reinicia os contêineres que falham, substitui os contêineres, elimina os contêineres que não respondem à verificação de integridade definida pelo usuário e não os anuncia aos clientes até que estejam prontos para servir.
Gerenciamento de configuração e de segredos
O Kubernetes permite armazenar e gerenciar informações confidenciais, como senhas, tokens OAuth e chaves SSH. Você pode implantar e atualizar segredos e configuração de aplicações sem reconstruir suas imagens de contêiner e sem expor segredos em sua pilha de configuração.
O que o Kubernetes não é
O Kubernetes não é um sistema PaaS (plataforma como serviço) tradicional e completo. Como o Kubernetes opera no nível do contêiner, e não no nível do hardware, ele fornece alguns recursos geralmente aplicáveis comuns às ofertas de PaaS, como implantação, escalonamento, balanceamento de carga, e permite que os usuários integrem suas soluções de logging, monitoramento e alerta. No entanto, o Kubernetes não é monolítico, e essas soluções padrão são opcionais e conectáveis. O Kubernetes fornece os blocos de construção para a construção de plataformas de desenvolvimento, mas preserva a escolha e flexibilidade do usuário onde é importante.
Kubernetes:
Não limita os tipos de aplicações suportadas. O Kubernetes visa oferecer suporte a uma variedade extremamente diversa de cargas de trabalho, incluindo cargas de trabalho sem estado, com estado e de processamento de dados. Se uma aplicação puder ser executada em um contêiner, ele deve ser executado perfeitamente no Kubernetes.
Não implanta código-fonte e não constrói sua aplicação. Os fluxos de trabalho de integração contínua, entrega e implantação (CI/CD) são determinados pelas culturas e preferências da organização, bem como pelos requisitos técnicos.
Não fornece serviços em nível de aplicação, tais como middleware (por exemplo, barramentos de mensagem), estruturas de processamento de dados (por exemplo, Spark), bancos de dados (por exemplo, MySQL), caches, nem sistemas de armazenamento em cluster (por exemplo, Ceph), como serviços integrados. Esses componentes podem ser executados no Kubernetes e/ou podem ser acessados por aplicações executadas no Kubernetes por meio de mecanismos portáteis, como o Open Service Broker.
Não dita soluções de logging, monitoramento ou alerta. Ele fornece algumas integrações como prova de conceito e mecanismos para coletar e exportar métricas.
Não fornece nem exige um sistema/idioma de configuração (por exemplo, Jsonnet). Ele fornece uma API declarativa que pode ser direcionada por formas arbitrárias de especificações declarativas.
Não fornece nem adota sistemas abrangentes de configuração de máquinas, manutenção, gerenciamento ou autocorreção.
Adicionalmente, o Kubernetes não é um mero sistema de orquestração. Na verdade, ele elimina a necessidade de orquestração. A definição técnica de orquestração é a execução de um fluxo de trabalho definido: primeiro faça A, depois B e depois C. Em contraste, o Kubernetes compreende um conjunto de processos de controle independentes e combináveis que conduzem continuamente o estado atual em direção ao estado desejado fornecido. Não importa como você vai de A para C. O controle centralizado também não é necessário. Isso resulta em um sistema que é mais fácil de usar e mais poderoso, robusto, resiliente e extensível.
Um cluster Kubernetes consiste de componentes que representam a camada de gerenciamento, e um conjunto de máquinas chamadas nós.
Ao implantar o Kubernetes, você obtém um cluster.
Um cluster Kubernetes consiste em um conjunto de servidores de processamento, chamados nós, que executam aplicações containerizadas. Todo cluster possui ao menos um servidor de processamento (worker node).
O servidor de processamento hospeda os Pods que são componentes de uma aplicação. O ambiente de gerenciamento gerencia os nós de processamento e os Pods no cluster. Em ambientes de produção, o ambiente de gerenciamento geralmente executa em múltiplos computadores e um cluster geralmente executa em múltiplos nós (nodes) , provendo tolerância a falhas e alta disponibilidade.
Este documento descreve os vários componentes que você precisa ter para implantar um cluster Kubernetes completo e funcional.
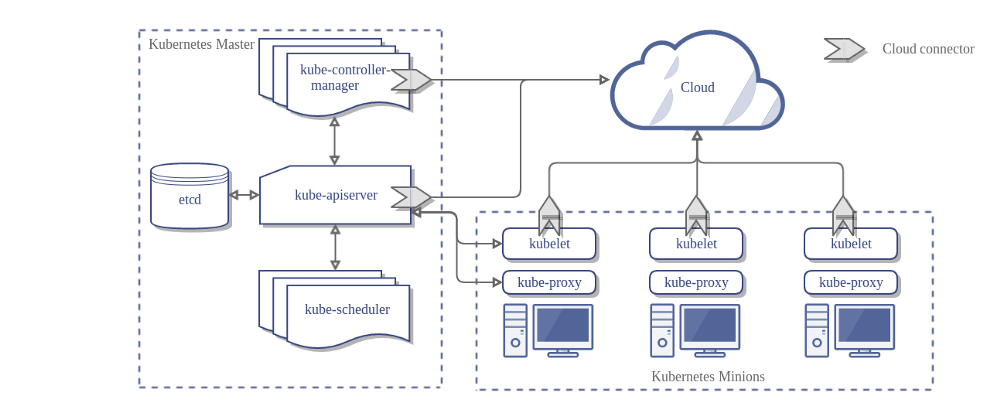
Esse é o diagrama de um cluster Kubernetes com todos os componentes interligados.
Componentes da camada de gerenciamento
Os componentes da camada de gerenciamento tomam decisões globais sobre o cluster (por exemplo, agendamento de pods), bem como detectam e respondem aos eventos do cluster (por exemplo, iniciando um novo pod quando o campo replicas de um Deployment não está atendido).
Os componentes da camada de gerenciamento podem ser executados em qualquer máquina do cluster. Contudo, para simplificar, os scripts de configuração normalmente iniciam todos os componentes da camada de gerenciamento na mesma máquina, e não executa contêineres de usuário nesta máquina. Veja Construindo clusters de alta disponibilidade para um exemplo de configuração de múltiplas VMs para camada de gerenciamento (multi-main-VM).
kube-apiserver
O servidor de API é um componente da Camada de gerenciamento do Kubernetes que expõe a API do Kubernetes.
O servidor de API é o front end para a camada de gerenciamento do Kubernetes.
A principal implementação de um servidor de API do Kubernetes é kube-apiserver.
O kube-apiserver foi projetado para ser escalonado horizontalmente — ou seja, ele pode ser escalado com a implantação de mais instâncias.
Você pode executar várias instâncias do kube-apiserver e balancear (balanceamento de carga, etc) o tráfego entre essas instâncias.
etcd
Armazenamento do tipo Chave-Valor consistente e em alta-disponibilidade usado como repositório de apoio do Kubernetes para todos os dados do cluster.
Se o seu cluster Kubernetes usa etcd como seu armazenamento de apoio, certifique-se de ter um plano de back up para seus dados.
Você pode encontrar informações detalhadas sobre o etcd na seção oficial da documentação.
kube-scheduler
Componente da camada de gerenciamento que observa os pods recém-criados sem nenhum nó atribuído, e seleciona um nó para executá-los.
Os fatores levados em consideração para as decisões de agendamento incluem:
requisitos de recursos individuais e coletivos, hardware/software/política de restrições, especificações de afinidade e antiafinidade, localidade de dados, interferência entre cargas de trabalho, e prazos.
kube-controller-manager
Componente da camada de gerenciamento que executa os processos de controlador.
Logicamente, cada controlador está em um processo separado, mas para reduzir a complexidade, eles todos são compilados num único binário e executam em um processo único.
Alguns tipos desses controladores são:
Controlador de nó: responsável por perceber e responder quando os nós caem.
Controlador de Job: Observa os objetos Job que representam tarefas únicas e, em seguida, cria pods para executar essas tarefas até a conclusão.
Controlador de endpoints: preenche o objeto Endpoints (ou seja, junta os Serviços e os pods).
Controladores de conta de serviço e de token: crie contas padrão e tokens de acesso de API para novos namespaces.
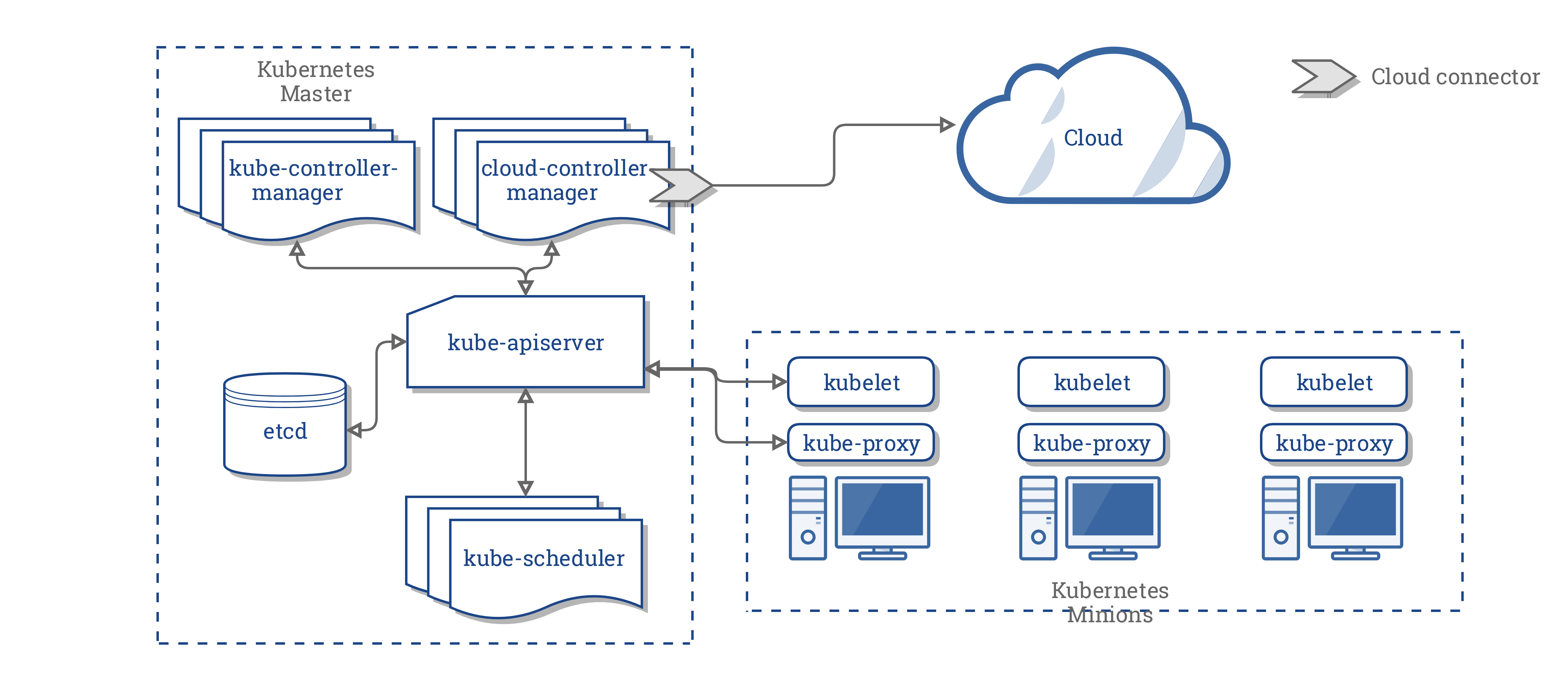
cloud-controller-manager
Um componente da camada de gerenciamento do Kubernetes
que incorpora a lógica de controle específica da nuvem. O gerenciador de controle de nuvem permite que você vincule seu
cluster na API do seu provedor de nuvem, e separar os componentes que interagem com essa plataforma de nuvem a partir de componentes que apenas interagem com seu cluster.
O cloud-controller-manager executa apenas controladores que são específicos para seu provedor de nuvem.
Se você estiver executando o Kubernetes em suas próprias instalações ou em um ambiente de aprendizagem dentro de seu
próprio PC, o cluster não possui um gerenciador de controlador de nuvem.
Tal como acontece com o kube-controller-manager, o cloud-controller-manager combina vários ciclos de controle logicamente independentes em um binário único que você executa como um processo único. Você pode escalar horizontalmente (exectuar mais de uma cópia) para melhorar o desempenho ou para auxiliar na tolerância a falhas.
Os seguintes controladores podem ter dependências de provedor de nuvem:
Controlador de nó: para verificar junto ao provedor de nuvem para determinar se um nó foi excluído da nuvem após parar de responder.
Controlador de rota: para configurar rotas na infraestrutura de nuvem subjacente.
Controlador de serviço: Para criar, atualizar e excluir balanceadores de carga do provedor de nuvem.
Node Components
Os componentes de nó são executados em todos os nós, mantendo os pods em execução e fornecendo o ambiente de execução do Kubernetes.
kubelet
Um agente que é executado em cada node no cluster. Ele garante que os contêineres estejam sendo executados em um Pod.
O kubelet utiliza um conjunto de PodSpecs que são fornecidos por vários mecanismos e garante que os contêineres descritos nesses PodSpecs estejam funcionando corretamente. O kubelet não gerencia contêineres que não foram criados pelo Kubernetes.
kube-proxy
kube-proxy é um proxy de rede executado em cada nó no seu cluster,
implementando parte do conceito de serviço do Kubernetes.
kube-proxy
mantém regras de rede nos nós. Estas regras de rede permitem a comunicação de rede com seus pods a partir de sessões de rede dentro ou fora de seu cluster.
kube-proxy usa a camada de filtragem de pacotes do sistema operacional se houver uma e estiver disponível. Caso contrário, o kube-proxy encaminha o tráfego ele mesmo.
Container runtime
O agente de execução (runtime) de contêiner é o software responsável por executar os contêineres.
Complementos (addons) usam recursos do Kubernetes (DaemonSet, Deployment, etc) para implementar funcionalidades do cluster. Como fornecem funcionalidades em nível do cluster, recursos de addons que necessitem ser criados dentro de um namespace pertencem ao namespacekube-system.
Alguns addons selecionados são descritos abaixo; para uma lista estendida dos addons disponíveis, por favor consulte Addons.
DNS
Embora os outros complementos não sejam estritamente necessários, todos os clusters do Kubernetes devem ter um DNS do cluster, já que muitos exemplos dependem disso.
O DNS do cluster é um servidor DNS, além de outros servidores DNS em seu ambiente, que fornece registros DNS para serviços do Kubernetes.
Os contêineres iniciados pelo Kubernetes incluem automaticamente esse servidor DNS em suas pesquisas DNS.
Web UI (Dashboard)
Dashboard é uma interface de usuário Web, de uso geral, para clusters do Kubernetes. Ele permite que os usuários gerenciem e solucionem problemas de aplicações em execução no cluster, bem como o próprio cluster.
Monitoramento de recursos do contêiner
Monitoramento de recursos do contêiner registra métricas de série temporal genéricas sobre os contêineres em um banco de dados central e fornece uma interface de usuário para navegar por esses dados.
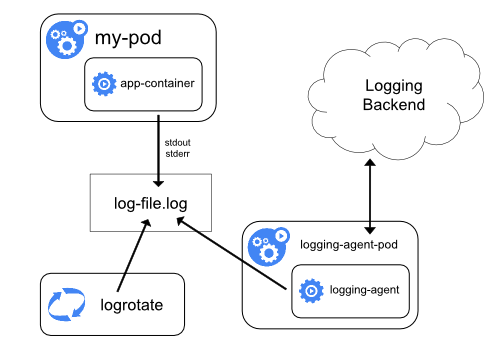
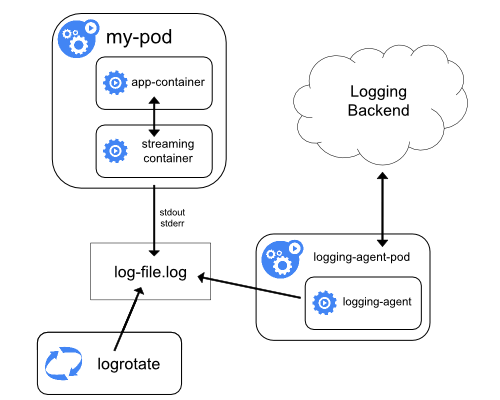
Logging a nivel do cluster
Um mecanismo de logging a nível do cluster é responsável por guardar os logs dos contêineres em um armazenamento central de logs com um interface para navegação/pesquisa.
Cada objeto em um cluster possui um Nome que é único para aquele tipo de recurso.
Todo objeto do Kubernetes também possui um UID que é único para todo o cluster.
Por exemplo, você pode ter apenas um Pod chamado "myapp-1234", porém você pode ter um Pod
e um Deployment ambos com o nome "myapp-1234".
Para atributos não únicos providenciados por usuário, Kubernetes providencia labels e annotations.
Nomes
Recursos Kubernetes podem ter nomes com até 253 caracteres. Os caracteres permitidos em nomes são: dígitos (0-9), letras minúsculas (a-z), -, e ..
A seguir, um exemplo para um Pod chamado nginx-demo.
Esse documento descreve o estado atual dos volumes persistentes no Kubernetes. Sugerimos que esteja familiarizado com volumes.
Introdução
O gerenciamento de armazenamento é uma questão bem diferente do gerenciamento de instâncias computacionais. O subsistema PersistentVolume provê uma API para usuários e administradores que mostra de forma detalhada de como o armazenamento é provido e como ele é consumido. Para isso, nós introduzimos duas novas APIs: PersistentVolume e PersistentVolumeClaim.
Um PersistentVolume (PV) é uma parte do armazenamento dentro do cluster que tenha sido provisionada por um administrador, ou dinamicamente utilizando Classes de Armazenamento. Isso é um recurso dentro do cluster da mesma forma que um nó também é. PVs são plugins de volume da mesma forma que Volumes, porém eles têm um ciclo de vida independente de qualquer Pod que utilize um PV. Essa API tem por objetivo mostrar os detalhes da implementação do armazenamento, seja ele NFS, iSCSI, ou um armazenamento específico de um provedor de cloud pública.
Uma_PersistentVolumeClaim_ (PVC) é uma requisição para armazenamento por um usuário. É similar a um Pod. Pods utilizam recursos do nó e PVCs utilizam recursos do PV. Pods podem solicitar níveis específicos de recursos (CPU e Memória). Claims podem solicitar tamanho e modos de acesso específicos (exemplo: montagem como ReadWriteOnce, ReadOnlyMany ou ReadWriteMany, veja Modos de Acesso).
Enquanto as PersistentVolumeClaims permitem que um usuário utilize recursos de armazenamento de forma limitada, é comum que usuários precisem de PersistentVolumes com diversas propriedades, como desempenho, para problemas diversos. Os administradores de cluster precisam estar aptos a oferecer uma variedade de PersistentVolumes que difiram em tamanho e modo de acesso, sem expor os usuários a detalhes de como esses volumes são implementados. Para necessidades como essas, temos o recurso de StorageClass.
PVs são recursos dentro um cluster. PVCs são requisições para esses recursos e também atuam como uma validação da solicitação desses recursos. O ciclo de vida da interação entre PVs e PVCs funcionam da seguinte forma:
Provisionamento
Existem duas formas de provisionar um PV: estaticamente ou dinamicamente.
Estático
O administrador do cluster cria uma determinada quantidade de PVs. Eles possuem todos os detalhes do armazenamento os quais estão atrelados, que neste caso fica disponível para utilização por um usuário dentro do cluster. Eles estão presentes na API do Kubernetes e disponíveis para utilização.
Dinâmico
Quando nenhum dos PVs estáticos, que foram criados anteriormente pelo administrador, satisfazem os critérios de uma PersistentVolumeClaim enviado por um usuário, o cluster pode tentar realizar um provisionamento dinâmico para atender a essa PVC. Esse provisionamento é baseado em StorageClasses: a PVC deve solicitar uma classe de armazenamento e o administrador deve ter previamente criado e configurado essa classe para que o provisionamento dinâmico possa ocorrer. Requisições que solicitam a classe "" efetivamente desabilitam o provisionamento dinâmico para elas mesmas.
Para habilitar o provisionamento de armazenamento dinâmico baseado em classe de armazenamento, o administrador do cluster precisa habilitar o controle de admissãoDefaultStorageClass no servidor da API. Isso pode ser feito, por exemplo, garantindo que DefaultStorageClass esteja entre aspas simples, ordenado por uma lista de valores para a flag --enable-admission-plugins, componente do servidor da API. Para mais informações sobre os comandos das flags do servidor da API, consulte a documentação kube-apiserver.
Binding
Um usuário cria, ou em caso de um provisionamento dinâmico já ter criado, uma PersistentVolumeClaim solicitando uma quantidade específica de armazenamento e um determinado modo de acesso. Um controle de loop no master monitora por novas PVCs, encontra um PV (se possível) que satisfaça os requisitos e realiza o bind. Se o PV foi provisionado dinamicamente por uma PVC, o loop sempre vai fazer o bind desse PV com essa PVC em específico. Caso contrário, o usuário vai receber no mínimo o que ele havia solicitado, porém, o volume possa exceder em relação à solicitação inicial. Uma vez realizado esse processo, PersistentVolumeClaim sempre vai ter um bind exclusivo, sem levar em conta como o isso aconteceu. Um bind entre uma PVC e um PV é um mapeamento de um para um, utilizando o ClaimRef que é um bind bidirecional entre o PersistentVolume e o PersistentVolumeClaim.
As requisições permanecerão sem bind se o volume solicitado não existir. O bind ocorrerá somente se os requisitos forem atendidos exatamente da mesma forma como solicitado. Por exemplo, um bind de uma PVC de 100 GB não ocorrerá num cluster que foi provisionado com vários PVs de 50 GB. O bind ocorrerá somente no momento em que um PV de 100 GB for adicionado.
Utilização
Pods utilizam requisições como volumes. O cluster inspeciona a requisição para encontrar o volume atrelado a ela e monta esse volume para um Pod. Para volumes que suportam múltiplos modos de acesso, o usuário especifica qual o modo desejado quando utiliza essas requisições.
Uma vez que o usuário tem a requisição atrelada a um PV, ele pertence ao usuário pelo tempo que ele precisar. Usuários agendam Pods e acessam seus PVs requisitados através da seção persistentVolumeClaim no bloco volumes do Pod. Para mais detalhes sobre isso, veja Requisições como Volumes.
Proteção de Uso de um Objeto de Armazenamento
O propósito da funcionalidade do Objeto de Armazenamento em Proteção de Uso é garantir que as PersistentVolumeClaims (PVCs) que estejam sendo utilizadas por um Pod e PersistentVolume (PVs) que pertençam aos PVCs não sejam removidos do sistema, pois isso pode resultar numa perda de dados.
Nota: Uma PVC está sendo utilizada por um Pod quando existe um Pod que está usando essa PVC.
Se um usuário deleta uma PVC que está sendo utilizada por um Pod, esta PVC não é removida imediatamente. A remoção da PVC é adiada até que a PVC não esteja mais sendo utilizado por nenhum Pod. Se um administrador deleta um PV que está atrelado a uma PVC, o PV não é removido imediatamente também. A remoção do PV é adiada até que o PV não esteja mais atrelado à PVC.
Note que uma PVC é protegida quando o status da PVC é Terminating e a lista Finalizers contém kubernetes.io/pvc-protection:
Quando um usuário não precisar mais utilizar um volume, ele pode deletar a PVC pela API, que, permite a recuperação do recurso. A política de recuperação para um PersistentVolume diz ao cluster o que fazer com o volume após ele ter sido liberado da sua requisição. Atualmente, volumes podem ser Retidos, Reciclados ou Deletados.
Retenção
A política Retain permite a recuperação de forma manual do recurso. Quando a PersistentVolumeClaim é deletada, ela continua existindo e o volume é considerado "livre". Mas ele ainda não está disponível para outra requisição porque os dados da requisição anterior ainda permanecem no volume. Um administrador pode manualmente recuperar o volume executando os seguintes passos:
Deletar o PersistentVolume. O armazenamento associado à infraestrutura externa (AWS EBS, GCE PD, Azure Disk ou Cinder volume) ainda continuará existindo após o PV ser deletado.
Limpar os dados de forma manual no armazenamento associado.
Deletar manualmente o armazenamento associado. Caso você queira utilizar o mesmo armazenamento, crie um novo PersistentVolume com esse armazenamento.
Deletar
Para plugins de volume que suportam a política de recuperação Delete, a deleção vai remover o tanto o PersistentVolume do Kubernetes, quanto o armazenamento associado à infraestrutura externa, como AWS EBS, GCE PD, Azure Disk, ou Cinder volume. Volumes que foram provisionados dinamicamente herdam a política de retenção da sua StorageClass, que por padrão é Delete. O administrador precisa configurar a StorageClass de acordo com as necessidades dos usuários. Caso contrário, o PV deve ser editado ou reparado após sua criação. Veja Alterar a política de retenção de um PersistentVolume.
Reciclar
Aviso: A política de retenção Recycle está depreciada. Ao invés disso, recomendamos a utilização de provisionamento dinâmico.
Em caso do volume plugin ter suporte a essa operação, a política de retenção Recycle faz uma limpeza básica (rm -rf /thevolume/*) no volume e torna ele disponível novamente para outra requisição.
Contudo, um administrador pode configurar um template personalizado de um Pod reciclador utilizando a linha de comando do gerenciamento de controle do Kubernetes como descrito em referência.
O Pod reciclador personalizado deve conter a spec volume como é mostrado no exemplo abaixo:
Especificando um PersistentVolume na PersistentVolumeClaim, você declara um bind entre uma PVC e um PV específico. O bind ocorrerá se o PersistentVolume existir e não estiver reservado por uma PersistentVolumeClaims através do seu campo claimRef.
O bind ocorre independentemente se algum volume atender ao critério, incluindo afinidade de nó. A camada de gerenciamento verifica se a classe de armazenamento, modo de acesso e tamanho do armazenamento solicitado ainda são válidos.
apiVersion:v1kind:PersistentVolumeClaimmetadata:name:foo-pvcnamespace:foospec:storageClassName:""# Empty string must be explicitly set otherwise default StorageClass will be setvolumeName:foo-pv...
Esse método não garante nenhum privilégio de bind no PersistentVolume. Para evitar que alguma outra PersistentVolumeClaims possa usar o PV que você especificar, você precisa primeiro reservar esse volume de armazenamento. Especifique sua PersistentVolumeClaim no campo claimRef do PV para que outras PVCs não façam bind nele.
Isso é útil se você deseja utilizar PersistentVolumes que possuem suas claimPolicy configuradas para Retain, incluindo situações onde você estiver reutilizando um PV existente.
Expandindo Requisições de Volumes Persistentes
FEATURE STATE:Kubernetes v1.11 [beta]
Agora, o suporte à expansão de PersistentVolumeClaims (PVCs) já é habilitado por padrão. Você pode expandir os tipos de volumes abaixo:
Para solicitar um volume maior para uma PVC, edite a PVC e especifique um tamanho maior. Isso irá fazer com o que volume atrelado ao respectivo PersistentVolume seja expandido. Nunca um PersistentVolume é criado para satisfazer a requisição. Ao invés disso, um volume existente é redimensionado.
Expansão de volume CSI
FEATURE STATE:Kubernetes v1.16 [beta]
O suporte à expansão de volumes CSI é habilitada por padrão, porém é necessário um driver CSI específico para suportar a expansão do volume. Verifique a documentação do driver CSI específico para mais informações.
Redimensionando um volume que contém um sistema de arquivo
Só podem ser redimensionados os volumes que contém os seguintes sistemas de arquivo: XFS, Ext3 ou Ext4.
Quando um volume contém um sistema de arquivo, o sistema de arquivo somente é redimensionado quando um novo Pod está utilizando a PersistentVolumeClaim no modo ReadWrite. A expansão de sistema de arquivo é feita quando um Pod estiver inicializando ou quando um Pod estiver em execução e o respectivo sistema de arquivo tenha suporte para expansão a quente.
FlexVolumes permitem redimensionamento se o RequiresFSResize do drive é configurado como true. O FlexVolume pode ser redimensionado na reinicialização do Pod.
Redimensionamento de uma PersistentVolumeClaim em uso
FEATURE STATE:Kubernetes v1.15 [beta]
Nota: A Expansão de PVCs em uso está disponível como beta desde o Kubernetes 1.15, e como alpha desde a versão 1.11. A funcionalidade ExpandInUsePersistentVolumes precisa ser habilitada, o que já está automático para vários clusters que possuem funcionalidades beta. Verifique a documentação feature gate para mais informações.
Neste caso, você não precisa deletar e recriar um Pod ou um deployment que está sendo utilizado por uma PVC existente.
Automaticamente, qualquer PVC em uso fica disponível para o Pod assim que o sistema de arquivo for expandido.
Essa funcionalidade não tem efeito em PVCs que não estão em uso por um Pod ou deployment. Você deve criar um Pod que utilize a PVC antes que a expansão seja completada.
Da mesma forma que outros tipos de volumes - volumes FlexVolume também podem ser expandidos quando estiverem em uso por um Pod.
Nota: Redimensionamento de FlexVolume somente é possível quando o respectivo driver suportar essa operação.
Nota: Expandir volumes do tipo EBS é uma operação que toma muito tempo. Além disso, só é possível fazer uma modificação por volume a cada 6 horas.
Recuperação em caso de falha na expansão de volumes
Se a expansão do respectivo armazenamento falhar, o administrador do cluster pode recuperar manualmente o estado da Persistent Volume Claim (PVC) e cancelar as solicitações de redimensionamento. Caso contrário, as tentativas de solicitação de redimensionamento ocorrerão de forma contínua pelo controlador sem nenhuma intervenção do administrador.
Marque o PersistentVolume(PV) que estiver atrelado à PersistentVolumeClaim(PVC) com a política de recuperação Retain.
Delete a PVC. Desde que o PV tenha a política de recuperação Retain - nenhum dado será perdido quando a PVC for recriada.
Delete a entrada claimRef da especificação do PV para que uma PVC possa fazer bind com ele. Isso deve tornar o PV Available.
Recrie a PVC com um tamanho menor que o PV e configure o campo volumeName da PCV com o nome do PV. Isso deve fazer o bind de uma nova PVC a um PV existente.
Não esqueça de restaurar a política de recuperação do PV.
Tipos de volumes persistentes
Tipos de PersistentVolume são implementados como plugins. Atualmente o Kubernetes suporta os plugins abaixo:
hostPath - HostPath volume
(somente para teste de nó único; ISSO NÃO FUNCIONARÁ num cluster multi-nós; ao invés disso, considere a utilização de volume local.)
photonPersistentDisk - Controlador Photon para disco persistente.
(Esse tipo de volume não funciona mais desde a removação do provedor de cloud correspondente.)
Nota: Talvez sejam necessários programas auxiliares para um determinado tipo de volume utilizar um PersistentVolume no cluster. Neste exemplo, o PersistentVolume é do tipo NFS e o programa auxiliar /sbin/mount.nfs é necessário para suportar a montagem dos sistemas de arquivos NFS.
Capacidade
Geralmente, um PV terá uma capacidade de armazenamento específica. Isso é configurado usando o atributo capacity do PV. Veja o Modelo de Recurso do Kubernetes para entender as unidades aceitas pelo atributo capacity.
Atualmente, o tamanho do armazenamento é o único recurso que pode ser configurado ou solicitado. Os futuros atributos podem incluir IOPS, throughput, etc.
Modo do Volume
FEATURE STATE:Kubernetes v1.18 [stable]
O Kubernetes suporta dois volumeModes de PersistentVolumes: Filesystem e Block.
volumeMode é um parâmetro opcional da API.
Filesystem é o modo padrão utilizado quando o parâmetro volumeMode é omitido.
Um volume com volumeMode: Filesystem é montado em um diretório nos Pods. Se o volume for de um dispositivo de bloco e ele estiver vazio, o Kubernetes cria o sistema de arquivo no dispositivo antes de fazer a montagem pela primeira vez.
Você pode configurar o valor do volumeMode para Block para utilizar um disco bruto como volume. Esse volume é apresentado num Pod como um dispositivo de bloco, sem nenhum sistema de arquivo. Esse modo é útil para prover ao Pod a forma mais rápida para acessar um volume, sem nenhuma camada de sistema de arquivo entre o Pod e o volume. Por outro lado, a aplicação que estiver rodando no Pod deverá saber como tratar um dispositivo de bloco. Veja Suporte a Volume de Bloco Bruto para um exemplo de como utilizar o volume como volumeMode: Block num Pod.
Modos de Acesso
Um PersistentVolume pode ser montado num host das mais variadas formas suportadas pelo provedor. Como mostrado na tabela abaixo, os provedores terão diferentes capacidades e cada modo de acesso do PV são configurados nos modos específicos suportados para cada volume em particular. Por exemplo, o NFS pode suportar múltiplos clientes read/write, mas um PV NFS específico pode ser exportado no server como read-only. Cada PV recebe seu próprio modo de acesso que descreve suas capacidades específicas.
Os modos de acesso são:
ReadWriteOnce -- o volume pode ser montado como leitura-escrita por um nó único
ReadOnlyMany -- o volume pode ser montado como somente-leitura por vários nós
ReadWriteMany -- o volume pode ser montado como leitura-escrita por vários nós
Na linha de comando, os modos de acesso ficam abreviados:
RWO - ReadWriteOnce
ROX - ReadOnlyMany
RWX - ReadWriteMany
Importante! Um volume somente pode ser montado utilizando um único modo de acesso por vez, independente se ele suportar mais de um. Por exemplo, um GCEPersistentDisk pode ser montado como ReadWriteOnce por um único nó ou ReadOnlyMany por vários nós, porém não simultaneamente.
Plugin de Volume
ReadWriteOnce
ReadOnlyMany
ReadWriteMany
AWSElasticBlockStore
✓
-
-
AzureFile
✓
✓
✓
AzureDisk
✓
-
-
CephFS
✓
✓
✓
Cinder
✓
-
-
CSI
depende do driver
depende do driver
depende do driver
FC
✓
✓
-
FlexVolume
✓
✓
depende do driver
Flocker
✓
-
-
GCEPersistentDisk
✓
✓
-
Glusterfs
✓
✓
✓
HostPath
✓
-
-
iSCSI
✓
✓
-
Quobyte
✓
✓
✓
NFS
✓
✓
✓
RBD
✓
✓
-
VsphereVolume
✓
-
(funcionam quando os Pods são do tipo collocated)
PortworxVolume
✓
-
✓
ScaleIO
✓
✓
-
StorageOS
✓
-
-
Classe
Um PV pode ter uma classe, que é especificada na configuração do atributo storageClassName com o nome da StorageClass. Um PV de uma classe específica só pode ser atrelado a requisições PVCs dessa mesma classe. Um PV sem storageClassName não possui nenhuma classe e pode ser montado somente a PVCs que não solicitem nenhuma classe em específico.
No passado, a notação volume.beta.kubernetes.io/storage-class era utilizada no lugar do atributo storageClassName. Essa notação ainda funciona. Contudo, ela será totalmente depreciada numa futura versão do Kubernetes.
Política de Retenção
Atualmente as políticas de retenção são:
Retain -- recuperação manual
Recycle -- limpeza básica (rm -rf /thevolume/*)
Delete -- o volume de armazenamento associado, como AWS EBS, GCE PD, Azure Disk ou OpenStack Cinder é deletado
Atualmente, somente NFS e HostPath suportam reciclagem. Volumes AWS EBS, GCE PD, Azure Disk e Cinder suportam delete.
Opções de Montagem
Um administrador do Kubernetes pode especificar opções de montagem adicionais quando um Volume Persistente é montado num nó.
Nota: Nem todos os tipos de Volume Persistente suportam opções de montagem.
Seguem os tipos de volumes que suportam opções de montagem.
AWSElasticBlockStore
AzureDisk
AzureFile
CephFS
Cinder (OpenStack block storage)
GCEPersistentDisk
Glusterfs
NFS
Quobyte Volumes
RBD (Ceph Block Device)
StorageOS
VsphereVolume
iSCSI
Não há validação em relação às opções de montagem. A montagem irá falhar se houver alguma opção inválida.
No passado, a notação volume.beta.kubernetes.io/mount-options era usada no lugar do atributo mountOptions. Essa notação ainda funciona. Contudo, ela será totalmente depreciada numa futura versão do Kubernetes.
Afinidade de Nó
Nota: Para a maioria dos tipos de volume, a configuração desse campo não se faz necessária. Isso é automaticamente populado pelos seguintes volumes de bloco do tipo: AWS EBS, GCE PD e Azure Disk. Você precisa deixar isso configurado para volumes do tipo local.
Um PV pode especificar uma afinidade de nó para definir restrições em relação ao limite de nós que podem acessar esse volume. Pods que utilizam um PV serão somente reservados para nós selecionados pela afinidade de nó.
Estado
Um volume sempre estará em um dos seguintes estados:
Available -- um recurso que está livre e ainda não foi atrelado a nenhuma requisição
Bound -- um volume atrelado a uma requisição
Released -- a requisição foi deletada, mas o curso ainda não foi recuperado pelo cluster
Failed -- o volume fracassou na sua recuperação automática
A CLI mostrará o nome do PV que foi atrelado à PVC
PersistentVolumeClaims
Cada PVC contém uma spec e um status, que é a especificação e estado de uma requisição. O nome de um objeto PersistentVolumeClaim precisa ser um DNS válido.
apiVersion:v1kind:PersistentVolumeClaimmetadata:name:myclaimspec:accessModes:- ReadWriteOncevolumeMode:Filesystemresources:requests:storage:8GistorageClassName:slowselector:matchLabels:release:"stable"matchExpressions:- {key: environment, operator: In, values:[dev]}
Modos de Acesso
As requisições usam as mesmas convenções que os volumes quando eles solicitam um armazenamento com um modo de acesso específico.
Modos de Volume
As requisições usam as mesmas convenções que os volumes quando eles indicam o tipo de volume, seja ele um sistema de arquivo ou dispositivo de bloco.
Recursos
Assim como Pods, as requisições podem solicitar quantidades específicas de recurso. Neste caso, a solicitação é por armazenamento. O mesmo modelo de recurso vale para volumes e requisições.
Seletor
Requisições podem especifiar um seletor de rótulo para posteriormente filtrar um grupo de volumes. Somente os volumes que possuam rótulos que satisfaçam os critérios do seletor podem ser atrelados à requisição. O seletor pode conter dois campos:
matchLabels - o volume deve ter um rótulo com esse valor
matchExpressions - uma lista de requisitos, como chave, lista de valores e operador relacionado aos valores e chaves. São operadores válidos: In, NotIn, Exists e DoesNotExist.
Todos os requisitos de matchLabels e matchExpressions, são do tipo AND - todos eles juntos devem ser atendidos.
Classe
Uma requisição pode solicitar uma classe específica através da StorageClass utilizando o atributo storageClassName. Neste caso o bind ocorrerá somente com os PVs que possuírem a mesma classe do storageClassName dos PVCs.
As PVCs não precisam necessariamente solicitar uma classe. Uma PVC com sua storageClassName configurada como "" sempre solicitará um PV sem classe, dessa forma ela sempre será atrelada a um PV sem classe (que não tenha nenhuma notação, ou seja, igual a ""). Uma PVC sem storageClassName não é a mesma coisa e será tratada pelo cluster de forma diferente, porém isso dependerá se o puglin de admissãoDefaultStorageClass estiver habilitado.
Se o plugin de admissão estiver habilitado, o administrador poderá especificar a StorageClass padrão. Todas as PVCs que não tiverem storageClassName podem ser atreladas somente a PVs que atendam a esse padrão. A especificação de uma StorageClass padrão é feita através da notação storageclass.kubernetes.io/is-default-class recebendo o valor true no objeto da StorageClass. Se o administrador não especificar nenhum padrão, o cluster vai tratar a criação de uma PVC como se o plugin de admissão estivesse desabilitado. Se mais de um valor padrão for especificado, o plugin de admissão proíbe a criação de todas as PVCs.
Se o plugin de admissão estiver desabilitado, não haverá nenhuma notação para a StorageClass padrão. Todas as PVCs que não tiverem storageClassName poderão ser atreladas somente aos PVs que não possuem classe. Neste caso, as PVCs que não tiverem storageClassName são tratadas da mesma forma como as PVCs que possuem suas storageClassName configuradas como "".
Dependendo do modo de instalação, uma StorageClass padrão pode ser implantada num cluster Kubernetes durante a instalação pelo addon manager.
Quando uma PVC especifica um selector para solicitar uma StorageClass, os requisitos são do tipo AND: somente um PV com a classe solicitada e com o rótulo requisitado pode ser atrelado à PVC.
Nota: Atualmente, uma PVC que tenha selector não pode ter um PV dinamicamente provisionado.
No passado, a notação volume.beta.kubernetes.io/storage-class era usada no lugar do atributo storageClassName Essa notação ainda funciona. Contudo, ela será totalmente depreciada numa futura versão do Kubernetes.
Requisições como Volumes
Os Pods podem ter acesso ao armazenamento utilizando a requisição como um volume. Para isso, a requisição tem que estar no mesmo namespace que o Pod. Ao localizar a requisição no namespace do Pod, o cluster passa o PersistentVolume para a requisição.
Os binds dos PersistentVolumes são exclusivos e, desde que as PersistentVolumeClaims são objetos do namespace, fazer a montagem das requisições com "Muitos" nós (ROX, RWX) é possível somente para um namespace.
PersistentVolumes do tipo hostPath
Um PersistentVolume do tipo hostPath utiliza um arquivo ou diretório no nó para emular um network-attached storage (NAS). Veja um exemplo de volume do tipo hostPath.
Suporte a Volume de Bloco Bruto
FEATURE STATE:Kubernetes v1.18 [stable]
Os plugins de volume abaixo suportam volumes de bloco bruto, incluindo provisionamento dinâmico onde for aplicável:
AWSElasticBlockStore
AzureDisk
CSI
FC (Fibre Channel)
GCEPersistentDisk
iSCSI
Local volume
OpenStack Cinder
RBD (Ceph Block Device)
VsphereVolume
Utilização de PersistentVolume com Volume de Bloco Bruto
Nota: Quando adicionar um dispositivo de bloco bruto num Pod, você especifica o caminho do dispositivo no contêiner ao invés de um ponto de montagem.
Bind de Volumes de Bloco
Se um usuário solicita um volume de bloco bruto através do campo volumeMode na spec da PersistentVolumeClaim, as regras de bind agora têm uma pequena diferença em relação às versões anteriores que não consideravam esse modo como parte da spec.
A tabela abaixo mostra as possíveis combinações que um usuário e um administrador pode especificar para requisitar um dispositivo de bloco bruto. A tabela indica se o volume será ou não atrelado com base nas combinações:
Matriz de bind de volume para provisionamento estático de volumes:
PV volumeMode
PVC volumeMode
Result
unspecified
unspecified
BIND
unspecified
Block
NO BIND
unspecified
Filesystem
BIND
Block
unspecified
NO BIND
Block
Block
BIND
Block
Filesystem
NO BIND
Filesystem
Filesystem
BIND
Filesystem
Block
NO BIND
Filesystem
unspecified
BIND
Nota: O provisionamento estático de volumes é suportado somente na versão alpha. Os administradores devem tomar cuidado ao considerar esses valores quando estiverem trabalhando com dispositivos de bloco bruto.
Snapshot de Volume e Restauração de Volume a partir de um Snapshot
FEATURE STATE:Kubernetes v1.20 [stable]
O snapshot de volume é suportado somente pelo plugin de volume CSI. Veja Snapshot de Volume para mais detalhes.
Plugins de volume in-tree estão depreciados. Você pode consultar sobre os plugins de volume depreciados em Perguntas Frequentes sobre Plugins de Volume.
Criar uma PersistentVolumeClaim a partir de um Snapshot de Volume
Se você está criando templates ou exemplos que rodam numa grande quantidade de clusters e que precisam de armazenamento persistente, recomendamos que utilize o padrão abaixo:
Inclua objetos PersistentVolumeClaim em seu pacote de configuração (com Deployments, ConfigMaps, etc.).
Não inclua objetos PersistentVolume na configuração, pois o usuário que irá instanciar a configuração talvez não tenha permissão para criar PersistentVolume.
Dê ao usuário a opção dele informar o nome de uma classe de armazenamento quando instanciar o template.
Se o usuário informar o nome de uma classe de armazenamento, coloque esse valor no campo persistentVolumeClaim.storageClassName. Isso fará com que a PVC encontre a classe de armazenamento correta se o cluster tiver a StorageClasses habilitado pelo administrador.
Se o usuário não informar o nome da classe de armazenamento, deixe o campo persistentVolumeClaim.storageClassName sem nenhum valor (vazio). Isso fará com que o PV seja provisionado automaticamente no cluster para o usuário com o StorageClass padrão. Muitos ambientes de cluster já possuem uma StorageClass padrão, ou então os administradores podem criar suas StorageClass de acordo com seus critérios.
Durante suas tarefas de administração, busque por PVCs que após um tempo não estão sendo atreladas, pois, isso talvez indique que o cluster não tem provisionamento dinâmico (onde o usuário deveria criar um PV que satisfaça os critérios da PVC) ou cluster não tem um sistema de armazenamento (onde usuário não pode realizar um deploy solicitando PVCs).
Este documento cataloga os caminhos de comunicação entre o control plane (o
apiserver) e o cluster Kubernetes. A intenção é permitir que os usuários
personalizem sua instalação para proteger a configuração de rede
então o cluster pode ser executado em uma rede não confiável (ou em IPs totalmente públicos em um
provedor de nuvem).
Nó para o Control Plane
Todos os caminhos de comunicação do cluster para o control plane terminam no
apiserver (nenhum dos outros componentes do control plane são projetados para expor
Serviços remotos). Em uma implantação típica, o apiserver é configurado para escutar
conexões remotas em uma porta HTTPS segura (443) com uma ou mais clientes autenticação habilitado.
Uma ou mais formas de autorização
deve ser habilitado, especialmente se requisições anônimas
ou tokens da conta de serviço
são autorizados.
Os nós devem ser provisionados com o certificado root público para o cluster
de tal forma que eles podem se conectar de forma segura ao apiserver junto com o cliente válido
credenciais. Por exemplo, em uma implantação padrão do GKE, as credenciais do cliente
fornecidos para o kubelet estão na forma de um certificado de cliente. Vejo
bootstrapping TLS do kubelet
para provisionamento automatizado de certificados de cliente kubelet.
Os pods que desejam se conectar ao apiserver podem fazê-lo com segurança, aproveitando
conta de serviço para que o Kubernetes injetará automaticamente o certificado raiz público
certificado e um token de portador válido no pod quando ele é instanciado.
O serviço kubernetes (no namespace default) é configurado com um IP virtual
endereço que é redirecionado (via kube-proxy) para o endpoint com HTTPS no
apiserver.
Os componentes do control plane também se comunicam com o apiserver do cluster através da porta segura.
Como resultado, o modo de operação padrão para conexões do cluster
(nodes e pods em execução nos Nodes) para o control plane é protegido por padrão
e pode passar por redes não confiáveis e/ou públicas.
Control Plane para o nó
Existem dois caminhos de comunicação primários do control plane (apiserver) para os nós.
O primeiro é do apiserver para o processo do kubelet que é executado em
cada nó no cluster. O segundo é do apiserver para qualquer nó, pod,
ou serviço através da funcionalidade de proxy do apiserver.
apiserver para o kubelet
As conexões do apiserver ao kubelet são usadas para:
Buscar logs para pods.
Anexar (através de kubectl) pods em execução.
Fornecer a funcionalidade de encaminhamento de porta do kubelet.
Essas conexões terminam no endpoint HTTPS do kubelet. Por padrão,
o apiserver não verifica o certificado de serviço do kubelet,
o que torna a conexão sujeita a ataques man-in-the-middle, o que o torna
inseguro para passar por redes não confiáveis e / ou públicas.
Para verificar essa conexão, use a flag --kubelet-certificate-authority para
fornecer o apiserver com um pacote de certificado raiz para usar e verificar o
certificado de serviço da kubelet.
Se isso não for possível, use o SSH túnel
entre o apiserver e kubelet se necessário para evitar a conexão ao longo de um
rede não confiável ou pública.
As conexões a partir do apiserver para um nó, pod ou serviço padrão para simples
conexões HTTP não são autenticadas nem criptografadas. Eles
podem ser executados em uma conexão HTTPS segura prefixando https: no nó,
pod, ou nome do serviço no URL da API, mas eles não validarão o certificado
fornecido pelo ponto de extremidade HTTPS, nem fornece credenciais de cliente, enquanto
a conexão será criptografada, não fornecerá nenhuma garantia de integridade.
Estas conexões não são atualmente seguras para serem usados por redes não confiáveis e/ou públicas.
SSH Túnel
O Kubernetes suporta túneis SSH para proteger os caminhos de comunicação do control plane para os nós. Nesta configuração, o apiserver inicia um túnel SSH para cada nó
no cluster (conectando ao servidor ssh escutando na porta 22) e passa
todo o tráfego destinado a um kubelet, nó, pod ou serviço através do túnel.
Este túnel garante que o tráfego não seja exposto fora da rede aos quais
os nós estão sendo executados.
Atualmente, os túneis SSH estão obsoletos, portanto, você não deve optar por usá-los, a menos que saiba o que está fazendo. O serviço Konnectivity é um substituto para este canal de comunicação.
Konnectivity service
FEATURE STATE:Kubernetes v1.18 [beta]
Como uma substituição aos túneis SSH, o serviço Konnectivity fornece proxy de nível TCP para a comunicação do control plane para o cluster. O serviço Konnectivity consiste em duas partes: o servidor Konnectivity na rede control plane e os agentes Konnectivity na rede dos nós. Os agentes Konnectivity iniciam conexões com o servidor Konnectivity e mantêm as conexões de rede. Depois de habilitar o serviço Konnectivity, todo o tráfego do control plane para os nós passa por essas conexões.
O conceito do Cloud Controller Manager (CCM) (não confundir com o binário) foi originalmente criado para permitir que o código específico de provedor de nuvem e o núcleo do Kubernetes evoluíssem independentemente um do outro. O Cloud Controller Manager é executado junto com outros componentes principais, como o Kubernetes controller manager, o servidor de API e o scheduler. Também pode ser iniciado como um addon do Kubernetes, caso em que é executado em cima do Kubernetes.
O design do Cloud Controller Manager é baseado em um mecanismo de plug-in que permite que novos provedores de nuvem se integrem facilmente ao Kubernetes usando plug-ins. Existem planos para integrar novos provedores de nuvem no Kubernetes e para migrar provedores de nuvem que estão utilizando o modelo antigo para o novo modelo de CCM.
Este documento discute os conceitos por trás do Cloud Controller Manager e fornece detalhes sobre suas funções associadas.
Aqui está a arquitetura de um cluster Kubernetes sem o Cloud Controller Manager:
Projeto de Arquitetura (Design)
No diagrama anterior, o Kubernetes e o provedor de nuvem são integrados através de vários componentes diferentes:
Kubelet
Kubernetes controller manager
Kubernetes API server
O CCM consolida toda a lógica que depende da nuvem dos três componentes anteriores para criar um único ponto de integração com a nuvem. A nova arquitetura com o CCM se parece com isso:
Componentes do CCM
O CCM separa algumas das funcionalidades do KCM (Kubernetes Controller Manager) e o executa como um processo separado. Especificamente, isso elimina os controladores no KCM que dependem da nuvem. O KCM tem os seguintes loops de controlador dependentes de nuvem:
Node controller
Volume controller
Route controller
Service controller
Na versão 1.9, o CCM executa os seguintes controladores da lista anterior:
Node controller
Route controller
Service controller
Nota: O Volume Controller foi deliberadamente escolhido para não fazer parte do CCM. Devido à complexidade envolvida e devido aos esforços existentes para abstrair a lógica de volume específica do fornecedor, foi decidido que o Volume Controller não será movido para o CCM.
O plano original para suportar volumes usando o CCM era usar volumes Flex para suportar volumes plugáveis. No entanto, um esforço concorrente conhecido como CSI está sendo planejado para substituir o Flex.
Considerando essas dinâmicas, decidimos ter uma medida de intervalo intermediário até que o CSI esteja pronto.
Funções do CCM
O CCM herda suas funções de componentes do Kubernetes que são dependentes de um provedor de nuvem. Esta seção é estruturada com base nesses componentes.
1. Kubernetes Controller Manager
A maioria das funções do CCM é derivada do KCM. Conforme mencionado na seção anterior, o CCM executa os seguintes ciclos de controle:
Node Controller
Route Controller
Service Controller
Node Controller
O Node Controller é responsável por inicializar um nó obtendo informações sobre os nós em execução no cluster do provedor de nuvem. O Node Controller executa as seguintes funções:
Inicializar um node com labels de região/zona específicos para a nuvem.
Inicialize um node com detalhes de instância específicos da nuvem, por exemplo, tipo e tamanho.
Obtenha os endereços de rede e o nome do host do node.
No caso de um node não responder, verifique a nuvem para ver se o node foi excluído da nuvem.
Se o node foi excluído da nuvem, exclua o objeto Node do Kubernetes.
Route Controller
O Route Controller é responsável por configurar as rotas na nuvem apropriadamente, de modo que os contêineres em diferentes nodes no cluster do Kubernetes possam se comunicar entre si. O Route Controller é aplicável apenas para clusters do Google Compute Engine.
Service controller
O Service controller é responsável por ouvir os eventos de criação, atualização e exclusão do serviço. Com base no estado atual dos serviços no Kubernetes, ele configura os balanceadores de carga da nuvem (como o ELB, o Google LB ou o Oracle Cloud Infrastrucutre LB) para refletir o estado dos serviços no Kubernetes. Além disso, garante que os back-ends de serviço para balanceadores de carga da nuvem estejam atualizados.
2. Kubelet
O Node Controller contém a funcionalidade dependente da nuvem do kubelet. Antes da introdução do CCM, o kubelet era responsável por inicializar um nó com detalhes específicos da nuvem, como endereços IP, rótulos de região / zona e informações de tipo de instância. A introdução do CCM mudou esta operação de inicialização do kubelet para o CCM.
Nesse novo modelo, o kubelet inicializa um nó sem informações específicas da nuvem. No entanto, ele adiciona uma marca (taint) ao nó recém-criado que torna o nó não programável até que o CCM inicialize o nó com informações específicas da nuvem. Em seguida, remove essa mancha (taint).
Mecanismo de plugins
O Cloud Controller Manager usa interfaces Go para permitir implementações de qualquer nuvem a ser conectada. Especificamente, ele usa a Interface CloudProvider definidaaqui.
A implementação dos quatro controladores compartilhados destacados acima, e algumas estruturas que ficam junto com a interface compartilhada do provedor de nuvem, permanecerão no núcleo do Kubernetes. Implementações específicas para provedores de nuvem serão construídas fora do núcleo e implementarão interfaces definidas no núcleo.
Esta seção divide o acesso necessário em vários objetos da API pelo CCM para executar suas operações.
Node Controller
O Node Controller só funciona com objetos Node. Ele requer acesso total para obter, listar, criar, atualizar, corrigir, assistir e excluir objetos Node.
v1/Node:
Get
List
Create
Update
Patch
Watch
Delete
Rote Controller
O Rote Controller escuta a criação do objeto Node e configura as rotas apropriadamente. Isso requer acesso a objetos Node.
v1/Node:
Get
Service Controller
O Service Controller escuta eventos de criação, atualização e exclusão de objeto de serviço e, em seguida, configura pontos de extremidade para esses serviços de forma apropriada.
Para acessar os Serviços, é necessário listar e monitorar o acesso. Para atualizar os Serviços, ele requer patch e atualização de acesso.
Para configurar endpoints para os Serviços, é necessário acesso para criar, listar, obter, assistir e atualizar.
v1/Service:
List
Get
Watch
Patch
Update
Outros
A implementação do núcleo do CCM requer acesso para criar eventos e, para garantir a operação segura, requer acesso para criar ServiceAccounts.
Voce vai encontrar instruções completas para configurar e executar o CCM
aqui.
3.3.3 - Controladores
Em robótica e automação um control loop, ou em português ciclo de controle, é
um ciclo não terminado que regula o estado de um sistema.
Um exemplo de ciclo de controle é um termostato de uma sala.
Quando você define a temperatura, isso indica ao termostato
sobre o seu estado desejado. A temperatura ambiente real é o
estado atual. O termostato atua de forma a trazer o estado atual
mais perto do estado desejado, ligando ou desligando o equipamento.
No Kubernetes, controladores são ciclos de controle que observam o estado do seu
cluster, e então fazer ou requisitar
mudanças onde necessário.
Cada controlador tenta mover o estado atual do cluster mais perto do estado desejado.
Padrão Controlador (Controller pattern)
Um controlador rastreia pelo menos um tipo de recurso Kubernetes.
Estes objetos
têm um campo spec que representa o estado desejado.
O(s) controlador(es) para aquele recurso são responsáveis por trazer o estado atual
mais perto do estado desejado.
O controlador pode executar uma ação ele próprio, ou,
o que é mais comum, no Kubernetes, o controlador envia uma mensagem para o
API server (servidor de API) que tem
efeitos colaterais úteis. Você vai ver exemplos disto abaixo.
Controlador via API server
O controlador Job é um exemplo de um
controlador Kubernetes embutido. Controladores embutidos gerem estados através da
interação com o cluster API server.
Job é um recurso do Kubernetes que é executado em um
Pod, ou talvez vários Pods, com o objetivo de
executar uma tarefa e depois parar.
(Uma vez agendado, objetos Pod passam a fazer parte
do estado desejado para um kubelet.
Quando o controlador Job observa uma nova tarefa ele garante que,
algures no seu cluster, os kubelets num conjunto de nós (Nodes) estão correndo o número
correto de Pods para completar o trabalho.
O controlador Job não corre Pods ou containers ele próprio.
Em vez disso, o controlador Job informa o API server para criar ou remover Pods.
Outros componentes do plano de controle
(control plane)
atuam na nova informação (existem novos Pods para serem agendados e executados),
e eventualmente o trabalho é feito.
Após ter criado um novo Job, o estado desejado é que esse Job seja completado.
O controlador Job faz com que o estado atual para esse Job esteja mais perto do seu
estado desejado: criando Pods que fazem o trabalho desejado para esse Job para que
o Job fique mais perto de ser completado.
Controladores também atualizam os objetos que os configuram.
Por exemplo: assim que o trabalho de um Job está completo,
o controlador Job atualiza esse objeto Job para o marcar como Finished (terminado).
(Isto é um pouco como alguns termostatos desligam uma luz para
indicar que a temperatura da sala está agora na temperatura que foi introduzida).
Controle direto
Em contraste com Job, alguns controladores necessitam de efetuar
mudanças fora do cluster.
Por exemplo, se usar um ciclo de controle para garantir que existem
Nodes suficientes
no seu cluster, então esse controlador necessita de algo exterior ao
cluster atual para configurar novos Nodes quando necessário.
Controladores que interagem com estados externos encontram o seu estado desejado
a partir do API server, e então comunicam diretamente com o sistema externo para
trazer o estado atual mais próximo do desejado.
Kubernetes tem uma visão cloud-native de sistemas e é capaz de manipular
mudanças constantes.
O seu cluster pode mudar em qualquer momento à medida que as ações acontecem e
os ciclos de controle corrigem falhas automaticamente. Isto significa que,
potencialmente, o seu cluster nunca atinge um estado estável.
Enquanto os controladores no seu cluster estiverem rodando e forem capazes de
fazer alterações úteis, não importa se o estado é estável ou se é instável.
Design
Como um princípio do seu desenho, o Kubernetes usa muitos controladores onde cada
um gerencia um aspecto particular do estado do cluster. Comumente, um particular
ciclo de controle (controlador) usa uma espécie de recurso como o seu estado desejado,
e tem uma espécie diferente de recurso que o mesmo gere para garantir que esse estado desejado
é cumprido.
É útil que haja controladores simples em vez de um conjunto monolítico de ciclos de controle
que estão interligados. Controladores podem falhar, então o Kubernetes foi desenhado para
permitir isso.
Por exemplo: um controlador de Jobs rastreia objetos Job (para
descobrir novos trabalhos) e objetos Pod (para correr o Jobs, e então
ver quando o trabalho termina). Neste caso outra coisa cria os Jobs,
enquanto o controlador Job cria Pods.
Nota:
Podem existir vários controladores que criam ou atualizam a mesma espécie (kind) de objeto.
Atrás das cortinas, os controladores do Kubernetes garantem que eles apenas tomam
atenção aos recursos ligados aos seus recursos controladores.
Por exemplo, você pode ter Deployments e Jobs; ambos criam Pods.
O controlador de Job não apaga os Pods que o seu Deployment criou,
porque existe informação (labels)
que os controladores podem usar para diferenciar esses Pods.
Formas de rodar controladores
O Kubernetes vem com um conjunto de controladores embutidos que correm
dentro do kube-controller-manager.
Estes controladores embutidos providenciam comportamentos centrais importantes.
O controlador Deployment e o controlador Job são exemplos de controladores
que veem como parte do próprio Kubernetes (controladores "embutidos").
O Kubernetes deixa você correr o plano de controle resiliente, para que se qualquer
um dos controladores embutidos falhar, outra parte do plano de controle assume
o trabalho.
Pode encontrar controladores fora do plano de controle, para extender o Kubernetes.
Ou, se quiser, pode escrever um novo controlador você mesmo.
Pode correr o seu próprio controlador como um conjunto de Pods,
ou externo ao Kubernetes. O que encaixa melhor vai depender no que esse
controlador faz em particular.
Tecnologia para empacotar aplicações com suas dependências em tempo de execução
Cada contêiner executado é repetível; a padronização de ter
dependências incluídas significa que você obtém o mesmo comportamento onde quer que você execute.
Os contêineres separam os aplicativos da infraestrutura de host subjacente.
Isso torna a implantação mais fácil em diferentes ambientes de nuvem ou sistema operacional.
Imagem de contêiner
Uma imagem de contêiner é um pacote de software pronto para executar, contendo tudo que é preciso para executar uma aplicação:
o código e o agente de execução necessário, aplicação, bibliotecas do sistema e valores padrões para qualquer configuração essencial.
Por design, um contêiner é imutável: você não pode mudar o código de um contêiner que já está executando. Se você tem uma aplicação conteinerizada e quer fazer mudanças, você precisa construir uma nova imagem que inclui a mudança, e recriar o contêiner para iniciar a partir da imagem atualizada.
Agente de execução de contêiner
O agente de execução (runtime) de contêiner é o software responsável por executar os contêineres.
Uma imagem de contêiner representa dados binários que encapsulam uma aplicação e todas as suas dependências de software. As imagens de contêiner são pacotes de software executáveis que podem ser executados de forma autônoma e que fazem suposições muito bem definidas sobre seu agente de execução do ambiente.
Normalmente, você cria uma imagem de contêiner da sua aplicação e a envia para um registro antes de fazer referência a ela em um Pod
Esta página fornece um resumo sobre o conceito de imagem de contêiner.
Nomes das imagens
As imagens de contêiner geralmente recebem um nome como pause, exemplo/meuconteiner, ou kube-apiserver.
As imagens também podem incluir um hostname de algum registro; por exemplo: exemplo.registro.ficticio/nomeimagem,
e um possível número de porta; por exemplo: exemplo.registro.ficticio:10443/nomeimagem.
Se você não especificar um hostname de registro, o Kubernetes presumirá que você se refere ao registro público do Docker.
Após a parte do nome da imagem, você pode adicionar uma tag (como também usar com comandos como docker e podman).
As tags permitem identificar diferentes versões da mesma série de imagens.
Tags de imagem consistem em letras maiúsculas e minúsculas, dígitos, sublinhados (_),
pontos (.) e travessões ( -).
Existem regras adicionais sobre onde você pode colocar o separador
caracteres (_,- e .) dentro de uma tag de imagem.
Se você não especificar uma tag, o Kubernetes presumirá que você se refere à tag latest (mais recente).
Cuidado:
Você deve evitar usar a tag latest quando estiver realizando o deploy de contêineres em produção,
pois é mais difícil rastrear qual versão da imagem está sendo executada, além de tornar mais difícil o processo de reversão para uma versão funcional.
Em vez disso, especifique uma tag significativa, como v1.42.0.
Atualizando imagens
A política padrão de pull é IfNotPresent a qual faz com que o
kubelet ignore
o processo de pull da imagem, caso a mesma já exista. Se você prefere sempre forçar o processo de pull,
você pode seguir uma das opções abaixo:
defina a imagePullPolicy do contêiner para Always.
omita imagePullPolicy e use: latest como a tag para a imagem a ser usada.
omita o imagePullPolicy e a tag da imagem a ser usada.
Quando imagePullPolicy é definido sem um valor específico, ele também é definido como Always.
Multiarquitetura de imagens com índice de imagens
Além de fornecer o binário das imagens, um registro de contêiner também pode servir um índice de imagem do contêiner. Um índice de imagem pode apontar para múltiplos manifestos da imagem para versões específicas de arquitetura de um contêiner. A ideia é que você possa ter um nome para uma imagem (por exemplo: pause, exemple/meuconteiner, kube-apiserver) e permitir que diferentes sistemas busquem o binário da imagem correta para a arquitetura de máquina que estão usando.
O próprio Kubernetes normalmente nomeia as imagens de contêiner com o sufixo -$(ARCH). Para retrocompatibilidade, gere as imagens mais antigas com sufixos. A ideia é gerar a imagem pause que tem o manifesto para todas as arquiteturas e pause-amd64 que é retrocompatível com as configurações anteriores ou arquivos YAML que podem ter codificado as imagens com sufixos.
Usando um registro privado
Os registros privados podem exigir chaves para acessar as imagens deles.
As credenciais podem ser fornecidas de várias maneiras:
Configurando nós para autenticação em um registro privado
todos os pods podem ler qualquer registro privado configurado
requer configuração de nó pelo administrador do cluster
Imagens pré-obtidas
todos os pods podem usar qualquer imagem armazenada em cache em um nó
requer acesso root a todos os nós para configurar
Especificando ImagePullSecrets em um Pod
apenas pods que fornecem chaves próprias podem acessar o registro privado
Extensões locais ou específicas do fornecedor
se estiver usando uma configuração de nó personalizado, você (ou seu provedor de nuvem) pode implementar seu mecanismo para autenticar o nó ao registro do contêiner.
Essas opções são explicadas com mais detalhes abaixo.
Configurando nós para autenticação em um registro privado
Se você executar o Docker em seus nós, poderá configurar o contêiner runtime do Docker
para autenticação em um registro de contêiner privado.
Essa abordagem é adequada se você puder controlar a configuração do nó.
Nota: O Kubernetes padrão é compatível apenas com as seções auths e HttpHeaders na configuração do Docker.
Auxiliares de credencial do Docker (credHelpers ou credsStore) não são suportados.
Docker armazena chaves de registros privados no arquivo $HOME/.dockercfg ou $HOME/.docker/config.json. Se você colocar o mesmo arquivo na lista de caminhos de pesquisa abaixo, o kubelet o usa como provedor de credenciais ao obter imagens.
{--root-dir:-/var/lib/kubelet}/config.json
{cwd of kubelet}/config.json
${HOME}/.docker/config.json
/.docker/config.json
{--root-dir:-/var/lib/kubelet}/.dockercfg
{cwd of kubelet}/.dockercfg
${HOME}/.dockercfg
/.dockercfg
Nota: Você talvez tenha que definir HOME=/root explicitamente no ambiente do processo kubelet.
Aqui estão as etapas recomendadas para configurar seus nós para usar um registro privado. Neste
exemplo, execute-os em seu desktop/laptop:
Execute docker login [servidor] para cada conjunto de credenciais que deseja usar. Isso atualiza o $HOME/.docker/config.json em seu PC.
Visualize $HOME/.docker/config.json em um editor para garantir que contém apenas as credenciais que você deseja usar.
Obtenha uma lista de seus nós; por exemplo:
se você quiser os nomes: nodes=$( kubectl get nodes -o jsonpath='{range.items[*].metadata}{.name} {end}' )
se você deseja obter os endereços IP: nodes=$( kubectl get nodes -o jsonpath='{range .items[*].status.addresses[?(@.type=="ExternalIP")]}{.address} {end}' )
Copie seu .docker/config.json local para uma das listas de caminhos de busca acima.
por exemplo, para testar isso: for n in $nodes; do scp ~/.docker/config.json root@"$n":/var/lib/kubelet/config.json; done
Nota: Para clusters de produção, use uma ferramenta de gerenciamento de configuração para que você possa aplicar esta
configuração em todos os nós que você precisar.
Verifique se está funcionando criando um pod que usa uma imagem privada; por exemplo:
Fri, 26 Jun 2015 15:36:13 -0700 Fri, 26 Jun 2015 15:39:13 -0700 19 {kubelet node-i2hq} spec.containers{uses-private-image} failed Failed to pull image "user/privaterepo:v1": Error: image user/privaterepo:v1 not found
Você deve garantir que todos os nós no cluster tenham o mesmo .docker/config.json. Caso contrário, os pods serão executados com sucesso em alguns nós e falharão em outros. Por exemplo, se você usar o escalonamento automático de nós, cada modelo de instância precisa incluir o .docker/config.json ou montar um drive que o contenha.
Todos os pods terão premissão de leitura às imagens em qualquer registro privado, uma vez que
as chaves privadas do registro são adicionadas ao .docker/config.json.
Imagens pré-obtidas
Nota: Essa abordagem é adequada se você puder controlar a configuração do nó. Isto
não funcionará de forma confiável se o seu provedor de nuvem for responsável pelo gerenciamento de nós e os substituir
automaticamente.
Por padrão, o kubelet tenta realizar um "pull" para cada imagem do registro especificado.
No entanto, se a propriedade imagePullPolicy do contêiner for definida como IfNotPresent ou Never,
em seguida, uma imagem local é usada (preferencial ou exclusivamente, respectivamente).
Se você quiser usar imagens pré-obtidas como um substituto para a autenticação do registro,
você deve garantir que todos os nós no cluster tenham as mesmas imagens pré-obtidas.
Isso pode ser usado para pré-carregar certas imagens com o intuíto de aumentar a velocidade ou como uma alternativa para autenticação em um registro privado.
Todos os pods terão permissão de leitura a quaisquer imagens pré-obtidas.
Especificando imagePullSecrets em um pod
Nota: Esta é a abordagem recomendada para executar contêineres com base em imagens
de registros privados.
O Kubernetes oferece suporte à especificação de chaves de registro de imagem de contêiner em um pod.
Criando um segredo com Docker config
Execute o seguinte comando, substituindo as palavras em maiúsculas com os valores apropriados:
Isso é particularmente útil se você estiver usando vários registros privados de contêineres, como kubectl create secret docker-registry cria um Segredo que
só funciona com um único registro privado.
Nota: Os pods só podem fazer referência a pull secrets de imagem em seu próprio namespace,
portanto, esse processo precisa ser feito uma vez por namespace.
Referenciando um imagePullSecrets em um pod
Agora, você pode criar pods que fazem referência a esse segredo adicionando uma seção imagePullSecrets
na definição de Pod.
Você pode usar isso em conjunto com um .docker / config.json por nó. As credenciais
serão mescladas.
Casos de uso
Existem várias soluções para configurar registros privados. Aqui estão alguns
casos de uso comuns e soluções sugeridas.
Cluster executando apenas imagens não proprietárias (por exemplo, código aberto). Não há necessidade de ocultar imagens.
Use imagens públicas no Docker hub.
Nenhuma configuração necessária.
Alguns provedores de nuvem armazenam em cache ou espelham automaticamente imagens públicas, o que melhora a disponibilidade e reduz o tempo para extrair imagens.
Cluster executando algumas imagens proprietárias que devem ser ocultadas para quem está fora da empresa, mas
visível para todos os usuários do cluster.
Mova dados confidenciais para um recurso "secreto", em vez de empacotá-los em uma imagem.
Um cluster multilocatário em que cada locatário precisa de seu próprio registro privado.
Certifique-se de que o controlador de admissão AlwaysPullImages está ativo. Caso contrário, todos os Pods de todos os locatários terão potencialmente acesso a todas as imagens.
Execute um registro privado com autorização necessária.
Gere credenciais de registro para cada locatário, coloque em segredo e preencha o segredo para cada namespace de locatário.
O locatário adiciona esse segredo a imagePullSecrets de cada namespace.
Se precisar de acesso a vários registros, você pode criar um segredo para cada registro.
O Kubelet mesclará qualquer imagePullSecrets em um único .docker/config.json virtual
Essa página descreve os recursos disponíveis para contêineres no ambiente de contêiner.
Ambiente de contêiner
O ambiente de contêiner do Kubernetes fornece recursos importantes para contêineres:
Um sistema de arquivos, que é a combinação de uma imagem e um ou mais volumes.
Informação sobre o contêiner propriamente.
Informação sobre outros objetos no cluster.
Informação de contêiner
O hostname de um contêiner é o nome do Pod em que o contêiner está executando.
Isso é disponibilizado através do comando hostname ou da função gethostname chamada na libc.
O nome do Pod e o Namespace são expostos como variáveis de ambiente através de um mecanismo chamado downward API.
Variáveis de ambiente definidas pelo usuário a partir da definição do Pod também são disponíveis para o contêiner, assim como qualquer variável de ambiente especificada estáticamente na imagem Docker.
Informação do cluster
Uma lista de todos os serviços que estão executando quando um contêiner foi criado é disponibilizada para o contêiner como variáveis de ambiente.
Essas variáveis de ambiente são compatíveis com a funcionalidade docker link do Docker.
Para um serviço nomeado foo que mapeia para um contêiner nomeado bar, as seguintes variáveis são definidas:
FOO_SERVICE_HOST=<o host em que o serviço está executando>
FOO_SERVICE_PORT=<a porta em que o serviço está executando>
Serviços possuem endereço IP dedicado e são disponibilizados para o contêiner via DNS,
se possuírem DNS addon habilitado.
Essa página descreve o recurso RuntimeClass e a seleção do mecanismo do agente de execução.
RuntimeClass é uma funcionalidade para selecionar as configurações do agente de execução do contêiner.
A configuração do agente de execução de contêineres é usada para executar os contêineres de um Pod.
Motivação
Você pode configurar um RuntimeClass diferente entre os diferentes Pods para prover
um equilíbrio entre performance versus segurança. Por exemplo, se parte de sua carga de
trabalho necessita de um alto nível de garantia de segurança da informação, você pode
optar em executar esses Pods em um agente de execução que usa virtualização de hardware.
Você então terá o benefício do isolamento extra de um agente de execução alternativo, ao
custo de uma latência adicional.
Você pode ainda usar um RuntimeClass para executar diferentes Pods com o mesmo agente
de execução de contêineres mas com diferentes configurações.
Configuração
Configure a implementação do CRI nos nós (depende do agente de execução)
Crie o recurso RuntimeClass correspondente.
1. Configure a implementação do CRI nos nós
As configurações disponíveis através do RuntimeClass sáo dependentes da implementação do
Container Runtime Interface (Container runtime interface (CRI)). Veja a documentação correspondente abaixo para a
sua implementação CRI para verificar como configurar.
Nota: RuntimeClass assume uma configuração homogênea de nós entre todo o cluster por padrão
(o que significa que todos os nós estão configurados do mesmo jeito referente aos agentes de
execução). Para suportar configurações heterogêneas, veja Associação abaixo.
As configurações possuem um nome handler correspondente, referenciado pelo RuntimeClass.
Esse nome deve ser um valor DNS 1123 válido (letras, números e o carácter -).
2. Crie o recurso RuntimeClass correspondente
As etapas de configuração no passo 1 devem todas estar associadas a um nome para o campo handler
que identifica a configuração. Para cada um, crie o objeto RuntimeClass correspondente.
O recurso RuntimeClass atualmente possui apenas 2 campos significativos: o nome do RuntimeClass
(metadata.name) e o agente (handler). A definição do objeto se parece conforme a seguir:
apiVersion:node.k8s.io/v1 # RuntimeClass é definido no grupo de API node.k8s.iokind:RuntimeClassmetadata:name:myclass # O nome que o RuntimeClass será chamado como# RuntimeClass é um recurso global, e não possui namespace.handler:myconfiguration # Nome da configuração CRI correspondente
Nota: É recomendado que operações de escrita no objeto RuntimeClass (criar/atualizar/patch/apagar)
sejam restritas a administradores do cluster. Isso geralmente é o padrão. Veja Visão Geral
de autorizações para maiores detalhes.
Uso
Uma vez que as classes de execução estão configuradas no cluster, usar elas é relativamente
simples. Especifique um runtimeClassName na especificação do Pod. Por exemplo:
Isso irá instruir o kubelet a usar o RuntimeClass nomeado acima (myclass) para esse Pod. Se
o nome do RuntimeClass não existir, ou o CRI não puder executar a solicitação, o Pod entrará na fase
finalFailed. Procure por um
evento correspondente
para uma mensagem de erro.
Se nenhum runtimeClassName for especificado, o RuntimeHandler padrão será utilizado, que é equivalente
ao comportamento quando a funcionalidade de RuntimeClass está desativada.
Configuração do CRI
Para maiores detalhes de configuração dos agentes de execução CRI, veja instalação do CRI.
dockershim
O CRI dockershim embutido no Kubernetes não suporta outros agentes de execução.
Agentes de execução são configurados através da configuração do containerd em
/etc/containerd/config.toml. Agentes válidos são configurados sob a seção de runtimes:
Agentes de execução são configurados através da configuração do CRI-O em /etc/crio/crio.conf.
Agentes válidos são configurados na seção crio.runtime
table:
Ao especificar o campo scheduling para um RuntimeClass, você pode colocar limites e
garantir que os Pods executando dentro de uma RuntimeClass sejam associados a nós que
suportem eles. Se o scheduling não estiver configurado, assume-se que esse RuntimeClass
é suportado por todos os nós.
Para garantir que os Pods sejam executados em um nó que suporte um RuntimeClass específico,
aquele conjunto de nós deve possuir uma marca/label padrão que é selecionado pelo campo
runtimeclass.scheduling.nodeSelector. O nodeSelector do RuntimeClass é combinado com o
nodeSelector do Pod em tempo de admissão, obtendo a intersecção do conjunto de nós selecionado
por cada. Se existir um conflito, o pod será rejeitado.
Se os nós suportados possuírem marcação de restrição para prevenir outros Pods com uma
classe de execução diferente de executar no nó, você pode adicionar o campo tolerations
ao objeto RuntimeClass. Assim como com o nodeSelector, o tolerations é combinado com
o campo tolerations do Pod em tempo de admissão, efetivamente pegando a intersecção do
conjunto de nós aplicáveis para cada.
Para saber mais sobre a configuração de seleção de nós e tolerâncias, veja Associando Pods a
Nós.
Sobrecarga de Pods
FEATURE STATE:Kubernetes v1.18 [beta]
Você pode especificar os recursos extra que estão associados à execução de um Pod. Declarar esses
recursos extra permite ao cluster (incluindo o agendador/scheduler de pods) contabilizar por
esses recursos quando estiver decidindo sobre Pods e recursos. Para usar a contabilização
desses recursos extras, você deve estar com o feature gate
PodOverhead habilitado (ele já está habilitado por padrão).
Os recursos extras utilizados são especificados no objeto RuntimeClass através do campo overhead.
Ao usar esses campos, você especifica o uso extra de recursos necessários para executar
Pods utilizando-se desse Runtimeclass e assim contabilizar esses recursos para o Kubernetes.
Essa página descreve como os contêineres gerenciados pelo kubelet podem usar a estrutura de hook de ciclo de vida do contêiner para executar código acionado por eventos durante seu ciclo de vida de gerenciamento.
Visão Geral
Análogo a muitas estruturas de linguagem de programação que tem hooks de ciclo de vida de componentes, como angular,
o Kubernetes fornece aos contêineres hooks de ciclo de vida.
Os hooks permitem que os contêineres estejam cientes dos eventos em seu ciclo de vida de gerenciamento
e executem código implementado em um manipulador quando o hook de ciclo de vida correspondente é executado.
Hooks do contêiner
Existem dois hooks que são expostos para os contêiners:
PostStart
Este hook é executado imediatamente após um contêiner ser criado.
Entretanto, não há garantia que o hook será executado antes do ENTRYPOINT do contêiner.
Nenhum parâmetro é passado para o manipulador.
PreStop
Esse hook é chamado imediatamente antes de um contêiner ser encerrado devido a uma solicitação de API ou um gerenciamento de evento como liveness/startup probe failure, preemption, resource contention e outros.
Uma chamada ao hookPreStop falha se o contêiner já está em um estado finalizado ou concluído e o hook deve ser concluído antes que o sinal TERM seja enviado para parar o contêiner. A contagem regressiva do período de tolerância de término do Pod começa antes que o hookPreStop seja executado, portanto, independentemente do resultado do manipulador, o contêiner será encerrado dentro do período de tolerância de encerramento do Pod. Nenhum parâmetro é passado para o manipulador.
Uma descrição mais detalhada do comportamento de término pode ser encontrada em Término de Pods.
Implementações de manipulador de hook
Os contêineres podem acessar um hook implementando e registrando um manipulador para esse hook.
Existem dois tipos de manipuladores de hooks que podem ser implementados para contêineres:
Exec - Executa um comando específico, como pre-stop.sh, dentro dos cgroups e Namespaces do contêiner.
HTTP - Executa uma requisição HTTP em um endpoint específico do contêiner.
Execução do manipulador de hook
Quando um hook de gerenciamento de ciclo de vida do contêiner é chamado, o sistema de gerenciamento do Kubernetes executa o manipulador de acordo com a ação do hook, httpGet e tcpSocket são executados pelo processo kubelet e exec é executado pelo contêiner.
As chamadas do manipulador do hook são síncronas no contexto do Pod que contém o contêiner.
Isso significa que para um hookPostStart, o ENTRYPOINT do contêiner e o hook disparam de forma assíncrona.
No entanto, se o hook demorar muito para ser executado ou travar, o contêiner não consegue atingir o estado running.
Os hooksPreStop não são executados de forma assíncrona a partir do sinal para parar o contêiner, o hook precisa finalizar a sua execução antes que o sinal TERM possa ser enviado.
Se um hookPreStop travar durante a execução, a fase do Pod será Terminating e permanecerá até que o Pod seja morto após seu terminationGracePeriodSeconds expirar. Esse período de tolerância se aplica ao tempo total necessário
para o hookPreStopexecutar e para o contêiner parar normalmente.
Se por exemplo, o terminationGracePeriodSeconds é 60, e o hook leva 55 segundos para ser concluído, e o contêiner leva 10 segundos para parar normalmente após receber o sinal, então o contêiner será morto antes que possa parar
normalmente, uma vez que o terminationGracePeriodSeconds é menor que o tempo total (55 + 10) que é necessário para que essas duas coisas aconteçam.
Se um hookPostStart ou PreStop falhar, ele mata o contêiner.
Os usuários devem tornar seus hooks o mais leve possíveis.
Há casos, no entanto, em que comandos de longa duração fazem sentido, como ao salvar o estado
antes de parar um contêiner.
Garantias de entrega de hooks
A entrega do hook é destinada a acontecer pelo menos uma vez,
o que quer dizer que um hook pode ser chamado várias vezes para qualquer evento,
como para PostStart ou PreStop.
Depende da implementação do hook lidar com isso corretamente.
Geralmente, apenas entregas únicas são feitas.
Se, por exemplo, um receptor de hook HTTP estiver inativo e não puder receber tráfego,
não há tentativa de reenviar.
Em alguns casos raros, no entanto, pode ocorrer uma entrega dupla.
Por exemplo, se um kubelet reiniciar no meio do envio de um hook, o hook pode ser
reenviado depois que o kubelet voltar a funcionar.
Depurando manipuladores de hooks
Os logs para um manipulador de hook não são expostos em eventos de Pod.
Se um manipulador falhar por algum motivo, ele transmitirá um evento.
Para PostStart é o evento FailedPostStartHook e para PreStop é o evento
FailedPreStopHook.
Você pode ver esses eventos executando kubectl describe pod <nome_do_pod>.
Aqui está um exemplo de saída de eventos da execução deste comando:
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 1m 1 {default-scheduler } Normal Scheduled Successfully assigned test-1730497541-cq1d2 to gke-test-cluster-default-pool-a07e5d30-siqd
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Pulling pulling image "test:1.0"
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Created Created container with docker id 5c6a256a2567; Security:[seccomp=unconfined]
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Pulled Successfully pulled image "test:1.0"
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Started Started container with docker id 5c6a256a2567
38s 38s 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Killing Killing container with docker id 5c6a256a2567: PostStart handler: Error executing in Docker Container: 1
37s 37s 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Killing Killing container with docker id 8df9fdfd7054: PostStart handler: Error executing in Docker Container: 1
38s 37s 2 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} Warning FailedSync Error syncing pod, skipping: failed to "StartContainer" for "main" with RunContainerError: "PostStart handler: Error executing in Docker Container: 1"
1m 22s 2 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Warning FailedPostStartHook
3.5 - Serviços, balanceamento de carga e conectividade
Conceitos e recursos por trás da conectividade no Kubernetes.
A conectividade do Kubernetes trata quatro preocupações:
Contêineres em um Pod se comunicam via interface loopback.
A conectividade do cluster provê a comunicação entre diferentes Pods.
O recurso de Service permite a você expor uma aplicação executando em um Pod,
de forma a ser alcançável de fora de seu cluster.
Você também pode usar os Services para publicar serviços de consumo interno do
seu cluster.
3.5.1 - Políticas de rede
Se você deseja controlar o fluxo do tráfego de rede no nível do endereço IP ou de portas TCP e UDP
(camadas OSI 3 e 4) então você deve considerar usar Políticas de rede (NetworkPolicies) do Kubernetes para aplicações
no seu cluster. NetworkPolicy é um objeto focado em aplicações/experiência do desenvolvedor
que permite especificar como é permitido a um pod
comunicar-se com várias "entidades" de rede.
As entidades que um Pod pode se comunicar são identificadas através de uma combinação dos 3
identificadores à seguir:
Outros pods que são permitidos (exceção: um pod não pode bloquear a si próprio)
Namespaces que são permitidos
Blocos de IP (exceção: o tráfego de e para o nó que um Pod está executando sempre é permitido,
independentemente do endereço IP do Pod ou do Nó)
Quando definimos uma política de rede baseada em pod ou namespace, utiliza-se um selector
para especificar qual tráfego é permitido de e para o(s) Pod(s) que correspondem ao seletor.
Quando uma política de redes baseada em IP é criada, nós definimos a política baseada em blocos de IP (faixas CIDR).
Pré requisitos
As políticas de rede são implementadas pelo plugin de redes. Para usar
uma política de redes, você deve usar uma solução de redes que suporte o objeto NetworkPolicy.
A criação de um objeto NetworkPolicy sem um controlador que implemente essas regras não tem efeito.
Pods isolados e não isolados
Por padrão, pods não são isolados; eles aceitam tráfego de qualquer origem.
Os pods tornam-se isolados ao existir uma NetworkPolicy que selecione eles. Uma vez que
exista qualquer NetworkPolicy no namespace selecionando um pod em específico, aquele pod
irá rejeitar qualquer conexão não permitida por qualquer NetworkPolicy. (Outros pod no mesmo
namespace que não são selecionados por nenhuma outra NetworkPolicy irão continuar aceitando
todo tráfego de rede.)
As políticas de rede não conflitam; elas são aditivas. Se qualquer política selecionar um pod,
o pod torna-se restrito ao que é permitido pela união das regras de entrada/saída de tráfego definidas
nas políticas. Assim, a ordem de avaliação não afeta o resultado da política.
Para o fluxo de rede entre dois pods ser permitido, tanto a política de saída no pod de origem
e a política de entrada no pod de destino devem permitir o tráfego. Se a política de saída na
origem, ou a política de entrada no destino negar o tráfego, o tráfego será bloqueado.
O recurso NetworkPolicy
Veja a referência NetworkPolicy para uma definição completa do recurso.
Nota: Criar esse objeto no seu cluster não terá efeito a não ser que você escolha uma
solução de redes que suporte políticas de rede.
Campos obrigatórios: Assim como todas as outras configurações do Kubernetes, uma NetworkPolicy
necessita dos campos apiVersion, kind e metadata. Para maiores informações sobre
trabalhar com arquivos de configuração, veja
Configurando containeres usando ConfigMap,
e Gerenciamento de objetos.
spec: A spec contém todas as informações necessárias
para definir uma política de redes em um namespace.
podSelector: Cada NetworkPolicy inclui um podSelector que seleciona o grupo de pods
que a política se aplica. A política acima seleciona os pods com a label "role=db". Um podSelector
vazio seleciona todos os pods no namespace.
policyTypes: Cada NetworkPolicy inclui uma lista de policyTypes que pode incluir Ingress,
Egress ou ambos. O campo policyTypes indica se a política se aplica ao tráfego de entrada
com destino aos pods selecionados, o tráfego de saída com origem dos pods selecionados ou ambos.
Se nenhum policyType for definido então por padrão o tipo Ingress será sempre utilizado, e o
tipo Egress será configurado apenas se o objeto contiver alguma regra de saída. (campo egress a seguir).
ingress: Cada NetworkPolicy pode incluir uma lista de regras de entrada permitidas através do campo ingress.
Cada regra permite o tráfego que corresponde simultaneamente às sessões from (de) e ports (portas).
A política de exemplo acima contém uma regra simples, que corresponde ao tráfego em uma única porta,
de uma das três origens definidas, sendo a primeira definida via ipBlock, a segunda via namespaceSelector e
a terceira via podSelector.
egress: Cada política pode incluir uma lista de regras de regras de saída permitidas através do campo egress.
Cada regra permite o tráfego que corresponde simultaneamente às sessões to (para) e ports (portas).
A política de exemplo acima contém uma regra simples, que corresponde ao tráfego destinado a uma
porta em qualquer destino pertencente à faixa de IPs em 10.0.0.0/24.
Então a NetworkPolicy acima:
Isola os pods no namespace "default" com a label "role=db" para ambos os tráfegos de entrada
e saída (se eles ainda não estavam isolados)
(Regras de entrada/ingress) permite conexões para todos os pods no namespace "default" com a label "role=db" na porta TCP 6379 de:
qualquer pod no namespace "default" com a label "role=frontend"
qualquer pod em um namespace que tenha a label "project=myproject" (aqui cabe ressaltar que o namespace que deve ter a label e não os pods dentro desse namespace)
IPs dentro das faixas 172.17.0.0–172.17.0.255 e 172.17.2.0–172.17.255.255 (ex.:, toda 172.17.0.0/16 exceto 172.17.1.0/24)
(Regras de saída/egress) permite conexões de qualquer pod no namespace "default" com a label
"role=db" para a faixa de destino 10.0.0.0/24 na porta TCP 5978.
Existem quatro tipos de seletores que podem ser especificados nas sessões ingress.from ou
egress.to:
podSelector: Seleciona Pods no mesmo namespace que a política de rede foi criada, e que deve
ser permitido origens no tráfego de entrada ou destinos no tráfego de saída.
namespaceSelector: Seleciona namespaces para o qual todos os Pods devem ser permitidos como
origens no caso de tráfego de entrada ou destino no tráfego de saída.
namespaceSelectorepodSelector: Uma entrada to/from única que permite especificar
ambos namespaceSelector e podSelector e seleciona um conjunto de Pods dentro de um namespace.
Seja cuidadoso em utilizar a sintaxe YAML correta; essa política:
contém dois elementos no conjunto from e permite conexões de Pods no namespace local com
a labelrole=client, OU de qualquer outro Pod em qualquer outro namespace que tenha
a label user=alice.
Quando estiver em dúvida, utilize o comando kubectl describe para verificar como o
Kubernetes interpretou a política.
ipBlock: Isso seleciona um conjunto particular de faixas de IP a serem permitidos como
origens no caso de entrada ou destinos no caso de saída. Devem ser considerados IPs externos
ao cluster, uma vez que os IPs dos Pods são efêmeros e imprevisíveis.
Os mecanismos de entrada e saída do cluster geralmente requerem que os IPs de origem ou destino
sejam reescritos. Em casos em que isso aconteça, não é definido se deve acontecer antes ou
depois do processamento da NetworkPolicy que corresponde a esse tráfego, e o comportamento
pode ser diferente para cada plugin de rede, provedor de nuvem, implementação de Service, etc.
No caso de tráfego de entrada, isso significa que em alguns casos você pode filtrar os pacotes
de entrada baseado no IP de origem atual, enquanto que em outros casos o IP de origem que
a NetworkPolicy atua pode ser o IP de um LoadBalancer ou do Nó em que o Pod está executando.
No caso de tráfego de saída, isso significa que conexões de Pods para Services que são reescritos
para IPs externos ao cluster podem ou não estar sujeitos a políticas baseadas no campo ipBlock.
Políticas padrão
Por padrão, se nenhuma política existir no namespace, então todo o tráfego de entrada e saída é
permitido de e para os pods nesse namespace. Os exemplos a seguir permitem a você mudar o
comportamento padrão nesse namespace.
Bloqueio padrão de todo tráfego de entrada
Você pode criar uma política padrão de isolamento para um namespace criando um objeto NetworkPolicy
que seleciona todos os pods mas não permite o tráfego de entrada para esses pods.
Isso garante que mesmo pods que não são selecionados por nenhuma outra política de rede ainda
serão isolados. Essa política não muda o comportamento padrão de isolamento de tráfego de saída
nesse namespace.
Permitir por padrão todo tráfego de entrada
Se você deseja permitir todo o tráfego de todos os pods em um namespace (mesmo que políticas que
sejam adicionadas faça com que alguns pods sejam tratados como "isolados"), você pode criar
uma política que permite explicitamente todo o tráfego naquele namespace.
Você pode criar uma política de isolamento de saída padrão para um namespace criando uma
política de redes que selecione todos os pods, mas não permita o tráfego de saída a partir
de nenhum desses pods.
Isso garante que mesmo pods que não são selecionados por outra política de rede não seja permitido
tráfego de saída. Essa política não muda o comportamento padrão de tráfego de entrada.
Permitir por padrão todo tráfego de saída
Caso você queira permitir todo o tráfego de todos os pods em um namespace (mesmo que políticas sejam
adicionadas e cause com que alguns pods sejam tratados como "isolados"), você pode criar uma
política explicita que permite todo o tráfego de saída no namespace.
Isso garante que mesmo pods que não são selecionados por nenhuma outra política de redes não
possuam permissão de tráfego de entrada ou saída.
Selecionando uma faixa de portas
FEATURE STATE:Kubernetes v1.21 [alpha]
Ao escrever uma política de redes, você pode selecionar uma faixa de portas ao invés de uma
porta única, utilizando-se do campo endPort conforme a seguir:
A regra acima permite a qualquer Pod com a label "role=db" no namespace default de se comunicar
com qualquer IP na faixa 10.0.0.0/24 através de protocolo TCP, desde que a porta de destino
esteja na faixa entre 32000 e 32768.
As seguintes restrições aplicam-se ao se utilizar esse campo:
Por ser uma funcionalidade "alpha", ela é desativada por padrão. Para habilitar o campo endPort
no cluster, você (ou o seu administrador do cluster) deve habilitar o feature gateNetworkPolicyEndPort no kube-apiserver com a flag --feature-gates=NetworkPolicyEndPort=true,....
O valor de endPort deve ser igual ou maior ao valor do campo port.
O campo endPort só pode ser definido se o campo port também for definido.
Ambos os campos port e endPort devem ser números.
Nota: Seu cluster deve utilizar um plugin CNI
que suporte o campo endPort na especificação da política de redes.
Selecionando um Namespace pelo seu nome
FEATURE STATE:Kubernetes 1.21 [beta]
A camada de gerenciamento do Kubernetes configura uma label imutável kubernetes.io/metadata.name em
todos os namespaces, uma vez que o feature gate esteja habilitado por padrão.
O valor dessa label é o nome do namespace.
Enquanto que um objeto NetworkPolicy não pode selecionar um namespace pelo seu nome através de
um campo específico, você pode utilizar essa label padrão para selecionar um namespace pelo seu nome.
O que você não pode fazer com NetworkPolicies (ao menos por enquanto!)
Por enquanto no Kubernetes 1.23 as funcionalidades a seguir não existem
mas você pode conseguir implementar de forma alternativa utilizando componentes do Sistema Operacional
(como SELinux, OpenVSwitch, IPtables, etc) ou tecnologias da camada 7 OSI (Ingress controllers, implementações de service mesh) ou ainda admission controllers.
No caso do assunto "segurança de redes no Kubernetes" ser novo para você, vale notar que as
histórias de usuário a seguir ainda não podem ser implementadas:
Forçar o tráfego interno do cluster passar por um gateway comum (pode ser implementado via service mesh ou outros proxies)
Qualquer coisa relacionada a TLS/mTLS (use um service mesh ou ingress controller para isso)
Políticas específicas a nível do nó kubernetes (você pode utilizar as notações de IP CIDR para isso, mas não pode selecionar nós Kubernetes por suas identidades)
Selecionar Services pelo seu nome (você pode, contudo, selecionar pods e namespaces por seus labels o que torna-se uma solução de contorno viável).
Criação ou gerenciamento
Políticas padrão que são aplicadas a todos os namespaces e pods (existem alguns plugins externos do Kubernetes e projetos que podem fazer isso, e a comunidade está trabalhando nessa especificação).
Ferramental de testes para validação de políticas de redes.
Possibilidade de logar eventos de segurança de redes (conexões bloqueadas, aceitas). Existem plugins CNI que conseguem fazer isso à parte.
Possibilidade de explicitamente negar políticas de rede (o modelo das NetworkPolicies são "negar por padrão e conforme a necessidade, deve-se adicionar regras que permitam o tráfego).
Bloquear o tráfego que venha da interface de loopback/localhost ou que venham do nó em que o Pod se encontre.
Esse documento destaca e consolida as melhores práticas de configuração apresentadas em todo o guia de usuário,
na documentação de introdução e nos exemplos.
Este é um documento vivo. Se você pensar em algo que não está nesta lista, mas pode ser útil para outras pessoas,
não hesite em criar uma issue ou submeter um PR.
Dicas Gerais de Configuração
Ao definir configurações, especifique a versão mais recente estável da API.
Os arquivos de configuração devem ser armazenados em um sistema de controle antes de serem enviados ao cluster.
Isso permite que você reverta rapidamente uma alteração de configuração, caso necessário. Isso também auxilia na recriação e restauração do cluster.
Escreva seus arquivos de configuração usando YAML ao invés de JSON. Embora esses formatos possam ser usados alternadamente em quase todos os cenários, YAML tende a ser mais amigável.
Agrupe objetos relacionados em um único arquivo sempre que fizer sentido. Geralmente, um arquivo é mais fácil de
gerenciar do que vários. Veja o guestbook-all-in-one.yaml como exemplo dessa sintaxe.
Observe também que vários comandos kubectl podem ser chamados em um diretório. Por exemplo, você pode chamar
kubectl apply em um diretório de arquivos de configuração.
Não especifique valores padrões desnecessariamente: configurações simples e mínimas diminuem a possibilidade de erros.
Coloque descrições de objetos nas anotações para permitir uma melhor análise.
"Naked" Pods comparados a ReplicaSets, Deployments, e Jobs
Se você puder evitar, não use "naked" Pods (ou seja, se você puder evitar, pods não vinculados a um ReplicaSet ou Deployment).
Os "naked" pods não serão reconfigurados em caso de falha de um nó.
Criar um Deployment, que cria um ReplicaSet para garantir que o número desejado de Pods esteja disponível e especifica uma estratégia para substituir os Pods (como RollingUpdate), é quase sempre preferível do que criar Pods diretamente, exceto para alguns cenários explícitos de restartPolicy:Never. Um Job também pode ser apropriado.
Services
Crie o Service antes de suas cargas de trabalho de backend correspondentes (Deployments ou ReplicaSets) e antes de quaisquer cargas de trabalho que precisem acessá-lo. Quando o
Kubernetes inicia um contêiner, ele fornece variáveis de ambiente apontando para todos os Services que estavam em execução quando o contêiner foi iniciado. Por exemplo, se um Service chamado foo existe, todos os contêineres vão
receber as seguintes variáveis em seu ambiente inicial:
FOO_SERVICE_HOST=<o host em que o Service está executando>
FOO_SERVICE_PORT=<a porta em que o Service está executando>
Isso implica em um requisito de pedido - qualquer Service que um Pod quer acessar precisa ser criado antes do Pod em si, ou então as variáveis de ambiente não serão populadas. O DNS não possui essa restrição.
Um cluster add-on opcional (embora fortemente recomendado) é um servidor DNS. O
servidor DNS monitora a API do Kubernetes buscando novos Services e cria um conjunto de DNS para cada um. Se o DNS foi habilitado em todo o cluster, então todos os Pods devem ser capazes de fazer a resolução de Services automaticamente.
Não especifique um hostPort para um Pod a menos que isso seja absolutamente necessário. Quando você vincula um Pod a um hostPort, isso limita o número de lugares em que o Pod pode ser agendado, porque cada
combinação de <hostIP, hostPort, protocol> deve ser única. Se você não especificar o hostIP e protocol explicitamente, o Kubernetes vai usar 0.0.0.0 como o hostIP padrão e TCP como protocol padrão.
Se você precisa expor explicitamente a porta de um Pod no nó, considere usar um Service do tipo NodePort antes de recorrer a hostPort.
Evite usar hostNetwork pelos mesmos motivos do hostPort.
Use headless Services (que tem um ClusterIP ou None) para descoberta de serviço quando você não precisar de um balanceador de carga kube-proxy.
Usando Labels
Defina e use labels que identifiquem atributos semânticos da sua aplicação ou Deployment, como { app: myapp, tier: frontend, phase: test, deployment: v3 }. Você pode usar essas labels para selecionar os Pods apropriados para outros recursos; por exemplo, um Service que seleciona todos os Pods tier: frontend, ou todos
os componentes de app: myapp. Veja o app guestbook para exemplos dessa abordagem.
Um Service pode ser feito para abranger vários Deployments, omitindo labels específicas de lançamento de seu seletor. Quando você
precisar atualizar um serviço em execução sem downtime, use um Deployment.
Um estado desejado de um objeto é descrito por um Deployment, e se as alterações nesse spec forem aplicadas o controlador
do Deployment altera o estado real para o estado desejado em uma taxa controlada.
Use as labels comuns do Kubernetes para casos de uso comuns.
Essas labels padronizadas enriquecem os metadados de uma forma que permite que ferramentas, incluindo kubectl e a dashboard, funcionem de uma forma interoperável.
Você pode manipular labels para depuração. Como os controladores do Kubernetes (como ReplicaSet) e Services se relacionam com os Pods usando seletor de labels, remover as labels relevantes de um Pod impedirá que ele seja considerado por um controlador ou que
seja atendido pelo tráfego de um Service. Se você remover as labels de um Pod existente, seu controlador criará um novo Pod para
substituí-lo. Essa é uma maneira útil de depurar um Pod anteriormente "ativo" em um ambiente de "quarentena". Para remover ou
alterar labels interativamente, use kubectl label.
Imagens de Contêiner
A imagePullPolicy e tag da imagem afetam quando o kubelet tenta puxar a imagem especificada.
imagePullPolicy: IfNotPresent: a imagem é puxada apenas se ainda não estiver presente localmente.
imagePullPolicy: Always: sempre que o kubelet inicia um contêiner, ele consulta o registry da imagem do contêiner para verificar o resumo de assinatura da imagem. Se o kubelet tiver uma imagem do contêiner com o mesmo resumo de assinatura
armazenado em cache localmente, o kubelet usará a imagem em cache, caso contrário, o kubelet baixa(pulls) a imagem com o resumo de assinatura resolvido, e usa essa imagem para iniciar o contêiner.
imagePullPolicy é omitido se a tag da imagem é :latest ou se imagePullPolicy é omitido é automaticamente definido como Always. Observe que não será utilizado para ifNotPresentse o valor da tag mudar.
imagePullPolicy é omitido se uma tag da imagem existe mas não :latest: imagePullPolicy é automaticamente definido como ifNotPresent. Observe que isto não será atualizado para Always se a tag for removida ou alterada para :latest.
imagePullPolicy: Never: presume-se que a imagem exista localmente. Não é feita nenhuma tentativa de puxar a imagem.
Nota: Para garantir que seu contêiner sempre use a mesma versão de uma imagem, você pode especificar seu resumo de assinatura;
substitua <nome-da-imagem>:<tag> por <nome-da-imagem>@<hash> (por exemplo, image@sha256:45b23dee08af5e43a7fea6c4cf9c25ccf269ee113168c19722f87876677c5cb2). Esse resumo de assinatura identifica exclusivamente uma versão
específica de uma imagem, então isso nunca vai ser atualizado pelo Kubernetes a menos que você mude o valor do resumo de assinatura da imagem.
Nota: Você deve evitar o uso da tag :latest em produção, pois é mais difícil rastrear qual versão da imagem está sendo executada e mais difícil reverter adequadamente.
Nota: A semântica de cache do provedor de imagem subjacente torna até mesmo imagePullPolicy: Always eficiente, contanto que o registro esteja acessível de forma confiável. Com o Docker, por exemplo, se a imagem já existe, a tentativa de baixar(pull) é rápida porque todas as camadas da imagem são armazenadas em cache e nenhum download de imagem é necessário.
Usando kubectl
Use kubectl apply -f <directory>. Isso procura por configurações do Kubernetes em todos os arquivos .yaml, .yml em <directory> e passa isso para apply.
Um ConfigMap é um objeto da API usado para armazenar dados não-confidenciais em pares chave-valor.
Pods podem consumir ConfigMaps como variáveis de ambiente, argumentos de linha de comando ou como arquivos de configuração em um volume.
Um ConfigMap ajuda a desacoplar configurações vinculadas ao ambiente das imagens de contêiner, de modo a tornar aplicações mais facilmente portáveis.
Cuidado: O ConfigMap não oferece confidencialidade ou encriptação.
Se os dados que você deseja armazenar são confidenciais, utilize
Secret ao invés de um ConfigMap,
ou utilize ferramentas adicionais (de terceiros) para manter seus dados privados.
Motivação
Utilize um ConfigMap para manter a configuração separada do código da aplicação.
Por exemplo, imagine que você esteja desenvolvendo uma aplicação que pode ser executada
no seu computador local (para desenvolvimento) e na nuvem (para manipular tráfego real).
Você escreve código para ler a variável de ambiente chamada DATABASE_HOST.
No seu ambiente local, você configura essa variável com o valor localhost. Na nuvem, você
configura essa variável para referenciar um serviço
do Kubernetes que expõe o componente do banco de dados ao seu cluster.
Isto permite que você baixe uma imagem de contêiner que roda na nuvem e depure exatamente
o mesmo código localmente se necessário.
Um ConfigMap não foi planejado para conter grandes quantidades de dados. Os dados armazenados
em um ConfigMap não podem exceder 1 MiB. Se você precisa armazenar configurações que são maiores
que este limite, considere montar um volume ou utilizar um serviço separado de banco de dados
ou de arquivamento de dados.
Objeto ConfigMap
Um ConfigMap é um objeto
da API que permite o armazenamento de configurações para consumo por outros objetos. Diferentemente
de outros objetos do Kubernetes que contém um campo spec, o ConfigMap contém os campos data e
binaryData. Estes campos aceitam pares chave-valor como valores. Ambos os campos data e binaryData
são opcionais. O campo data foi pensado para conter sequências de bytes UTF-8, enquanto o campo binaryData
foi planejado para conter dados binários em forma de strings codificadas em base64.
Cada chave sob as seções data ou binaryData pode conter quaisquer caracteres alfanuméricos,
-, _ e .. As chaves armazenadas na seção data não podem colidir com as chaves armazenadas
na seção binaryData.
A partir da versão v1.19 do Kubernetes, é possível adicionar o campo immutable a uma definição de ConfigMap
para criar um ConfigMap imutável.
ConfigMaps e Pods
Você pode escrever uma spec para um Pod que se refere a um ConfigMap e configurar o(s) contêiner(es)
neste Pod baseados em dados do ConfigMap. O Pod e o ConfigMap devem estar no mesmo
namespace.
Nota: A spec de um Pod estático não pode se referir a um
ConfigMap ou a quaisquer outros objetos da API.
Exemplo de um ConfigMap que contém algumas chaves com valores avulsos e outras chaves com valores semelhantes
a fragmentos de arquivos de configuração:
apiVersion:v1kind:ConfigMapmetadata:name:game-demodata:# chaves com valores de propriedades; cada chave mapeia para um valor avulsoplayer_initial_lives:"3"ui_properties_file_name:"user-interface.properties"# chaves semelhantes a fragmentos de arquivosgame.properties:| enemy.types=aliens,monsters
player.maximum-lives=5user-interface.properties:| color.good=purple
color.bad=yellow
allow.textmode=true
Existem quatro formas diferentes para consumo de um ConfigMap na configuração de um
contêiner dentro de um Pod:
Dentro de um comando de contêiner e seus argumentos.
Variáveis de ambiente para um contêiner.
Criando um arquivo em um volume somente leitura, para consumo pela aplicação.
Escrevendo código para execução dentro do Pod que utilize a API do Kubernetes para ler um ConfigMap.
Os diferentes métodos de consumo oferecem diferentes formas de modelar os dados sendo consumidos.
Para os três primeiros métodos, o kubelet utiliza
os dados de um ConfigMap quando o(s) contêiner(es) do Pod são inicializados.
O quarto método envolve escrita de código para leitura do ConfigMap e dos seus dados. No entanto,
como a API do Kubernetes está sendo utilizada diretamente, a aplicação pode solicitar atualizações
sempre que o ConfigMap for alterado e reagir quando isso ocorre. Acessar a API do Kubernetes
diretamente também permite ler ConfigMaps em outros namespaces.
Exemplo de um Pod que utiliza valores do ConfigMap game-demo para configurar um Pod:
apiVersion:v1kind:Podmetadata:name:configmap-demo-podspec:containers:- name:demoimage:alpinecommand:["sleep","3600"]env:# Define as variáveis de ambiente- name:PLAYER_INITIAL_LIVES# Note que aqui a variável está definida em caixa alta,# diferente da chave no ConfigMap.valueFrom:configMapKeyRef:name:game-demo # O ConfigMap de onde esse valor vem.key:player_initial_lives# A chave que deve ser buscada.- name:UI_PROPERTIES_FILE_NAMEvalueFrom:configMapKeyRef:name:game-demokey:ui_properties_file_namevolumeMounts:- name:configmountPath:"/config"readOnly:truevolumes:# Volumes são definidos no escopo do Pod, e os pontos de montagem são definidos# nos contêineres dentro dos pods.- name:configconfigMap:# Informe o nome do ConfigMap que deseja montar.name:game-demo# Uma lista de chaves do ConfigMap para serem criadas como arquivos.items:- key:"game.properties"path:"game.properties"- key:"user-interface.properties"path:"user-interface.properties"
ConfigMaps não diferenciam entre propriedades com valores simples ou valores complexos,
que ocupam várias linhas. O importante é a forma que Pods e outros objetos consomem tais valores.
Neste exemplo, definir um volume e montar ele dentro do contêiner demo no caminho /config
cria dois arquivos: /config/game.properties e /config/user-interface.properties, embora existam
quatro chaves distintas no ConfigMap. Isso se deve ao fato de que a definição do Pod contém uma lista
items na seção volumes.
Se a lista items for omitida, cada chave do ConfigMap torna-se um arquivo cujo nome é a sua chave
correspondente, e quatro arquivos serão criados.
Usando ConfigMaps
ConfigMaps podem ser montados como volumes de dados. ConfigMaps também podem ser utilizados
por outras partes do sistema sem serem diretamente expostos ao Pod. Por exemplo, ConfigMaps
podem conter dados que outras partes do sistema devem usar para configuração.
A forma mais comum de utilização de ConfigMaps é a configuração de contêineres executando em
Pods no mesmo namespace. Você também pode utilizar um ConfigMap separadamente.
Por exemplo, existem complementos ou
operadores que adaptam seus comportamentos
de acordo com dados de um ConfigMap.
Utilizando ConfigMaps como arquivos em um Pod
Para consumir um ConfigMap em um volume em um Pod:
Crie um ConfigMap ou utilize um ConfigMap existente. Múltiplos Pods
podem referenciar o mesmo ConfigMap.
Modifique sua definição de Pod para adicionar um volume em
.spec.volumes[]. Escolha um nome qualquer para o seu volume, e
referencie o seu objeto ConfigMap no campo
.spec.volumes[].configMap.name.
Adicione um campo .spec.containers[].volumeMounts[] a cada um dos
contêineres que precisam do ConfigMap. Especifique
.spec.containers[].volumeMounts[].readOnly = true e informe no campo
.spec.containers[].volumeMounts[].mountPath um caminho de um diretório
não utilizado onde você deseja que este ConfigMap apareça.
Modifique sua imagem ou linha de comando de modo que o programa procure
por arquivos no diretório especificado no passo anterior. Cada chave no
campo data do ConfigMap será transformado em um nome de arquivo no
diretório especificado por mountPath.
Exemplo de um Pod que monta um ConfigMap em um volume:
Cada ConfigMap que você deseja utilizar precisa ser referenciado em
.spec.volumes.
Se houver múltiplos contêineres no Pod, cada contêiner deve ter seu
próprio bloco volumeMounts, mas somente uma instância de .spec.volumes
é necessária por ConfigMap.
ConfigMaps montados são atualizados automaticamente
Quando um ConfigMap que está sendo consumido em um volume é atualizado, as chaves projetadas são
eventualmente atualizadas também. O Kubelet checa se o ConfigMap montado está atualizado em cada
sincronização periódica.
No entanto, o kubelet utiliza o cache local para buscar o valor atual do ConfigMap.
O tipo de cache é configurável utilizando o campo ConfigMapAndSecretChangeDetectionStrategy na
configuração do Kubelet (KubeletConfiguration).
Um ConfigMap pode ter sua propagação baseada em um watch (comportamento padrão), que é o sistema
de propagação de mudanças incrementais em objetos do Kubernetes; baseado em TTL (time to live,
ou tempo de expiração); ou redirecionando todas as requisições diretamente para o servidor da API.
Como resultado, o tempo decorrido total entre o momento em que o ConfigMap foi atualizado até o momento
quando as novas chaves são projetadas nos Pods pode ser tão longo quanto o tempo de sincronização
do kubelet somado ao tempo de propagação do cache, onde o tempo de propagação do cache depende do
tipo de cache escolhido: o tempo de propagação pode ser igual ao tempo de propagação do watch,
TTL do cache, ou zero, de acordo com cada um dos tipos de cache.
ConfigMaps que são consumidos como variáveis de ambiente não atualizam automaticamente e requerem uma
reinicialização do pod.
ConfigMaps imutáveis
FEATURE STATE:Kubernetes v1.21 [stable]
A funcionalidade Secrets e ConfigMaps imutáveis do Kubernetes fornece uma opção
para marcar Secrets e ConfigMaps individuais como imutáveis. Para clusters que utilizam
ConfigMaps extensivamente (ao menos centenas de milhares de mapeamentos únicos de
ConfigMaps para Pods), prevenir alterações dos seus dados traz as seguintes vantagens:
protege de atualizações acidentais ou indesejadas que podem causar disrupção na execução
de aplicações
melhora o desempenho do cluster através do fechamento de watches de ConfigMaps marcados
como imutáveis, diminuindo significativamente a carga no kube-apiserver
Essa funcionalidade é controlada pelo feature gateImmutableEphemeralVolumes. É possível criar um ConfigMap imutável adicionando o campo
immutable e marcando seu valor com true.
Por exemplo:
Após um ConfigMap ser marcado como imutável, não é possível reverter a alteração, nem
alterar o conteúdo dos campos data ou binaryData. É possível apenas apagar e recriar
o ConfigMap. Como Pods existentes que consomem o ConfigMap em questão mantém um ponto de
montagem que continuará referenciando este objeto após a remoção, é recomendado recriar
estes pods.
Leia The Twelve-Factor App (em inglês) para entender a motivação da separação de código
e configuração.
3.6.3 - Secrets
Um Secret é um objeto que contém uma pequena quantidade de informação sensível,
como senhas, tokens ou chaves. Este tipo de informação poderia, em outras
circunstâncias, ser colocada diretamente em uma configuração de
Pod ou em uma
imagem de contêiner. O uso de
Secrets evita que você tenha de incluir dados confidenciais no seu código.
Secrets podem ser criados de forma independente dos Pods que os consomem. Isto
reduz o risco de que o Secret e seus dados sejam expostos durante o processo de
criação, visualização e edição ou atualização de Pods. O Kubernetes e as
aplicações que rodam no seu cluster podem também tomar outras precauções com
Secrets, como por exemplo evitar a escrita de dados confidenciais em local de
armazenamento persistente (não-volátil).
Secrets são semelhantes a
ConfigMaps, mas foram
especificamente projetados para conter dados confidenciais.
Cuidado:
Os Secrets do Kubernetes são, por padrão, gravados não-encriptados no sistema
de armazenamento de dados utilizado pelo servidor da API (etcd). Qualquer pessoa
com acesso à API ou ao etcd consegue obter ou modificar um Secret.
Além disso, qualquer pessoa que possui autorização para criar Pods em um namespace
consegue utilizar este privilégio para ler qualquer Secret naquele namespace. Isso
inclui acesso indireto, como por exemplo a permissão para criar Deployments.
Para utilizar Secrets de forma segura, siga pelo menos as instruções abaixo:
Habilite ou configure regras de RBAC
que restrinjam o acesso de leitura a Secrets (incluindo acesso indireto).
Quando apropriado, utilize mecanismos como RBAC para limitar quais perfis e
usuários possuem permissão para criar novos Secrets ou substituir Secrets
existentes.
Visão Geral de Secrets
Para utilizar um Secret, um Pod precisa referenciar o Secret.
Um Secret pode ser utilizado em um Pod de três maneiras diferentes:
Como um arquivo em um
volume montado em um ou mais de
seus contêineres.
A camada de gerenciamento do Kubernetes também utiliza Secrets. Por exemplo,
os Secrets de tokens de autoinicialização são um
mecanismo que auxilia a automação do registro de nós.
O nome de um Secret deve ser um subdomínio DNS válido.
Você pode especificar o campo data e/ou o campo stringData na criação de um
arquivo de configuração de um Secret. Ambos os campos data e stringData são
opcionais. Os valores das chaves no campo data devem ser strings codificadas
no formato base64. Se a conversão para base64 não for desejável, você pode
optar por informar os dados no campo stringData, que aceita strings arbitrárias
como valores.
As chaves dos campos data e stringData devem consistir de caracteres
alfanuméricos, -, _, ou .. Todos os pares chave-valor no campo stringData
são internamente combinados com os dados do campo data. Se uma chave aparece
em ambos os campos, o valor informado no campo stringData toma a precedência.
Tipos de Secrets
Ao criar um Secret, você pode especificar o seu tipo utilizando o campo type
do objeto Secret, ou algumas opções de linha de comando equivalentes no comando
kubectl, quando disponíveis. O campo type de um Secret é utilizado para
facilitar a manipulação programática de diferentes tipos de dados confidenciais.
O Kubernetes oferece vários tipos embutidos de Secret para casos de uso comuns.
Estes tipos variam em termos de validações efetuadas e limitações que o
Kubernetes impõe neles.
Tipo embutido
Caso de uso
Opaque
dados arbitrários definidos pelo usuário
kubernetes.io/service-account-token
token de service account (conta de serviço)
kubernetes.io/dockercfg
arquivo ~/.dockercfg serializado
kubernetes.io/dockerconfigjson
arquivo ~/.docker/config.json serializado
kubernetes.io/basic-auth
credenciais para autenticação básica (basic auth)
kubernetes.io/ssh-auth
credenciais para autenticação SSH
kubernetes.io/tls
dados para um cliente ou servidor TLS
bootstrap.kubernetes.io/token
dados de token de autoinicialização
Você pode definir e utilizar seu próprio tipo de Secret definindo o valor do
campo type como uma string não-nula em um objeto Secret. Uma string em branco
é tratada como o tipo Opaque. O Kubernetes não restringe nomes de tipos. No
entanto, quando tipos embutidos são utilizados, você precisa atender a todos os
requisitos daquele tipo.
Secrets tipo Opaque
Opaque é o tipo predefinido de Secret quando o campo type não é informado
em um arquivo de configuração. Quando um Secret é criado usando o comando
kubectl, você deve usar o subcomando generic para indicar que um Secret é
do tipo Opaque. Por exemplo, o comando a seguir cria um Secret vazio do tipo
Opaque:
kubectl create secret generic empty-secret
kubectl get secret empty-secret
O resultado será semelhante ao abaixo:
NAME TYPE DATA AGE
empty-secret Opaque 0 2m6s
A coluna DATA demonstra a quantidade de dados armazenados no Secret. Neste
caso, 0 significa que este objeto Secret está vazio.
Secrets de token de service account (conta de serviço)
Secrets do tipo kubernetes.io/service-account-token são utilizados para
armazenar um token que identifica uma service account (conta de serviço). Ao
utilizar este tipo de Secret, você deve garantir que a anotação
kubernetes.io/service-account.name contém um nome de uma service account
existente. Um controlador do Kubernetes preenche outros campos, como por exemplo
a anotação kubernetes.io/service-account.uid e a chave token no campo data
com o conteúdo do token.
O exemplo de configuração abaixo declara um Secret de token de service account:
apiVersion:v1kind:Secretmetadata:name:secret-sa-sampleannotations:kubernetes.io/service-account-name:"sa-name"type:kubernetes.io/service-account-tokendata:# Você pode incluir pares chave-valor adicionais, da mesma forma que faria com# Secrets do tipo Opaqueextra:YmFyCg==
Ao criar um Pod, o Kubernetes
automaticamente cria um Secret de service account e automaticamente atualiza o
seu Pod para utilizar este Secret. O Secret de token de service account contém
credenciais para acessar a API.
A criação automática e o uso de credenciais de API podem ser desativados se
desejado. Porém, se tudo que você necessita é poder acessar o servidor da API
de forma segura, este é o processo recomendado.
Veja a documentação de
ServiceAccount
para mais informações sobre o funcionamento de service accounts. Você pode
verificar também os campos automountServiceAccountToken e serviceAccountName
do Pod
para mais informações sobre como referenciar service accounts em Pods.
Secrets de configuração do Docker
Você pode utilizar um dos tipos abaixo para criar um Secret que armazena
credenciais para accesso a um registro de contêineres compatível com Docker
para busca de imagens:
kubernetes.io/dockercfg
kubernetes.io/dockerconfigjson
O tipo kubernetes.io/dockercfg é reservado para armazenamento de um arquivo
~/.dockercfg serializado. Este arquivo é o formato legado para configuração
do utilitário de linha de comando do Docker. Ao utilizar este tipo de Secret,
é preciso garantir que o campo data contém uma chave .dockercfg cujo valor
é o conteúdo do arquivo ~/.dockercfg codificado no formato base64.
O tipo kubernetes.io/dockerconfigjson foi projetado para armazenamento de um
conteúdo JSON serializado que obedece às mesmas regras de formato que o arquivo
~/.docker/config.json. Este arquivo é um formato mais moderno para o conteúdo
do arquivo ~/.dockercfg. Ao utilizar este tipo de Secret, o conteúdo do campo
data deve conter uma chave .dockerconfigjson em que o conteúdo do arquivo
~/.docker/config.json é fornecido codificado no formato base64.
Um exemplo de um Secret do tipo kubernetes.io/dockercfg:
Nota: Se você não desejar fazer a codificação em formato base64, você pode utilizar o
campo stringData como alternativa.
Ao criar estes tipos de Secret utilizando um manifesto (arquivo YAML), o servidor
da API verifica se a chave esperada existe no campo data e se o valor fornecido
pode ser interpretado como um conteúdo JSON válido. O servidor da API não verifica
se o conteúdo informado é realmente um arquivo de configuração do Docker.
Quando você não tem um arquivo de configuração do Docker, ou quer utilizar o
comando kubectl para criar um Secret de registro de contêineres compatível
com o Docker, você pode executar:
Se você extrair o conteúdo da chave .dockerconfigjson, presente no campo
data, e decodificá-lo do formato base64, você irá obter o objeto JSON abaixo,
que é uma configuração válida do Docker criada automaticamente:
O tipo kubernetes.io/basic-auth é fornecido para armazenar credenciais
necessárias para autenticação básica. Ao utilizar este tipo de Secret, o campo
data do Secret deve conter as duas chaves abaixo:
username: o usuário utilizado para autenticação;
password: a senha ou token para autenticação.
Ambos os valores para estas duas chaves são textos codificados em formato base64.
Você pode fornecer os valores como texto simples utilizando o campo stringData
na criação do Secret.
O arquivo YAML abaixo é um exemplo de configuração para um Secret de autenticação
básica:
O tipo de autenticação básica é fornecido unicamente por conveniência. Você pode
criar um Secret do tipo Opaque utilizado para autenticação básica. No entanto,
utilizar o tipo embutido de Secret auxilia a unificação dos formatos das suas
credenciais. O tipo embutido também fornece verificação de presença das chaves
requeridas pelo servidor da API.
Secret de autenticação SSH
O tipo embutido kubernetes.io/ssh-auth é fornecido para armazenamento de dados
utilizados em autenticação SSH. Ao utilizar este tipo de Secret, você deve
especificar um par de chave-valor ssh-privatekey no campo data ou no campo
stringData com a credencial SSH a ser utilizada.
O YAML abaixo é um exemplo de configuração para um Secret de autenticação SSH:
apiVersion:v1kind:Secretmetadata:name:secret-ssh-authtype:kubernetes.io/ssh-authdata:# os dados estão abreviados neste exemplossh-privatekey:|MIIEpQIBAAKCAQEAulqb/Y ...
O Secret de autenticação SSH é fornecido apenas para a conveniência do usuário.
Você pode criar um Secret do tipo Opaque para credentials utilizadas para
autenticação SSH. No entanto, a utilização do tipo embutido auxilia na
unificação dos formatos das suas credenciais e o servidor da API fornece
verificação dos campos requeridos em uma configuração de Secret.
Cuidado: Chaves privadas SSH não estabelecem, por si só, uma comunicação confiável
entre um cliente SSH e um servidor. Uma forma secundária de estabelecer
confiança é necessária para mitigar ataques "machine-in-the-middle", como
por exemplo um arquivo known_hosts adicionado a um ConfigMap.
Secrets TLS
O Kubernetes fornece o tipo embutido de Secret kubernetes.io/tls para
armazenamento de um certificado e sua chave associada que são tipicamente
utilizados para TLS. Estes dados são utilizados primariamente para a
finalização TLS do recurso Ingress, mas podem ser utilizados com outros
recursos ou diretamente por uma carga de trabalho. Ao utilizar este tipo de
Secret, as chaves tls.key e tls.crt devem ser informadas no campo data
(ou stringData) da configuração do Secret, embora o servidor da API não
valide o conteúdo de cada uma destas chaves.
O YAML a seguir tem um exemplo de configuração para um Secret TLS:
apiVersion:v1kind:Secretmetadata:name:secret-tlstype:kubernetes.io/tlsdata:# os dados estão abreviados neste exemplotls.crt:|MIIC2DCCAcCgAwIBAgIBATANBgkqh ...tls.key:|MIIEpgIBAAKCAQEA7yn3bRHQ5FHMQ ...
O tipo TLS é fornecido para a conveniência do usuário. Você pode criar um
Secret do tipo Opaque para credenciais utilizadas para o servidor e/ou
cliente TLS. No entanto, a utilização do tipo embutido auxilia a manter a
consistência dos formatos de Secret no seu projeto; o servidor da API
valida se os campos requeridos estão presentes na configuração do Secret.
Ao criar um Secret TLS utilizando a ferramenta de linha de comando kubectl,
você pode utilizar o subcomando tls conforme demonstrado no exemplo abaixo:
O par de chaves pública/privada deve ser criado separadamente. O certificado
de chave pública a ser utilizado no argumento --cert deve ser codificado em
formato .PEM (formato DER codificado em texto base64) e deve corresponder à
chave privada fornecida no argumento --key.
A chave privada deve estar no formato de chave privada PEM não-encriptado. Em
ambos os casos, as linhas inicial e final do formato PEM (por exemplo,
--------BEGIN CERTIFICATE----- e -------END CERTIFICATE---- para um
certificado) não são incluídas.
Secret de token de autoinicialização
Um Secret de token de autoinicialização pode ser criado especificando o tipo de
um Secret explicitamente com o valor bootstrap.kubernetes.io/token. Este tipo
de Secret é projetado para tokens utilizados durante o processo de inicialização
de nós. Este tipo de Secret armazena tokens utilizados para assinar ConfigMaps
conhecidos.
Um Secret de token de autoinicialização é normalmente criado no namespace
kube-system e nomeado na forma bootstrap-token-<id-do-token>, onde
<id-do-token> é um texto com 6 caracteres contendo a identificação do token.
No formato de manifesto do Kubernetes, um Secret de token de autoinicialização
se assemelha ao exemplo abaixo:
Um Secret do tipo token de autoinicialização possui as seguintes chaves no campo
data:
token-id: Uma string com 6 caracteres aleatórios como identificador do
token. Requerido.
token-secret: Uma string de 16 caracteres aleatórios como o conteúdo do
token. Requerido.
description: Uma string contendo uma descrição do propósito para o qual este
token é utilizado. Opcional.
expiration: Um horário absoluto UTC no formato RFC3339 especificando quando
o token deve expirar. Opcional.
usage-bootstrap-<usage>: Um conjunto de flags booleanas indicando outros
usos para este token de autoinicialização.
auth-extra-groups: Uma lista separada por vírgulas de nomes de grupos que
serão autenticados adicionalmente, além do grupo system:bootstrappers.
O YAML acima pode parecer confuso, já que os valores estão todos codificados em
formato base64. Você pode criar o mesmo Secret utilizando este YAML:
apiVersion:v1kind:Secretmetadata:# Observe como o Secret é nomeadoname:bootstrap-token-5emitj# Um Secret de token de inicialização geralmente fica armazenado no namespace# kube-systemnamespace:kube-systemtype:bootstrap.kubernetes.io/tokenstringData:auth-extra-groups:"system:bootstrappers:kubeadm:default-node-token"expiration:"2020-09-13T04:39:10Z"# Esta identificação de token é utilizada no nometoken-id:"5emitj"token-secret:"kq4gihvszzgn1p0r"# Este token pode ser utilizado para autenticação.usage-bootstrap-authentication:"true"# e pode ser utilizado para assinaturasusage-bootstrap-signing:"true"
Um Secret existente no cluster pode ser editado com o seguinte comando:
kubectl edit secrets mysecret
Este comando abrirá o editor padrão configurado e permitirá a modificação dos
valores codificados em base64 no campo data:
# Please edit the object below. Lines beginning with a '#' will be ignored,# and an empty file will abort the edit. If an error occurs while saving this file will be# reopened with the relevant failures.#apiVersion:v1data:username:YWRtaW4=password:MWYyZDFlMmU2N2Rmkind:Secretmetadata:annotations:kubectl.kubernetes.io/last-applied-configuration:{... }creationTimestamp:2016-01-22T18:41:56Zname:mysecretnamespace:defaultresourceVersion:"164619"uid:cfee02d6-c137-11e5-8d73-42010af00002type:Opaque
Utilizando Secrets
Secrets podem ser montados como volumes de dados ou expostos como
variáveis de ambiente
para serem utilizados num container de um Pod. Secrets também podem ser
utilizados por outras partes do sistema, sem serem diretamente expostos ao Pod.
Por exemplo, Secrets podem conter credenciais que outras partes do sistema devem
utilizar para interagir com sistemas externos no lugar do usuário.
Utilizando Secrets como arquivos em um Pod
Para consumir um Secret em um volume em um Pod:
Crie um Secret ou utilize um previamente existente. Múltiplos Pods podem
referenciar o mesmo secret.
Modifique sua definição de Pod para adicionar um volume na lista
.spec.volumes[]. Escolha um nome qualquer para o seu volume e adicione um
campo .spec.volumes[].secret.secretName com o mesmo valor do seu objeto
Secret.
Adicione um ponto de montagem de volume à lista
.spec.containers[].volumeMounts[] de cada contêiner que requer o Secret.
Especifique .spec.containers[].volumeMounts[].readOnly = true e especifique o
valor do campo .spec.containers[].volumeMounts[].mountPath com o nome de um
diretório não utilizado onde você deseja que os Secrets apareçam.
Modifique sua imagem ou linha de comando de modo que o programa procure por
arquivos naquele diretório. Cada chave no campo data se torna um nome de
arquivo no diretório especificado em mountPath.
Este é um exemplo de Pod que monta um Secret em um volume:
Cada Secret que você deseja utilizar deve ser referenciado na lista
.spec.volumes.
Se existirem múltiplos contêineres em um Pod, cada um dos contêineres necessitará
seu próprio bloco volumeMounts, mas somente um volume na lista .spec.volumes
é necessário por Secret.
Você pode armazenar vários arquivos em um Secret ou utilizar vários Secrets
distintos, o que for mais conveniente.
Projeção de chaves de Secrets a caminhos específicos
Você pode também controlar os caminhos dentro do volume onde as chaves do Secret
são projetadas. Você pode utilizar o campo .spec.volumes[].secret.items para
mudar o caminho de destino de cada chave:
O valor da chave username é armazenado no arquivo
/etc/foo/my-group/my-username ao invés de /etc/foo/username.
O valor da chave password não é projetado no sistema de arquivos.
Se .spec.volumes[].secret.items for utilizado, somente chaves especificadas
na lista items são projetadas. Para consumir todas as chaves do Secret, deve
haver um item para cada chave no campo items. Todas as chaves listadas precisam
existir no Secret correspondente. Caso contrário, o volume não é criado.
Permissões de arquivos de Secret
Você pode trocar os bits de permissão de uma chave avulsa de Secret.
Se nenhuma permissão for especificada, 0644 é utilizado por padrão.
Você pode também especificar uma permissão padrão para o volume inteiro de
Secret e sobrescrever esta permissão por chave, se necessário.
Por exemplo, você pode especificar uma permissão padrão da seguinte maneira:
Dessa forma, o Secret será montado em /etc/foo e todos os arquivos criados
no volume terão a permissão 0400.
Note que a especificação JSON não suporta notação octal. Neste caso, utilize o
valor 256 para permissões equivalentes a 0400. Se você utilizar YAML ao invés
de JSON para o Pod, você pode utilizar notação octal para especificar permissões
de uma forma mais natural.
Perceba que se você acessar o Pod com kubectl exec, você precisará seguir o
vínculo simbólico para encontrar a permissão esperada. Por exemplo,
Verifique as permissões do arquivo de Secret no pod.
kubectl exec mypod -it sh
cd /etc/foo
ls -l
O resultado é semelhante ao abaixo:
total 0
lrwxrwxrwx 1 root root 15 May 18 00:18 password -> ..data/password
lrwxrwxrwx 1 root root 15 May 18 00:18 username -> ..data/username
Siga o vínculo simbólico para encontrar a permissão correta do arquivo.
cd /etc/foo/..data
ls -l
O resultado é semelhante ao abaixo:
total 8
-r-------- 1 root root 12 May 18 00:18 password
-r-------- 1 root root 5 May 18 00:18 username
Você pode também utilizar mapeamento, como no exemplo anterior, e especificar
permissões diferentes para arquivos diferentes conforme abaixo:
Neste caso, o arquivo resultante em /etc/foo/my-group/my-username terá as
permissões 0777. Se você utilizar JSON, devido às limitações do formato,
você precisará informar as permissões em base decimal, ou o valor 511 neste
exemplo.
Note que os valores de permissões podem ser exibidos em formato decimal se você
ler essa informação posteriormente.
Consumindo valores de Secrets em volumes
Dentro do contêiner que monta um volume de Secret, as chaves deste Secret
aparecem como arquivos e os valores dos Secrets são decodificados do formato
base64 e armazenados dentro destes arquivos. Ao executar comandos dentro do
contêiner do exemplo anterior, obteremos os seguintes resultados:
ls /etc/foo
O resultado é semelhante a:
username
password
cat /etc/foo/username
O resultado é semelhante a:
admin
cat /etc/foo/password
O resultado é semelhante a:
1f2d1e2e67df
A aplicação rodando dentro do contêiner é responsável pela leitura dos Secrets
dentro dos arquivos.
Secrets montados são atualizados automaticamente
Quando um Secret que está sendo consumido a partir de um volume é atualizado, as
chaves projetadas são atualizadas após algum tempo também. O kubelet verifica
se o Secret montado está atualizado a cada sincronização periódica. No entanto,
o kubelet utiliza seu cache local para buscar o valor corrente de um Secret. O
tipo do cache é configurável utilizando o campo ConfigMapAndSecretChangeDetectionStrategy
na estrutura KubeletConfiguration.
Um Secret pode ser propagado através de um watch (comportamento padrão), que
é o sistema de propagação de mudanças incrementais em objetos do Kubernetes;
baseado em TTL (time to live, ou tempo de expiração); ou redirecionando todas
as requisições diretamente para o servidor da API.
Como resultado, o tempo decorrido total entre o momento em que o Secret foi
atualizado até o momento em que as novas chaves são projetadas nos Pods pode
ser tão longo quanto o tempo de sincronização do kubelet somado ao tempo de
propagação do cache, onde o tempo de propagação do cache depende do tipo de
cache escolhido: o tempo de propagação pode ser igual ao tempo de propagação
do watch, TTL do cache, ou zero, de acordo com cada um dos tipos de cache.
Nota: Um contêiner que utiliza Secrets através de um ponto de montagem com a
propriedade
subPath não recebe atualizações
deste Secret.
Crie um Secret ou utilize um já existente. Múltiplos Pods podem referenciar o
mesmo Secret.
Modifique a definição de cada contêiner do Pod em que desejar consumir o
Secret, adicionando uma variável de ambiente para cada uma das chaves que deseja
consumir.
A variável de ambiente que consumir o valor da chave em questão deverá popular o
nome do Secret e a sua chave correspondente no campo
env[].valueFrom.secretKeyRef.
Modifique sua imagem de contêiner ou linha de comando de forma que o programa
busque os valores nas variáveis de ambiente especificadas.
Este é um exemplo de um Pod que utiliza Secrets em variáveis de ambiente:
Consumindo valores de Secret em variáveis de ambiente
Dentro de um contêiner que consome um Secret em variáveis de ambiente, a chave
do Secret aparece como uma variável de ambiente comum, contendo os dados do
Secret decodificados do formato base64. Ao executar comandos no contêiner do
exemplo anterior, obteremos os resultados abaixo:
echo$SECRET_USERNAME
O resultado é semelhante a:
admin
echo$SECRET_PASSWORD
O resultado é semelhante a:
1f2d1e2e67df
Variáveis de ambiente não são atualizadas após uma atualização no Secret
Se um contêiner já consome um Secret em uma variável de ambiente, uma atualização
dos valores do Secret não será refletida no contêiner a menos que o contêiner
seja reiniciado.
Existem ferramentas de terceiros que oferecem reinicializações automáticas
quando Secrets são atualizados.
Secrets imutáveis
FEATURE STATE:Kubernetes v1.21 [stable]
A funcionalidade do Kubernetes Secrets e ConfigMaps imutáveis fornece uma
opção para marcar Secrets e ConfigMaps individuais como imutáveis. Em clusters
que fazem uso extensivo de Secrets (pelo menos dezenas de milhares de montagens
únicas de Secrets em Pods), prevenir alterações aos dados dos Secrets traz as
seguintes vantagens:
protege você de alterações acidentais ou indesejadas que poderiam provocar
disrupções na execução de aplicações;
melhora a performance do seu cluster através da redução significativa de carga
no kube-apiserver, devido ao fechamento de watches de Secrets marcados como
imutáveis.
Esta funcionalidade é controlada pelo
feature gateImmutableEphemeralVolumes, que está habilitado por padrão desde a versão
v1.19. Você pode criar um Secret imutável adicionando o campo immutable com
o valor true. Por exemplo:
Nota: Uma vez que um Secret ou ConfigMap seja marcado como imutável, não é mais
possível reverter esta mudança, nem alterar os conteúdos do campo data. Você
pode somente apagar e recriar o Secret. Pods existentes mantém um ponto de
montagem referenciando o Secret removido - é recomendado recriar tais Pods.
Usando imagePullSecrets
O campo imagePullSecrets é uma lista de referências para Secrets no mesmo
namespace. Você pode utilizar a lista imagePullSecrets para enviar Secrets
que contém uma senha para acesso a um registro de contêineres do Docker (ou
outros registros de contêineres) ao kubelet. O kubelet utiliza essa informação
para baixar uma imagem privada no lugar do seu Pod.
Veja a API PodSpec
para maiores detalhes sobre o campo imagePullSecrets.
Configurando imagePullSecrets para serem vinculados automaticamente
Você pode criar manualmente imagePullSecrets e referenciá-los em uma
ServiceAccount. Quaisquer Pods criados com esta ServiceAccount, especificada
explicitamente ou por padrão, têm o campo imagePullSecrets populado com os
mesmos valores existentes na service account.
Veja adicionando imagePullSecrets a uma service account
para uma explicação detalhada do processo.
Detalhes
Restrições
Referências a Secrets em volumes são validadas para garantir que o objeto
especificado realmente existe e é um objeto do tipo Secret. Portanto, um Secret
precisa ser criado antes de quaisquer Pods que dependam deste.
Objetos Secret residem em um namespace.
Secrets podem ser referenciados somente por Pods no mesmo namespace.
Secrets individuais são limitados ao tamanho de 1MiB. Esta limitação ter por
objetivo desencorajar a criação de Secrets muito grandes que poderiam exaurir
a memória do servidor da API e do kubelet. No entanto, a criação de muitos
Secrets pequenos também pode exaurir a memória. Limites mais completos de uso
de memória em função de Secrets é uma funcionalidade prevista para o futuro.
O kubelet suporta apenas o uso de Secrets em Pods onde os Secrets são obtidos
do servidor da API. Isso inclui quaisquer Pods criados usando o comando
kubectl, ou indiretamente através de um controlador de replicação, mas não
inclui Pods criados como resultado das flags --manifest-url e --config do
kubelet, ou a sua API REST (estas são formas incomuns de criar um Pod).
A spec de um Pod estático
não pode se referir a um Secret ou a qualquer outro objeto da API.
Secrets precisam ser criados antes de serem consumidos em Pods como variáveis de
ambiente, exceto quando são marcados como opcionais. Referências a Secrets que
não existem provocam falhas na inicialização do Pod.
Referências (campo secretKeyRef) a chaves que não existem em um Secret nomeado
provocam falhas na inicialização do Pod.
Secrets utilizados para popular variáveis de ambiente através do campo envFrom
que contém chaves inválidas para utilização como nome de uma variável de ambiente
terão tais chaves ignoradas. O Pod inicializará normalmente. Porém, um evento
será gerado com a razão InvalidVariableNames e a mensagem gerada conterá a lista
de chaves inválidas que foram ignoradas. O exemplo abaixo demonstra um Pod que se
refere ao Secret default/mysecret, contendo duas chaves inválidas: 1badkey e
2alsobad.
kubectl get events
O resultado é semelhante a:
LASTSEEN FIRSTSEEN COUNT NAME KIND SUBOBJECT TYPE REASON
0s 0s 1 dapi-test-pod Pod Warning InvalidEnvironmentVariableNames kubelet, 127.0.0.1 Keys [1badkey, 2alsobad] from the EnvFrom secret default/mysecret were skipped since they are considered invalid environment variable names.
Interações do ciclo de vida entre Secrets e Pods
Quando um Pod é criado através de chamadas à API do Kubernetes, não há validação
da existência de um Secret referenciado. Uma vez que um Pod seja agendado, o
kubelet tentará buscar o valor do Secret. Se o Secret não puder ser encontrado
porque não existe ou porque houve uma falha de comunicação temporária entre o
kubelet e o servidor da API, o kubelet fará novas tentativas periodicamente.
O kubelet irá gerar um evento sobre o Pod, explicando a razão pela qual o Pod
ainda não foi inicializado. Uma vez que o Secret tenha sido encontrado, o
kubelet irá criar e montar um volume contendo este Secret. Nenhum dos contêineres
do Pod irá iniciar até que todos os volumes estejam montados.
Casos de uso
Caso de uso: Como variáveis de ambiente em um contêiner
Utilize envFrom para definir todos os dados do Secret como variáveis de
ambiente do contêiner. Cada chave do Secret se torna o nome de uma variável de
ambiente no Pod.
Você também pode criar um manifesto kustomization.yaml com um campo
secretGenerator contendo chaves SSH.
Cuidado: Analise cuidadosamente antes de enviar suas próprias chaves SSH: outros usuários
do cluster podem ter acesso a este Secret. Utilize uma service account que você
deseje que seja acessível a todos os usuários com os quais você compartilha o
cluster do Kubernetes em questão. Desse modo, você pode revogar esta service
account caso os usuários sejam comprometidos.
Agora você pode criar um Pod que referencia o Secret com a chave SSH e consome-o
em um volume:
O contêiner então pode utilizar os dados do secret para estabelecer uma conexão
SSH.
Caso de uso: Pods com credenciais de ambientes de produção ou testes
Este exemplo ilustra um Pod que consome um Secret contendo credenciais de um
ambiente de produção e outro Pod que consome um Secret contendo credenciais de
um ambiente de testes.
Você pode criar um manifesto kustomization.yaml com um secretGenerator ou
rodar kubectl create secret.
Caracteres especiais como $, \, *, + e ! serão interpretados pelo seu
shell e precisam de
sequências de escape. Na maioria dos shells, a forma mais fácil de gerar sequências
de escape para suas senhas é escrevê-las entre aspas simples ('). Por exemplo,
se a sua senha for S!B\*d$zDsb=, você deve executar o comando da seguinte
forma:
Observe como as specs para cada um dos Pods diverge somente em um campo. Isso
facilita a criação de Pods com capacidades diferentes a partir de um template
mais genérico.
Você pode simplificar ainda mais a definição básica do Pod através da utilização
de duas service accounts diferentes:
Você pode fazer com que seus dados fiquem "ocultos" definindo uma chave que se
inicia com um ponto (.). Este tipo de chave representa um dotfile, ou
arquivo "oculto". Por exemplo, quando o Secret abaixo é montado em um volume,
secret-volume:
Este volume irá conter um único arquivo, chamado .secret-file, e o contêiner
dotfile-test-container terá este arquivo presente no caminho
/etc/secret-volume/.secret-file.
Nota: Arquivos com nomes iniciados por um caractere de ponto são ocultos do resultado
do comando ls -l. Você precisa utilizar ls -la para vê-los ao listar o
conteúdo de um diretório.
Caso de uso: Secret visível somente em um dos contêineres de um pod
Suponha que um programa necessita manipular requisições HTTP, executar regras
de negócio complexas e então assinar mensagens com HMAC. Devido à natureza
complexa da aplicação, pode haver um exploit despercebido que lê arquivos
remotos no servidor e que poderia expor a chave privada para um invasor.
Esta aplicação poderia ser dividida em dois processos, separados em dois
contêineres distintos: um contêiner de front-end, que manipula as interações
com o usuário e a lógica de negócio, mas não consegue ver a chave privada; e
um contêiner assinador, que vê a chave privada e responde a requisições simples
de assinatura do front-end (por exemplo, através de rede local).
Com essa abordagem particionada, um invasor agora precisa forçar o servidor de
aplicação a rodar comandos arbitrários, o que é mais difícil de ser feito do que
apenas ler um arquivo presente no disco.
Melhores práticas
Clientes que utilizam a API de Secrets
Ao instalar aplicações que interajam com a API de Secrets, você deve limitar o
acesso utilizando políticas de autorização
como RBAC.
Secrets frequentemente contém valores com um espectro de importância, muitos dos
quais podem causar escalações dentro do Kubernetes (por exemplo, tokens de service
account) e de sistemas externos. Mesmo que um aplicativo individual possa
avaliar o poder do Secret com o qual espera interagir, outras aplicações dentro
do mesmo namespace podem tornar estas suposições inválidas.
Por estas razões, as requisições watch (observar) e list (listar) de
Secrets dentro de um namespace são permissões extremamente poderosas e devem
ser evitadas, pois a listagem de Secrets permite a clientes inspecionar os
valores de todos os Secrets presentes naquele namespace. A habilidade de listar
e observar todos os Secrets em um cluster deve ser reservada somente para os
componentes mais privilegiados, que fazem parte do nível de aplicações de sistema.
Aplicações que necessitam acessar a API de Secret devem realizar uma requisição
get nos Secrets que precisam. Isto permite que administradores restrinjam o
acesso a todos os Secrets, enquanto
utilizam uma lista de autorização a instâncias individuais
que a aplicação precise.
Para melhor desempenho em uma requisição get repetitiva, clientes podem criar
objetos que referenciam o Secret e então utilizar a requisição watch neste
novo objeto, requisitando o Secret novamente quando a referência mudar.
Além disso, uma API de "observação em lotes"
para permitir a clientes observar recursos individuais também foi proposta e
provavelmente estará disponível em versões futuras do Kubernetes.
Propriedades de segurança
Proteções
Como Secrets podem ser criados de forma independente de Pods que os utilizam,
há menos risco de um Secret ser exposto durante o fluxo de trabalho de criação,
visualização, e edição de Pods. O sistema pode também tomar precauções adicionais
com Secrets, como por exemplo evitar que sejam escritos em disco quando possível.
Um Secret só é enviado para um nó se um Pod naquele nó requerê-lo. O kubelet
armazena o Secret num sistema de arquivos tmpfs, de forma a evitar que o Secret
seja escrito em armazenamento persistente. Uma vez que o Pod que depende do
Secret é removido, o kubelet apaga sua cópia local do Secret também.
Secrets de vários Pods diferentes podem existir no mesmo nó. No entanto, somente
os Secrets que um Pod requerer estão potencialmente visíveis em seus contêineres.
Portanto, um Pod não tem acesso aos Secrets de outro Pod.
Um Pod pode conter vários contêineres. Porém, cada contêiner em um Pod precisa
requerer o volume de Secret nos seus volumeMounts para que este fique visível
dentro do contêiner. Esta característica pode ser utilizada para construir
partições de segurança ao nível do Pod.
Na maioria das distribuições do Kubernetes, a comunicação entre usuários e o
servidor da API e entre servidor da API e os kubelets é protegida por SSL/TLS.
Secrets são protegidos quando transmitidos através destes canais.
FEATURE STATE:Kubernetes v1.13 [beta]
Você pode habilitar encriptação em disco
em dados de Secret para evitar que estes sejam armazenados em texto plano no
etcd.
Riscos
No servidor da API, os dados de Secret são armazenados no
etcd; portanto:
Administradores devem habilitar encriptação em disco para dados do cluster
(requer Kubernetes v1.13 ou posterior).
Administradores devem limitar o acesso ao etcd somente para usuários
administradores.
Administradores podem desejar apagar definitivamente ou destruir discos
previamente utilizados pelo etcd que não estiverem mais em uso.
Ao executar o etcd em um cluster, administradores devem garantir o uso de
SSL/TLS para conexões ponto-a-ponto do etcd.
Se você configurar um Secret utilizando um arquivo de manifesto (JSON ou
YAML) que contém os dados do Secret codificados como base64, compartilhar
este arquivo ou salvá-lo num sistema de controle de versão de código-fonte
compromete este Secret. Codificação base64 não é um método de encriptação
e deve ser considerada idêntica a texto plano.
Aplicações ainda precisam proteger o valor do Secret após lê-lo de um volume,
como por exemplo não escrever seu valor em logs ou enviá-lo para um sistema
não-confiável.
Um usuário que consegue criar um Pod que utiliza um Secret também consegue
ler o valor daquele Secret. Mesmo que o servidor da API possua políticas para
impedir que aquele usuário leia o valor do Secret, o usuário poderia criar um
Pod que expõe o Secret.
3.6.4 - Organizando o acesso ao cluster usando arquivos kubeconfig
Utilize arquivos kubeconfig para organizar informações sobre clusters, usuários, namespaces e mecanismos de autenticação. A ferramenta de linha de comando kubectl faz uso dos arquivos kubeconfig para encontrar as informações necessárias para escolher e se comunicar com o serviço de API de um cluster.
Nota: Um arquivo que é utilizado para configurar o acesso aos clusters é chamado de kubeconfig. Esta á uma forma genérica de referenciamento para um arquivo de configuração desta natureza. Isso não significa que existe um arquivo com o nome kubeconfig.
Por padrão, o kubectl procura por um arquivo de nome config no diretório $HOME/.kube
Você pode especificar outros arquivos kubeconfig através da variável de ambiente KUBECONFIG ou adicionando a opção --kubeconfig.
Suportando múltiplos clusters, usuários e mecanismos de autenticação
Imagine que você possua inúmeros clusters, e seus usuários e componentes se autenticam de várias formas. Por exemplo:
Um kubelet ativo pode se autenticar utilizando certificados
Um usuário pode se autenticar através de tokens
Administradores podem possuir conjuntos de certificados os quais provém acesso aos usuários de forma individual.
Através de arquivos kubeconfig, você pode organizar os seus clusters, usuários, e namespaces. Você também pode definir contextos para uma fácil troca entre clusters e namespaces.
Contexto
Um elemento de contexto em um kubeconfig é utilizado para agrupar parâmetros de acesso em um nome conveniente. Cada contexto possui três parâmetros: cluster, namespace, e usuário.
Por padrão, a ferramenta de linha de comando kubectl utiliza os parâmetros do contexto atual para se comunicar com o cluster.
Para escolher o contexto atual:
kubectl config use-context
A variável de ambiente KUBECONFIG
A variável de ambiente KUBECONFIG possui uma lista dos arquivos kubeconfig. Para Linux e Mac, esta lista é delimitada por vírgula. No Windows, a lista é delimitada por ponto e vírgula. A variável de ambiente KUBECONFIG não é um requisito obrigatório - caso ela não exista o kubectl utilizará o arquivo kubeconfig padrão localizado no caminho $HOME/.kube/config.
Se a variável de ambiente KUBECONFIG existir, o kubectl utilizará uma configuração que é o resultado da combinação dos arquivos listados na variável de ambiente KUBECONFIG.
Combinando arquivos kubeconfig
Para inspecionar a sua configuração atual, execute o seguinte comando:
kubectl config view
Como descrito anteriormente, a saída poderá ser resultado de um único arquivo kubeconfig, ou poderá ser o resultado da junção de vários arquivos kubeconfig.
Aqui estão as regras que o kubectl utiliza quando realiza a combinação de arquivos kubeconfig:
Se o argumento --kubeconfig está definido, apenas o arquivo especificado será utilizado. Apenas uma instância desta flag é permitida.
Caso contrário, se a variável de ambiente KUBECONFIG estiver definida, esta deverá ser utilizada como uma lista de arquivos a serem combinados, seguindo o fluxo a seguir:
Ignorar arquivos vazios.
Produzir erros para aquivos cujo conteúdo não for possível desserializar.
O primeiro arquivo que definir um valor ou mapear uma chave determinada, será o escolhido.
Nunca modificar um valor ou mapear uma chave.
Exemplo: Preservar o contexto do primeiro arquivo que definir current-context.
Exemplo: Se dois arquivos especificarem um red-user, use apenas os valores do primeiro red-user. Mesmo se um segundo arquivo possuir entradas não conflitantes sobre a mesma entrada red-user, estas deverão ser descartadas.
Caso contrário, utilize o arquivo kubeconfig padrão encontrado no diretório $HOME/.kube/config, sem qualquer tipo de combinação.
Determine o contexto a ser utilizado baseado no primeiro padrão encontrado, nesta ordem:
Usar o conteúdo da flag --context caso ela existir.
Usar o current-context a partir da combinação dos arquivos kubeconfig.
Um contexto vazio é permitido neste momento.
Determinar o cluster e o usuário. Neste ponto, poderá ou não existir um contexto.
Determinar o cluster e o usuário no primeiro padrão encontrado de acordo com a ordem à seguir. Este procedimento deverá executado duas vezes: uma para definir o usuário a outra para definir o cluster.
Utilizar a flag caso ela existir: --user ou --cluster.
Se o contexto não estiver vazio, utilizar o cluster ou usuário deste contexto.
O usuário e o cluster poderão estar vazios neste ponto.
Determinar as informações do cluster atual a serem utilizadas. Neste ponto, poderá ou não existir informações de um cluster.
Construir cada peça de informação do cluster baseado nas opções à seguir; a primeira ocorrência encontrada será a opção vencedora:
Usar as flags de linha de comando caso existirem: --server, --certificate-authority, --insecure-skip-tls-verify.
Se algum atributo do cluster existir a partir da combinação de kubeconfigs, estes deverão ser utilizados.
Se não existir informação de localização do servidor falhar.
Determinar a informação atual de usuário a ser utilizada. Construir a informação de usuário utilizando as mesmas regras utilizadas para o caso de informações de cluster, exceto para a regra de técnica de autenticação que deverá ser única por usuário:
Usar as flags, caso existirem: --client-certificate, --client-key, --username, --password, --token.
Usar os campos user resultado da combinação de arquivos kubeconfig.
Se existirem duas técnicas conflitantes, falhar.
Para qualquer informação que ainda estiver ausente, utilizar os valores padrão e potencialmente solicitar informações de autenticação a partir do prompt de comando.
Referências de arquivos
Arquivos e caminhos referenciados em um arquivo kubeconfig são relativos à localização do arquivo kubeconfig.
Referências de arquivos na linha de comando são relativas ao diretório de trabalho vigente.
No arquivo $HOME/.kube/config, caminhos relativos são armazenados de forma relativa, e caminhos absolutos são armazenados de forma absoluta.
Esta visão geral define um modelo para pensar sobre a segurança em Kubernetes no contexto da Segurança em Cloud Native.
Aviso: Este modelo de segurança no contêiner fornece sugestões, não prova políticas de segurança da informação.
Os 4C da Segurança Cloud Native
Você pode pensar na segurança em camadas. Os 4C da segurança Cloud Native são a Cloud,
Clusters, Contêineres e Código.
Nota: Esta abordagem em camadas aumenta a defesa em profundidade
para segurança, que é amplamente considerada como uma boa prática de segurança para software de sistemas.
Os 4C da Segurança Cloud Native
Cada camada do modelo de segurança Cloud Native é construída sobre a próxima camada mais externa.
A camada de código se beneficia de uma base forte (Cloud, Cluster, Contêiner) de camadas seguras.
Você não pode proteger contra padrões ruins de segurança nas camadas de base através de
segurança no nível do Código.
Cloud
De muitas maneiras, a Cloud (ou servidores co-localizados, ou o datacenter corporativo) é a
base de computação confiável
de um cluster Kubernetes. Se a camada de Cloud é vulnerável (ou
configurado de alguma maneira vulnerável), então não há garantia de que os componentes construídos
em cima desta base estejam seguros. Cada provedor de Cloud faz recomendações de segurança
para executar as cargas de trabalho com segurança nos ambientes.
Segurança no provedor da Cloud
Se você estiver executando um cluster Kubernetes em seu próprio hardware ou em um provedor de nuvem diferente,
consulte sua documentação para melhores práticas de segurança.
Aqui estão os links para as documentações de segurança dos provedores mais populares de nuvem:
Sugestões para proteger sua infraestrutura em um cluster Kubernetes:
Infrastructure security
Área de Interesse para Infraestrutura Kubernetes
Recomendação
Acesso de rede ao servidor API (Control plane)
Todo o acesso ao control plane do Kubernetes publicamente na Internet não é permitido e é controlado por listas de controle de acesso à rede restritas ao conjunto de endereços IP necessários para administrar o cluster.
Acesso de rede aos Nós (nodes)
Os nós devem ser configurados para só aceitar conexões (por meio de listas de controle de acesso à rede) do control plane nas portas especificadas e aceitar conexões para serviços no Kubernetes do tipo NodePort e LoadBalancer. Se possível, esses nós não devem ser expostos inteiramente na Internet pública.
Acesso do Kubernetes à API do provedor de Cloud
Cada provedor de nuvem precisa conceder um conjunto diferente de permissões para o control plane e nós do Kubernetes. É melhor fornecer ao cluster permissão de acesso ao provedor de nuvem que segue o princípio do menor privilégio para os recursos que ele precisa administrar. A documentação do Kops fornece informações sobre as políticas e roles do IAM.
Acesso ao etcd
O acesso ao etcd (o armazenamento de dados do Kubernetes) deve ser limitado apenas ao control plane. Dependendo de sua configuração, você deve tentar usar etcd sobre TLS. Mais informações podem ser encontradas na documentação do etcd.
Encriptação etcd
Sempre que possível, é uma boa prática encriptar todas as unidades de armazenamento, mas como o etcd mantém o estado de todo o cluster (incluindo os Secrets), seu disco deve ser criptografado.
Cluster
Existem duas áreas de preocupação para proteger o Kubernetes:
Protegendo os componentes do cluster que são configuráveis.
Protegendo as aplicações que correm no cluster.
Componentes do Cluster
Se você deseja proteger seu cluster de acesso acidental ou malicioso e adotar
boas práticas de informação, leia e siga os conselhos sobre
protegendo seu cluster.
Componentes no cluster (sua aplicação)
Dependendo da superfície de ataque de sua aplicação, você pode querer se concentrar em
tópicos específicos de segurança. Por exemplo: se você estiver executando um serviço (Serviço A) que é crítico
numa cadeia de outros recursos e outra carga de trabalho separada (Serviço B) que é
vulnerável a um ataque de exaustão de recursos e, por consequência, o risco de comprometer o Serviço A
é alto se você não limitar os recursos do Serviço B. A tabela a seguir lista
áreas de atenção na segurança e recomendações para proteger cargas de trabalho em execução no Kubernetes:
A segurança do contêiner está fora do escopo deste guia. Aqui estão recomendações gerais e
links para explorar este tópico:
Área de Interesse para Contêineres
Recomendação
Scanners de Vulnerabilidade de Contêiner e Segurança de Dependência de SO
Como parte da etapa de construção de imagem, você deve usar algum scanner em seus contêineres em busca de vulnerabilidades.
Assinatura Imagem e Enforcement
Assinatura de imagens de contêineres para manter um sistema de confiança para o conteúdo de seus contêineres.
Proibir Usuários Privilegiados
Ao construir contêineres, consulte a documentação para criar usuários dentro dos contêineres que tenham o menor nível de privilégio no sistema operacional necessário para cumprir o objetivo do contêiner.
Use o Contêiner em Runtime com Isolamento mais Forte
O código da aplicação é uma das principais superfícies de ataque sobre a qual você tem maior controle.
Embora a proteção do código do aplicativo esteja fora do tópico de segurança do Kubernetes, aqui
são recomendações para proteger o código do aplicativo:
Segurança de código
Code security
Área de Atenção para o Código
Recomendação
Acesso só através de TLS
Se seu código precisar se comunicar por TCP, execute um handshake TLS com o cliente antecipadamente. Com exceção de alguns casos, encripte tudo em trânsito. Indo um passo adiante, é uma boa ideia encriptar o tráfego de rede entre os serviços. Isso pode ser feito por meio de um processo conhecido como mutual ou mTLS, que realiza uma verificação bilateral da comunicação mediante os certificados nos serviços.
Limitando intervalos de porta de comunicação
Essa recomendação pode ser um pouco autoexplicativa, mas, sempre que possível, você só deve expor as portas em seu serviço que são absolutamente essenciais para a comunicação ou coleta de métricas.
Segurança na Dependência de Terceiros
É uma boa prática verificar regularmente as bibliotecas de terceiros de sua aplicação em busca de vulnerabilidades de segurança. Cada linguagem de programação possui uma ferramenta para realizar essa verificação automaticamente.
Análise de Código Estático
A maioria das linguagens fornece uma maneira para analisar um extrato do código referente a quaisquer práticas de codificação potencialmente inseguras. Sempre que possível, você deve automatizar verificações usando ferramentas que podem verificar as bases de código em busca de erros de segurança comuns. Algumas das ferramentas podem ser encontradas em OWASP Source Code Analysis Tools.
Ataques de sondagem dinâmica
Existem algumas ferramentas automatizadas que você pode executar contra seu serviço para tentar alguns dos ataques mais conhecidos. Isso inclui injeção de SQL, CSRF e XSS. Uma das ferramentas de análise dinâmica mais populares é o OWASP Zed Attack proxy.
Próximos passos
Saiba mais sobre os tópicos de segurança do Kubernetes:
No Kubernetes, agendamento refere-se a garantia de que os pods correspondam aos nós para que o kubelet possa executá-los. Remoção é o processo de falha proativa de um ou mais pods em nós com falta de recursos.
3.8.1 - Taints e Tolerâncias
Afinidade de nó
é uma propriedade dos Pods que os associa a um conjunto de nós (seja como uma preferência ou uma exigência). Taints são o oposto -- eles permitem que um nó repudie um conjunto de pods.
Tolerâncias são aplicadas em pods e permitem, mas não exigem, que os pods sejam alocados em nós com taints correspondentes.
Taints e tolerâncias trabalham juntos para garantir que pods não sejam alocados em nós inapropriados. Um ou mais taints são aplicados em um nó; isso define que o nó não deve aceitar nenhum pod que não tolera essas taints.
Conceitos
Você adiciona um taint a um nó utilizando kubectl taint.
Por exemplo,
kubectl taint nodes node1 key1=value1:NoSchedule
define um taint no nó node1. O taint tem a chave key1, valor value1 e o efeito NoSchedule.
Isso significa que nenhum pod conseguirá ser executado no nó node1 a menos que possua uma tolerância correspondente.
Para remover o taint adicionado pelo comando acima, você pode executar:
kubectl taint nodes node1 key1=value1:NoSchedule-
Você especifica uma tolerância para um pod na especificação do Pod. Ambas as seguintes tolerâncias "correspondem" ao taint criado pelo kubectl taint acima, e assim um pod com qualquer uma delas poderia ser executado no node1:
Uma tolerância "casa" um taint se as chaves e efeitos são os mesmos, e:
o valor de operator é Exists (no caso nenhum value deve ser especificado), ou
o valor de operator é Equal e os valores de value são iguais.
Nota:
Existem dois casos especiais:
Uma key vazia com o operador Exists "casa" todas as chaves, valores e efeitos, o que significa que o pod irá tolerar tudo.
Um effect vazio "casa" todos os efeitos com a chave key1.
O exemplo acima usou effect de NoSchedule. De forma alternativa, você pode usar effect de PreferNoSchedule.
Nesse efeito, o sistema tentará evitar que o pod seja alocado ao nó caso ele não tolere os taints definidos, contudo a alocação não será evitada de forma obrigatória. Pode-se dizer que o PreferNoSchedule é uma versão permissiva do NoSchedule. O terceiro tipo de effect é o NoExecute que será descrito posteriormente.
Você pode colocar múltiplos taints no mesmo nó e múltiplas tolerâncias no mesmo pod.
O jeito que o Kubernetes processa múltiplos taints e tolerâncias é como um filtro: começa com todos os taints de um nó, em seguida ignora aqueles para os quais o pod tem uma tolerância relacionada; os taints restantes que não foram ignorados indicam o efeito no pod. Mais especificamente,
se existe pelo menos um taint não tolerado com o efeito NoSchedule, o Kubernetes não alocará o pod naquele nó
se existe um taint não tolerado com o efeito NoSchedule, mas existe pelo menos um taint não tolerado com o efeito PreferNoSchedule, o Kubernetes tentará não alocar o pod no nó
se existe pelo menos um taint não tolerado com o efeito NoExecute, o pod será expulso do nó (caso já esteja em execução) e não será alocado ao nó (caso ainda não esteja em execução).
Por exemplo, imagine que você tem um nó com os seguintes taints
Nesse caso, o pod não será alocado ao nó porque não possui uma tolerância para o terceiro taint. Porém, se ele já estiver rodando no nó quando o taint foi adicionado, não será afetado e continuará rodando, tendo em vista que o terceiro taint é o único não tolerado pelo pod.
Normalmente, se um taint com o efeito NoExecute é adicionado a um nó, qualquer pod que não o tolere será expulso imediatamente e pods que o toleram nunca serão expulsos. Contudo, uma tolerância com efeito NoExecute pode especificar de forma opcional o campo tolerationSeconds, que determina quanto tempo o pod continuará alocado ao nó depois que o taint é adicionado. Por exemplo,
significa que se esse pod está sendo executado e um taint correspondente é adicionado ao nó, o pod irá continuar rodando neste nó por 3600 segundos e depois será expulso. Se o taint for removido antes desse tempo acabar, o pod não será expulso.
Exemplos de Casos de Uso
Taints e tolerâncias são um modo flexível de conduzir pods para fora dos nós ou expulsar pods que não deveriam estar sendo executados. Alguns casos de uso são
Nós Dedicados: Se você quiser dedicar um conjunto de nós para uso exclusivo de um conjunto específico de usuários, poderá adicionar um taint nesses nós. (digamos, kubectl taint nodes nodename dedicated=groupName:NoSchedule) e em seguida adicionar uma tolerância correspondente para seus pods (isso seria feito mais facilmente com a escrita de um controlador de admissão customizado).
Os pods com tolerância terão sua execução permitida nos nós com taints (dedicados), assim como em qualquer outro nó no cluster. Se você quiser dedicar nós a esses pods e garantir que eles usem apenas os nós dedicados, precisará adicionar uma label similar ao taint para o mesmo conjunto de nós (por exemplo, dedicated=groupName), e o controle de admissão deverá adicionar uma afinidade de nó para exigir que os pods podem ser executados apenas nos nós definidos com a label dedicated=groupName.
Nós com hardware especial: Em um cluster no qual um pequeno grupo de nós possui hardware especializado (por exemplo, GPUs), é desejável manter pods que não necessitem desse tipo de hardware fora desses nós, dessa forma o recurso estará disponível para pods que precisem do hardware especializado. Isso pode ser feito aplicando taints nos nós com o hardware especializado (por exemplo, kubectl taint nodes nodename special=true:NoSchedule or kubectl taint nodes nodename special=true:PreferNoSchedule) e aplicando uma tolerância correspondente nos pods que usam o hardware especial. Assim como no caso de uso de nós dedicados, é provavelmente mais fácil aplicar as tolerâncias utilizando um controlador de admissão.
Por exemplo, é recomendado usar Extended Resources para representar hardware especial, adicione um taint ao seus nós de hardware especializado com o nome do recurso estendido e execute o controle de admissão ExtendedResourceToleration. Agora, tendo em vista que os nós estão marcados com um taint, nenhum pod sem a tolerância será executado neles. Porém, quando você submete um pod que requisita o recurso estendido, o controlador de admissão ExtendedResourceToleration irá adicionar automaticamente as tolerâncias necessárias ao pod que irá, por sua vez, ser alocado no nó com hardware especial. Isso garantirá que esses nós de hardware especial serão dedicados para os pods que requisitarem tal recurso e você não precisará adicionar manualmente as tolerâncias aos seus pods.
Expulsões baseadas em Taint: Um comportamento de expulsão configurada por pod quando problemas existem em um nó, o qual será descrito na próxima seção.
Expulsões baseadas em Taint
FEATURE STATE:Kubernetes v1.18 [stable]
O efeito de taint NoExecute, mencionado acima, afeta pods que já estão rodando no nó da seguinte forma
pods que não toleram o taint são expulsos imediatamente
pods que toleram o taint sem especificar tolerationSeconds em sua especificação de tolerância, ficam alocados para sempre
pods que toleram o taint com um tolerationSeconds especificado, permanecem alocados pela quantidade de tempo definida
O controlador de nó automaticamente adiciona um taint ao Nó quando certas condições se tornam verdadeiras. Os seguintes taints são embutidos:
node.kubernetes.io/not-ready: Nó não está pronto. Isso corresponde ao NodeCondition Ready com o valor "False".
node.kubernetes.io/unreachable: Nó é inalcançável a partir do controlador de nó. Isso corresponde ao NodeCondition Ready com o valor "Unknown".
node.kubernetes.io/memory-pressure: Nó possui pressão de memória.
node.kubernetes.io/disk-pressure: Nó possui pressão de disco.
node.kubernetes.io/pid-pressure: Nó possui pressão de PID.
node.kubernetes.io/network-unavailable: A rede do nó está indisponível.
node.kubernetes.io/unschedulable: Nó não é alocável.
node.cloudprovider.kubernetes.io/uninitialized: Quando o kubelet é iniciado com um provedor de nuvem "externo", esse taint é adicionado ao nó para que ele seja marcado como não utilizável. Após o controlador do cloud-controller-manager inicializar o nó, o kubelet remove esse taint.
No caso de um nó estar prestes a ser expulso, o controlador de nó ou kubelet adicionam os taints relevantes com o efeito NoExecute. Se a condição de falha retorna ao normal, o kubelet ou controlador de nó podem remover esses taints.
Nota: A camada de gerenciamento limita a taxa de adição de novos taints aos nós. Esse limite gerencia o número de expulsões que são disparadas quando muitos nós se tornam inalcançáveis ao mesmo tempo (por exemplo: se ocorre uma falha na rede).
Você pode especificar tolerationSeconds em um Pod para definir quanto tempo ele ficará alocado em um nó que está falhando ou está sem resposta.
Por exemplo, você talvez queira manter uma aplicação com vários estados salvos localmente alocado em um nó por um longo período na ocorrência de uma divisão na rede, esperando que essa divisão se recuperará e assim a expulsão do pod pode ser evitada.
A tolerância que você define para esse Pod poderia ficar assim:
O Kubernetes automaticamente adiciona uma tolerância para node.kubernetes.io/not-ready e node.kubernetes.io/unreachable com tolerationSeconds=300, a menos que você, ou um controlador, defina essas tolerâncias explicitamente.
Essas tolerâncias adicionadas automaticamente significam que Pods podem continuar alocados aos Nós por 5 minutos após um desses problemas ser detectado.
Pods do tipo DaemonSet são criados com tolerâncias NoExecute sem a propriedade tolerationSeconds para os seguintes taints:
node.kubernetes.io/unreachable
node.kubernetes.io/not-ready
Isso garante que esses pods do DaemonSet nunca sejam expulsos por conta desses problemas.
Taints por condições de nó
A camada de gerenciamento, usando o controlador do nó, cria taints automaticamente com o efeito NoSchedule para condições de nó.
O agendador verifica taints, não condições de nó, quando realiza suas decisões de agendamento. Isso garante que as condições de nó não afetem diretamente o agendamento.
Por exemplo, se a condição de nó DiskPressure está ativa, a camada de gerenciamento adiciona o taint node.kubernetes.io/disk-pressure e não aloca novos pods no nó afetado. Se a condição MemoryPressure está ativa, a camada de gerenciamento adiciona o taint node.kubernetes.io/memory-pressure.
Você pode ignorar condições de nó para pods recém-criados adicionando tolerâncias correspondentes. A camada de controle também adiciona a tolerância node.kubernetes.io/memory-pressure em pods que possuem uma classe de QoS diferente de BestEffort. Isso ocorre porque o Kubernetes trata pods nas classes de QoS Guaranteed ou Burstable (até mesmo pods sem requisitos de memória definidos) como se fossem capazes de lidar com pressão de memória, enquanto novos pods com BestEffort não são alocados no nó afetado.
O controlador DaemonSet adiciona automaticamente as seguintes tolerâncias de NoSchedule para todos os daemons, prevenindo que DaemonSets quebrem.
node.kubernetes.io/memory-pressure
node.kubernetes.io/disk-pressure
node.kubernetes.io/pid-pressure (1.14 ou superior)
node.kubernetes.io/unschedulable (1.10 ou superior)
node.kubernetes.io/network-unavailable (somente rede do host)
Adicionando essas tolerâncias garante retro compatibilidade. Você também pode adicionar tolerâncias de forma arbitrária aos DaemonSets.
No Kubernetes, escalonamento refere-se a garantir que os Pods
sejam correspondidos aos Nodes para que o
Kubelet possa executá-los.
Visão geral do Escalonamento
Um escalonador observa Pods recém-criados que não possuem um Node atribuído.
Para cada Pod que o escalonador descobre, ele se torna responsável por
encontrar o melhor Node para execução do Pod. O escalonador chega a essa decisão de alocação levando em consideração os princípios de programação descritos abaixo.
Se você quiser entender por que os Pods são alocados em um Node específico
ou se planeja implementar um escalonador personalizado, esta página ajudará você a
aprender sobre escalonamento.
kube-scheduler
kube-scheduler
é o escalonador padrão do Kubernetes e é executado como parte do
control plane.
O kube-scheduler é projetado para que, se você quiser e precisar, possa
escrever seu próprio componente de escalonamento e usá-lo.
Para cada Pod recém-criado ou outros Pods não escalonados, o kube-scheduler
seleciona um Node ideal para execução. No entanto, todos os contêineres nos Pods
têm requisitos diferentes de recursos e cada Pod também possui requisitos diferentes.
Portanto, os Nodes existentes precisam ser filtrados de acordo com os requisitos de
escalonamento específicos.
Em um cluster, Nodes que atendem aos requisitos de escalonamento para um Pod
são chamados de Nodes viáveis. Se nenhum dos Nodes for adequado, o Pod
permanece não escalonado até que o escalonador possa alocá-lo.
O escalonador encontra Nodes viáveis para um Pod e, em seguida, executa um conjunto de
funções para pontuar os Nodes viáveis e escolhe um Node com a maior
pontuação entre os possíveis para executar o Pod. O escalonador então notifica
o servidor da API sobre essa decisão em um processo chamado binding.
Fatores que precisam ser levados em consideração para decisões de escalonamento incluem
requisitos individuais e coletivos de recursos,
restrições de hardware / software / política, especificações de afinidade e anti-afinidade,
localidade de dados, interferência entre cargas de trabalho e assim por diante.
Seleção do Node no kube-scheduler
O kube-scheduler seleciona um Node para o Pod em uma operação que consiste em duas etapas:
Filtragem
Pontuação
A etapa de filtragem localiza o conjunto de Nodes onde é possível
alocar o Pod. Por exemplo, o filtro PodFitsResources verifica se um Node
candidato possui recursos disponíveis suficientes para atender às solicitações
de recursos específicas de um Pod. Após esta etapa, a lista de Nodes contém
quaisquer Nodes adequados; frequentemente, haverá mais de um. Se a lista estiver vazia,
esse Pod (ainda) não é escalonável.
Na etapa de pontuação, o escalonador classifica os Nodes restantes para escolher
o mais adequado. O escalonador atribui uma pontuação a cada Node
que sobreviveu à filtragem, baseando essa pontuação nas regras de pontuação ativa.
Por fim, o kube-scheduler atribui o Pod ao Node com a classificação mais alta.
Se houver mais de um Node com pontuações iguais, o kube-scheduler seleciona
um deles aleatoriamente.
Existem duas maneiras suportadas de configurar o comportamento de filtragem e pontuação
do escalonador:
Perfis de Escalonamento permitem configurar Plugins que implementam diferentes estágios de escalonamento, incluindo: QueueSort, Filter, Score, Bind, Reserve, Permit, e outros. Você também pode configurar o kube-scheduler para executar diferentes perfis.
Quando você executa um Pod num nó, o próprio Pod usa uma quantidade de recursos do sistema. Estes
recursos são adicionais aos recursos necessários para executar o(s) contêiner(s) dentro do Pod.
Sobrecarga de Pod, do inglês Pod Overhead, é uma funcionalidade que serve para contabilizar os recursos consumidos pela
infraestrutura do Pod para além das solicitações e limites do contêiner.
No Kubernetes, a sobrecarga de Pods é definido no tempo de
admissão
de acordo com a sobrecarga associada à
RuntimeClass do Pod.
Quando é ativada a Sobrecarga de Pod, a sobrecarga é considerada adicionalmente à soma das
solicitações de recursos do contêiner ao agendar um Pod. Semelhantemente, o kubelet
incluirá a sobrecarga do Pod ao dimensionar o cgroup do Pod e ao
executar a classificação de prioridade de migração do Pod em caso de drain do Node.
Habilitando a Sobrecarga de Pod
Terá de garantir que o Feature GatePodOverhead esteja ativo (está ativo por padrão a partir da versão 1.18)
em todo o cluster, e uma RuntimeClass utilizada que defina o campo overhead.
Exemplo de uso
Para usar a funcionalidade PodOverhead, é necessário uma RuntimeClass que define o campo overhead.
Por exemplo, poderia usar a definição da RuntimeClass abaixo com um agente de execução de contêiner virtualizado
que use cerca de 120MiB por Pod para a máquina virtual e o sistema operacional convidado:
As cargas de trabalho que são criadas e que especificam o manipulador RuntimeClass kata-fc irão
usar a sobrecarga de memória e cpu em conta para os cálculos da quota de recursos, agendamento de nós,
assim como dimensionamento do cgroup do Pod.
Considere executar a seguinte carga de trabalho de exemplo, test-pod:
No tempo de admissão o controlador de admissão RuntimeClass
atualiza o PodSpec da carga de trabalho de forma a incluir o overhead como descrito na RuntimeClass. Se o PodSpec já tiver este campo definido
o Pod será rejeitado. No exemplo dado, como apenas o nome do RuntimeClass é especificado, o controlador de admissão muda o Pod de forma a
incluir um overhead.
Depois do controlador de admissão RuntimeClass, pode verificar o PodSpec atualizado:
kubectl get pod test-pod -o jsonpath='{.spec.overhead}'
A saída é:
map[cpu:250m memory:120Mi]
Se for definido um ResourceQuota, a soma das requisições dos contêineres assim como o campo overhead são contados.
Quando o kube-scheduler está decidindo que nó deve executar um novo Pod, o agendador considera o overhead do pod,
assim como a soma de pedidos aos contêineres para esse Pod. Para este exemplo, o agendador adiciona as requisições e a sobrecarga, depois procura um nó com 2.25 CPU e 320 MiB de memória disponível.
Assim que um Pod é agendado a um nó, o kubelet nesse nó cria um novo cgroup
para o Pod. É dentro deste Pod que o agente de execução de contêiners subjacente vai criar contêineres.
Se o recurso tiver um limite definido para cada contêiner (QoS garantida ou Burstrable QoS com limites definidos),
o kubelet definirá um limite superior para o cgroup do Pod associado a esse recurso (cpu.cfs_quota_us para CPU
e memory.limit_in_bytes de memória). Este limite superior é baseado na soma dos limites do contêiner mais o overhead
definido no PodSpec.
Para CPU, se o Pod for QoS garantida ou Burstrable QoS, o kubelet vai definir cpu.shares baseado na soma dos
pedidos ao contêiner mais o overhead definido no PodSpec.
Olhando para o nosso exemplo, verifique as requisições ao contêiner para a carga de trabalho:
kubectl get pod test-pod -o jsonpath='{.spec.containers[*].resources.limits}'
O total de requisições ao contêiner são 2000m CPU e 200MiB de memória:
Verifique isto comparado ao que é observado pelo nó:
kubectl describe node | grep test-pod -B2
A saída mostra que 2250m CPU e 320MiB de memória são solicitados, que inclui PodOverhead:
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default test-pod 2250m (56%) 2250m (56%) 320Mi (1%) 320Mi (1%) 36m
Verificar os limites cgroup do Pod
Verifique os cgroups de memória do Pod no nó onde a carga de trabalho está em execução. No seguinte exemplo, crictl
é usado no nó, que fornece uma CLI para agentes de execução compatíveis com CRI. Isto é um
exemplo avançado para mostrar o comportamento do PodOverhead, e não é esperado que os usuários precisem verificar
cgroups diretamente no nó.
Primeiro, no nó em particular, determine o identificador do Pod:
# Execute no nó onde o Pod está agendadoPOD_ID="$(sudo crictl pods --name test-pod -q)"
A partir disto, pode determinar o caminho do cgroup para o Pod:
# Execute no nó onde o Pod está agendado
sudo crictl inspectp -o=json $POD_ID | grep cgroupsPath
O caminho do cgroup resultante inclui o contêiner pause do Pod. O cgroup no nível do Pod está um diretório acima.
Neste caso especifico, o caminho do cgroup do Pod é kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2. Verifique a configuração cgroup de nível do Pod para a memória:
# Execute no nó onde o Pod está agendado# Mude também o nome do cgroup para combinar com o cgroup alocado ao Pod.
cat /sys/fs/cgroup/memory/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/memory.limit_in_bytes
Isto é 320 MiB, como esperado:
335544320
Observabilidade
Uma métrica kube_pod_overhead está disponível em kube-state-metrics
para ajudar a identificar quando o PodOverhead está sendo utilizado e para ajudar a observar a estabilidade das cargas de trabalho
em execução com uma sobrecarga (Overhead) definida. Esta funcionalidade não está disponível na versão 1.9 do kube-state-metrics,
mas é esperado em uma próxima versão. Os usuários necessitarão entretanto construir o kube-state-metrics a partir do código fonte.
Detalhes de baixo nível relevantes para criar ou administrar um cluster Kubernetes.
A visão geral da administração do cluster é para qualquer pessoa que crie ou administre um cluster do Kubernetes.
É pressuposto alguma familiaridade com os conceitos principais do Kubernetes.
Planejando um cluster
Consulte os guias em Configuração para exemplos de como planejar, instalar e configurar clusters Kubernetes. As soluções listadas neste artigo são chamadas de distros.
Nota: Nem todas as distros são mantidas ativamente. Escolha distros que foram testadas com uma versão recente do Kubernetes.
Antes de escolher um guia, aqui estão algumas considerações:
Você quer experimentar o Kubernetes em seu computador ou deseja criar um cluster de vários nós com alta disponibilidade? Escolha as distros mais adequadas ás suas necessidades.
Você vai usar um cluster Kubernetes gerenciado , como o Google Kubernetes Engine, ou vai hospedar seu próprio cluster?
Seu cluster será local, ou na nuvem (IaaS)? O Kubernetes não oferece suporte direto a clusters híbridos. Em vez disso, você pode configurar vários clusters.
Se você estiver configurando o Kubernetes local, leve em consideração qual modelo de rede se encaixa melhor.
Você vai executar o Kubernetes em um hardware bare metal ou em máquinas virtuais? (VMs)?
Você deseja apenas executar um cluster ou espera participar ativamente do desenvolvimento do código do projeto Kubernetes? Se for a segunda opção,
escolha uma distro desenvolvida ativamente. Algumas distros usam apenas versão binária, mas oferecem uma maior variedade de opções.
Familiarize-se com os componentes necessários para executar um cluster.
Autenticação explica a autenticação no Kubernetes, incluindo as várias opções de autenticação.
Autorização é separado da autenticação e controla como as chamadas HTTP são tratadas.
Usando Controladores de Admissão explica plugins que interceptam requisições para o servidor da API Kubernetes após
a autenticação e autorização.
usando Sysctl em um Cluster Kubernetes descreve a um administrador como usar a ferramenta de linha de comando sysctl para
definir os parâmetros do kernel.
Auditoria descreve como interagir com logs de auditoria do Kubernetes.
A visão geral da administração de cluster é para qualquer um criando ou administrando um cluster Kubernetes. Assume-se que você tenha alguma familiaridade com os conceitos centrais do Kubernetes.
Planejando um cluster
Veja os guias em Setup para exemplos de como planejar, iniciar e configurar clusters Kubernetes. As soluções listadas neste artigo são chamadas distros.
Antes de escolher um guia, aqui estão algumas considerações.
Você quer experimentar o Kubernetes no seu computador, ou você quer construir um cluster de alta disponibilidade e multi-nós? Escolha as distros mais adequadas às suas necessidades.
Se você esta projetando para alta-disponibilidade, saiba mais sobre configuração clusters em múltiplas zonas.
Você usará um cluster Kubernetes hospedado, como Google Kubernetes Engine, ou hospedará seu próprio cluster?
Seu cluster será on-premises, ou in the cloud (IaaS)? Kubernetes não suporta diretamente clusters híbridos. Em vez disso, você pode configurar vários clusters.
Se você estiver configurando um Kubernetes on-premisess, considere qual modelo de rede melhor se adequa.
Você estará executando o Kubernetes em hardware "bare metal" ou em máquinas virtuais (VMs)?
Você quer apenas rodar um cluster, ou você espera fazer desenvolvimento ativo do código de projeto do Kubernetes? Se for a segunda opção, escolha uma distro mais ativa. Algumas distros fornecem apenas binários, mas oferecem uma maior variedade de opções.
Familiarize-se com os componentes necessários para rodar um cluster.
Nota: Nem todas as distros são ativamente mantidas. Escolha as distros que foram testadas com uma versão recente do Kubernetes.
Gerenciando um cluster
Gerenciando um cluster descreve vários tópicos relacionados ao ciclo de vida de um cluster: criando um novo cluster, atualizando o nó mestre e os nós de trabalho do cluster, executando manutenção de nó (por exemplo, atualizações de kernel) e atualizando a versão da API do Kubernetes de um cluster em execução.
Ao usar um client para autenticação de certificado, você pode gerar certificados
manualmente através easyrsa, openssl ou cfssl.
easyrsa
easyrsa pode gerar manualmente certificados para o seu cluster.
Baixe, descompacte e inicialize a versão corrigida do easyrsa3.
curl -LO https://storage.googleapis.com/kubernetes-release/easy-rsa/easy-rsa.tar.gz
tar xzf easy-rsa.tar.gz
cd easy-rsa-master/easyrsa3
./easyrsa init-pki
Gerar o CA. (--batch set automatic mode. --req-cn default CN to use.)
Gere o certificado e a chave do servidor.
O argumento --subject-alt-name define os possíveis IPs e nomes (DNS) que o servidor de API usará para ser acessado. O MASTER_CLUSTER_IP é geralmente o primeiro IP do serviço CIDR que é especificado como argumento em --service-cluster-ip-range para o servidor de API e o componente gerenciador do controlador. O argumento --days é usado para definir o número de dias após o qual o certificado expira.
O exemplo abaixo também assume que você está usando cluster.local como DNS de domínio padrão
Crie um arquivo de configuração para gerar uma solicitação de assinatura de certificado (CSR - Certificate Signing Request). Certifique-se de substituir os valores marcados com colchetes angulares (por exemplo, <MASTER_IP>) com valores reais antes de salvá-lo em um arquivo (por exemplo, csr.conf). Note que o valor para o MASTER_CLUSTER_IP é o IP do cluster de serviços para o Servidor de API, conforme descrito na subseção anterior. O exemplo abaixo também assume que você está usando cluster.local como DNS de domínio padrão
Por fim, adicione os mesmos parâmetros nos parâmetros iniciais do Servidor de API.
cfssl
cfssl é outra ferramenta para geração de certificados.
Baixe, descompacte e prepare as ferramentas de linha de comando, conforme mostrado abaixo. Observe que você pode precisar adaptar os comandos de exemplo abaixo com base na arquitetura do hardware e versão cfssl que você está usando.
Crie um arquivo de configuração JSON para o CA - solicitação de assinatura de certificado (CSR - Certificate Signing Request), por exemplo, ca-csr.json. Certifique-se de substituir os valores marcados com colchetes angulares por valores reais que você deseja usar.
Gere a chave CA (ca-key.pem) e o certificado ( ca.pem):
../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca
Crie um arquivo de configuração JSON para gerar chaves e certificados para o Servidor de API, por exemplo, server-csr.json. Certifique-se de substituir os valores entre colchetes angulares por valores reais que você deseja usar. O MASTER_CLUSTER_IP é o IP do serviço do cluster para o servidor da API, conforme descrito na subseção anterior. O exemplo abaixo também assume que você está usando cluster.local como DNS de domínio padrão
Um nó cliente pode se recusar a reconhecer o certificado CA self-signed como válido.
Para uma implementação de não produção ou para uma instalação que roda atrás de um firewall, você pode distribuir certificados auto-assinados para todos os clientes e atualizar a lista de certificados válidos.
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
API de certificados
Você pode usar a API certificates.k8s.io para provisionar
certificados x509 a serem usados para autenticação conforme documentado
aqui.
3.9.3 - Conectividade do Cluster
Conectividade é uma parte central do Kubernetes, mas pode ser desafiador
entender exatamente como é o seu funcionamento esperado. Existem 4 problemas
distintos em conectividade que devem ser tratados:
Comunicações contêiner-para-contêiner altamente acopladas: Isso é resolvido
por Pods e comunicações através do localhost.
Comunicações pod-para-pod: Esse é o foco primário desse documento.
Comunicações pod-para-serviço (service): Isso é tratado em Services.
Comunicações Externas-para-serviços: Isso é tratado em services.
Kubernetes é basicamente o compartilhamento de máquinas entre aplicações. Tradicionalmente,
compartilhar máquinas requer a garantia de que duas aplicações não tentem utilizar
as mesmas portas. Coordenar a alocação de portas entre múltiplos desenvolvedores é
muito dificil de fazer em escala e expõe os usuários a problemas em nível do cluster e
fora de seu controle.
A alocação dinâmica de portas traz uma série de complicações para o sistema - toda
aplicação deve obter suas portas através de flags de configuração, os servidores de API
devem saber como inserir números dinämicos de portas nos blocos de configuração, serviços
precisam saber como buscar um ao outro, etc. Ao invés de lidar com isso, o Kubernetes
faz de uma maneira diferente.
O modelo de conectividade e rede do Kubernetes
Todo Pod obtém seu próprio endereço IP. Isso significa que vocë não precisa
criar links explícitos entre os Pods e vocë quase nunca terá que lidar com o
mapeamento de portas de contêineres para portas do host. Isso cria um modelo simples,
retro-compatível onde os Pods podem ser tratados muito mais como VMs ou hosts
físicos da perspectiva de alocação de portas, nomes, descobrimento de serviços
(service discovery), balanceamento de carga, configuração de aplicações e migrações.
O Kubernetes impõe os seguintes requisitos fundamentais para qualquer implementação de
rede (exceto qualquer política de segmentação intencional):
pods em um nó podem se comunicar com todos os pods em todos os nós sem usar NAT.
agentes em um nó (por exemplo o kubelet ou um serviço local) podem se comunicar com
todos os Pods naquele nó.
Nota: Para as plataformas que suportam Pods executando na rede do host (como o Linux):
pods alocados na rede do host de um nó podem se comunicar com todos os pods
em todos os nós sem NAT.
Esse modelo não só é menos complexo, mas é principalmente compatível com o
desejo do Kubernetes de permitir a portabilidade com baixo esforço de aplicações
de VMs para contêineres. Se a sua aplicação executava anteriormente em uma VM, sua VM
possuía um IP e podia se comunicar com outras VMs no seu projeto. Esse é o mesmo
modelo básico.
Os endereços de IP no Kubernetes existem no escopo do Pod - contêineres em um Pod
compartilham o mesmo network namespace - incluíndo seu endereço de IP e MAC.
Isso significa que contêineres que compõem um Pod podem se comunicar entre eles
através do endereço localhost e respectivas portas. Isso também significa que
contêineres em um mesmo Pod devem coordenar a alocação e uso de portas, o que não
difere do modelo de processos rodando dentro de uma mesma VM. Isso é chamado de
modelo "IP-por-pod".
Como isso é implementado é um detalhe do agente de execução de contêiner em uso.
É possível solicitar uma porta no nó que será encaminhada para seu Pod (chamado
de portas do host), mas isso é uma operação muito específica. Como esse encaminhamento
é implementado é um detalhe do agente de execução do contêiner. O Pod mesmo
desconhece a existência ou não de portas do host.
Como implementar o modelo de conectividade do Kubernetes
Existe um número de formas de implementar esse modelo de conectividade. Esse
documento não é um estudo exaustivo desses vários métodos, mas pode servir como
uma introdução de várias tecnologias e serve como um ponto de início.
A conectividade no Kubernetes é fornecida através de plugins de
CNIs
As seguintes opções estão organizadas alfabeticamente e não implicam preferência por
qualquer solução.
Nota:
Esta seção tem links para projetos de terceiros que fornecem a funcionalidade exigida pelo Kubernetes. Os autores do projeto Kubernetes não são responsáveis por esses projetos. Esta página obedece as diretrizes de conteúdo do site CNCF, listando os itens em ordem alfabética. Para adicionar um projeto a esta lista, leia o guia de conteúdo antes de enviar sua alteração.
Antrea
O projeto Antrea é uma solução de
conectividade para Kubernetes que pretende ser nativa. Ela utiliza o Open vSwitch
na camada de conectividade de dados. O Open vSwitch é um switch virtual de alta
performance e programável que suporta Linux e Windows. O Open vSwitch permite
ao Antrea implementar políticas de rede do Kubernetes (NetworkPolicies) de
uma forma muito performática e eficiente.
Graças à característica programável do Open vSwitch, o Antrea consegue implementar
uma série de funcionalidades de rede e segurança.
AWS VPC CNI para Kubernetes
O AWS VPC CNI oferece conectividade
com o AWS Virtual Private Cloud (VPC) para clusters Kubernetes. Esse plugin oferece
alta performance e disponibilidade e baixa latência. Adicionalmente, usuários podem
aplicar as melhores práticas de conectividade e segurança existentes no AWS VPC
para a construção de clusters Kubernetes. Isso inclui possibilidade de usar o
VPC flow logs, políticas de roteamento da VPC e grupos de segurança para isolamento
de tráfego.
O uso desse plugin permite aos Pods no Kubernetes ter o mesmo endereço de IP dentro do
pod como se eles estivessem dentro da rede do VPC. O CNI (Container Network Interface)
aloca um Elastic Networking Interface (ENI) para cada nó do Kubernetes e usa uma
faixa de endereços IP secundário de cada ENI para os Pods no nó. O CNI inclui
controles para pré alocação dos ENIs e endereços IP para um início mais rápido dos
pods e permite clusters com até 2,000 nós.
Adicionalmente, esse CNI pode ser utilizado junto com o Calico
para a criação de políticas de rede (NetworkPolicies). O projeto AWS VPC CNI
tem código fonte aberto com a documentação no Github.
Azure CNI para o Kubernetes
Azure CNI é um
plugin de código fonte aberto
que integra os Pods do Kubernetes com uma rede virtual da Azure (também conhecida como VNet)
provendo performance de rede similar à de máquinas virtuais no ambiente. Os Pods
podem se comunicar com outras VNets e com ambientes on-premises com o uso de
funcionalidades da Azure, e também podem ter clientes com origem dessas redes.
Os Pods podem acessar serviços da Azure, como armazenamento e SQL, que são
protegidos por Service Endpoints e Private Link. Você pode utilizar as políticas
de segurança e roteamento para filtrar o tráfico do Pod. O plugin associa IPs da VNet
para os Pods utilizando um pool de IPs secundário pré-configurado na interface de rede
do nó Kubernetes.
Calico é uma solução de conectividade e
segurança para contêineres, máquinas virtuais e serviços nativos em hosts. O
Calico suporta múltiplas camadas de conectividade/dados, como por exemplo:
uma camada Linux eBPF nativa, uma camada de conectividade baseada em conceitos
padrão do Linux e uma camada baseada no HNS do Windows. O calico provê uma
camada completa de conectividade e rede, mas também pode ser usado em conjunto com
CNIs de provedores de nuvem
para permitir a criação de políticas de rede.
Cilium
Cilium é um software de código fonte aberto
para prover conectividade e segurança entre contêineres de aplicação. O Cilium
pode lidar com tráfego na camada de aplicação (ex. HTTP) e pode forçar políticas
de rede nas camadas L3-L7 usando um modelo de segurança baseado em identidade e
desacoplado do endereçamento de redes, podendo inclusive ser utilizado com outros
plugins CNI.
Flannel
Flannel é uma camada muito simples
de conectividade que satisfaz os requisitos do Kubernetes. Muitas pessoas
reportaram sucesso em utilizar o Flannel com o Kubernetes.
Google Compute Engine (GCE)
Para os scripts de configuração do Google Compute Engine, roteamento
avançado é usado para associar
para cada VM uma sub-rede (o padrão é /24 - 254 IPs). Qualquer tráfico direcionado
para aquela sub-rede será roteado diretamente para a VM pela rede do GCE. Isso é
adicional ao IP principal associado à VM, que é mascarado para o acesso à Internet.
Uma brige Linux (chamada cbr0) é configurada para existir naquela sub-rede, e é
configurada no docker através da opção --bridge.
Essa bridge é criada pelo Kubelet (controlada pela opção --network-plugin=kubenet)
de acordo com a informação .spec.podCIDR do Nó.
O Docker irá agora alocar IPs do bloco cbr-cidr. Contêineres podem alcançar
outros contêineres e nós através da interface cbr0. Esses IPs são todos roteáveis
dentro da rede do projeto do GCE.
O GCE mesmo não sabe nada sobre esses IPs, então não irá mascará-los quando tentarem
se comunicar com a internet. Para permitir isso uma regra de IPTables é utilizada para
mascarar o tráfego para IPs fora da rede do projeto do GCE (no exemplo abaixo, 10.0.0.0/8):
Por fim, o encaminhamento de IP deve ser habilitado no Kernel de forma a processar
os pacotes vindos dos contêineres:
sysctl net.ipv4.ip_forward=1
O resultado disso tudo é que Pods agora podem alcançar outros Pods e podem também
se comunicar com a Internet.
Kube-router
Kube-router é uma solução construída
que visa prover alta performance e simplicidade operacional. Kube-router provê um
proxy de serviços baseado no LVS/IPVS,
uma solução de comunicação pod-para-pod baseada em encaminhamento de pacotes Linux e sem camadas
adicionais, e funcionalidade de políticas de redes baseadas no IPTables/IPSet.
Redes L2 e bridges Linux
Se você tem uma rede L2 "burra", como um switch em um ambiente "bare-metal",
você deve conseguir fazer algo similar ao ambiente GCE explicado acima.
Note que essas instruções foram testadas casualmente - parece funcionar, mas
não foi propriamente testado. Se você conseguir usar essa técnica e aperfeiçoar
o processo, por favor nos avise!!
Siga a parte "With Linux Bridge devices" desse
tutorial super bacana do
Lars Kellogg-Stedman.
Multus (Plugin multi redes)
Multus é um plugin Multi CNI para
suportar a funcionalidade multi redes do Kubernetes usando objetos baseados em CRDs.
OVN é uma solução de virtualização de redes de código aberto desenvolvido pela
comunidade Open vSwitch. Permite a criação de switches lógicos, roteadores lógicos,
listas de acesso, balanceadores de carga e mais, para construir diferences topologias
de redes virtuais. Esse projeto possui um plugin específico para o Kubernetes e a
documentação em ovn-kubernetes.
Próximos passos
Design inicial do modelo de conectividade do Kubernetes e alguns planos futuros
estão descritos com maiores detalhes no
documento de design de redes.
3.9.4 - Arquitetura de Log
Os logs de aplicativos e sistemas podem ajudá-lo a entender o que está acontecendo dentro do seu cluster. Os logs são particularmente úteis para depurar problemas e monitorar a atividade do cluster. A maioria das aplicações modernas possui algum tipo de mecanismo de logs; como tal, a maioria dos mecanismos de contêineres também é projetada para suportar algum tipo de log. O método de log mais fácil e abrangente para aplicações em contêiner é gravar nos fluxos de saída e erro padrão.
No entanto, a funcionalidade nativa fornecida por um mecanismo de contêiner ou tempo de execução geralmente não é suficiente para uma solução completa de log. Por exemplo, se um contêiner travar, um pod for despejado ou um nó morrer, geralmente você ainda desejará acessar os logs do aplicativo. Dessa forma, os logs devem ter armazenamento e ciclo de vida separados, independentemente de nós, pods ou contêineres. Este conceito é chamado cluster-level-logging. O log no nível de cluster requer um back-end separado para armazenar, analisar e consultar logs. O kubernetes não fornece uma solução de armazenamento nativa para dados de log, mas você pode integrar muitas soluções de log existentes no cluster do Kubernetes.
As arquiteturas de log no nível de cluster são descritas no pressuposto de que um back-end de log esteja presente dentro ou fora do cluster. Se você não estiver interessado em ter o log no nível do cluster, ainda poderá encontrar a descrição de como os logs são armazenados e manipulados no nó para serem úteis.
Log básico no Kubernentes
Nesta seção, você pode ver um exemplo de log básico no Kubernetes que gera dados para o fluxo de saída padrão(standard output stream). Esta demostração usa uma especificação de pod com um contêiner que grava algum texto na saída padrão uma vez por segundo.
Para buscar os logs, use o comando kubectl logs, da seguinte maneira:
kubectl logs counter
A saída será:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
Você pode usar kubectl logs para recuperar logs de uma instanciação anterior de um contêiner com o sinalizador --previous, caso o contêiner tenha falhado. Se o seu pod tiver vários contêineres, você deverá especificar quais logs do contêiner você deseja acessar anexando um nome de contêiner ao comando. Veja a documentação do kubectl logs para mais destalhes.
Logs no nível do Nó
Tudo o que um aplicativo em contêiner grava no stdout e stderr é tratado e redirecionado para algum lugar por dentro do mecanismo de contêiner. Por exemplo, o mecanismo de contêiner do Docker redireciona esses dois fluxos para um driver de log, configurado no Kubernetes para gravar em um arquivo no formato json.
Nota: O driver de log json do Docker trata cada linha como uma mensagem separada. Ao usar o driver de log do Docker, não há suporte direto para mensagens de várias linhas. Você precisa lidar com mensagens de várias linhas no nível do agente de log ou superior.
Por padrão, se um contêiner reiniciar, o kubelet manterá um contêiner terminado com seus logs. Se um pod for despejado do nó, todos os contêineres correspondentes também serão despejados, juntamente com seus logs.
Uma consideração importante no log no nível do nó está implementado a rotação de log, para que os logs não consumam todo o armazenamento disponível no nó. Atualmente, o Kubernentes não é responsável pela rotação de logs, mas uma ferramenta de deployment deve configurar uma solução para resolver isso.
Por exemplo, nos clusters do Kubernetes, implementados pelo script kube-up.sh, existe uma ferramenta logrotate configurada para executar a cada hora. Você pode configurar um tempo de execução do contêiner para girar os logs do aplicativo automaticamente, por exemplo, usando o log-opt do Docker.
No script kube-up.sh, a última abordagem é usada para imagem COS no GCP, e a anterior é usada em qualquer outro ambiente. Nos dois casos por padrão, a rotação é configurada para ocorrer quando o arquivo de log exceder 10MB.
Como exemplo, você pode encontrar informações detalhadas sobre como o kube-up.sh define o log da imagem COS no GCP no script correspondente.
Quando você executa kubectl logs como no exemplo de log básico acima, o kubelet no nó lida com a solicitação e lê diretamente do arquivo de log, retornando o conteúdo na resposta.
Nota: Atualmente, se algum sistema externo executou a rotação, apenas o conteúdo do arquivo de log mais recente estará disponível através de kubectl logs. Por exemplo, se houver um arquivo de 10MB, o logrotate executa a rotação e existem dois arquivos, um com 10MB de tamanho e um vazio, o kubectl logs retornará uma resposta vazia.
Logs de componentes do sistema
Existem dois tipos de componentes do sistema: aqueles que são executados em um contêiner e aqueles que não são executados em um contêiner. Por exemplo:
O scheduler Kubernetes e o kube-proxy são executados em um contêiner.
O tempo de execução do kubelet e do contêiner, por exemplo, Docker, não é executado em contêineres.
Nas máquinas com systemd, o tempo de execução do kubelet e do container é gravado no journald. Se systemd não estiver presente, eles gravam em arquivos .log no diretório /var/log.
Os componentes do sistema dentro dos contêineres sempre gravam no diretório /var/log, ignorando o mecanismo de log padrão. Eles usam a biblioteca de logs klog. Você pode encontrar as convenções para a gravidade do log desses componentes nos documentos de desenvolvimento sobre log.
Da mesma forma que os logs de contêiner, os logs de componentes do sistema no diretório /var/log devem ser rotacionados. Nos clusters do Kubernetes criados pelo script kube-up.sh, esses logs são configurados para serem rotacionados pela ferramenta logrotate diariamente ou quando o tamanho exceder 100MB.
Arquiteturas de log no nível de cluster
Embora o Kubernetes não forneça uma solução nativa para o log em nível de cluster, há várias abordagens comuns que você pode considerar. Aqui estão algumas opções:
Use um agente de log no nível do nó que seja executado em todos os nós.
Inclua um contêiner sidecar dedicado para efetuar logging em um pod de aplicativo.
Envie logs diretamente para um back-end de dentro de um aplicativo.
Usando um agente de log de nó
Você pode implementar o log em nível de cluster incluindo um agente de log em nível de nó em cada nó. O agente de log é uma ferramenta dedicada que expõe logs ou envia logs para um back-end. Geralmente, o agente de log é um contêiner que tem acesso a um diretório com arquivos de log de todos os contêineres de aplicativos nesse nó.
Como o agente de log deve ser executado em todos os nós, é comum implementá-lo como uma réplica do DaemonSet, um pod de manifesto ou um processo nativo dedicado no nó. No entanto, as duas últimas abordagens são obsoletas e altamente desencorajadas.
O uso de um agente de log no nível do nó é a abordagem mais comum e incentivada para um cluster Kubernetes, porque ele cria apenas um agente por nó e não requer alterações nos aplicativos em execução no nó. No entanto, o log no nível do nó funciona apenas para a saída padrão dos aplicativos e o erro padrão.
O Kubernetes não especifica um agente de log, mas dois agentes de log opcionais são fornecidos com a versão Kubernetes: Stackdriver Logging para uso com o Google Cloud Platform e Elasticsearch. Você pode encontrar mais informações e instruções nos documentos dedicados. Ambos usam fluentd com configuração customizada como um agente no nó.
Usando um contêiner sidecar com o agente de log
Você pode usar um contêiner sidecar de uma das seguintes maneiras:
O container sidecar transmite os logs do aplicativo para seu próprio stdout.
O contêiner do sidecar executa um agente de log, configurado para selecionar logs de um contêiner de aplicativo.
Streaming sidecar conteiner
Fazendo com que seus contêineres de sidecar fluam para seus próprios stdout e stderr, você pode tirar proveito do kubelet e do agente de log que já executam em cada nó. Os contêineres sidecar lêem logs de um arquivo, socket ou journald. Cada contêiner sidecar individual imprime o log em seu próprio stdout ou stderr stream.
Essa abordagem permite separar vários fluxos de logs de diferentes partes do seu aplicativo, algumas das quais podem não ter suporte para gravar em stdout ou stderr. A lógica por trás do redirecionamento de logs é mínima, portanto dificilmente representa uma sobrecarga significativa. Além disso, como stdout e stderr são manipulados pelo kubelet, você pode usar ferramentas internas como o kubectl logs.
Considere o seguinte exemplo. Um pod executa um único contêiner e grava em dois arquivos de log diferentes, usando dois formatos diferentes. Aqui está um arquivo de configuração para o Pod:
apiVersion:v1kind:Podmetadata:name:counterspec:containers:- name:countimage:busyboxargs:- /bin/sh- -c- > i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
donevolumeMounts:- name:varlogmountPath:/var/logvolumes:- name:varlogemptyDir:{}
Seria uma bagunça ter entradas de log de diferentes formatos no mesmo fluxo de logs, mesmo se você conseguisse redirecionar os dois componentes para o fluxo stdout do contêiner. Em vez disso, você pode introduzir dois contêineres sidecar. Cada contêiner sidecar pode direcionar um arquivo de log específico de um volume compartilhado e depois redirecionar os logs para seu próprio fluxo stdout.
Aqui está um arquivo de configuração para um pod que possui dois contêineres sidecar:
Agora, quando você executa este pod, é possível acessar cada fluxo de log separadamente, executando os seguintes comandos:
kubectl logs counter count-log-1
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
kubectl logs counter count-log-2
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
O agente no nível do nó instalado em seu cluster coleta esses fluxos de logs automaticamente sem nenhuma configuração adicional. Se desejar, você pode configurar o agente para analisar as linhas de log, dependendo do contêiner de origem.
Observe que, apesar do baixo uso da CPU e da memória (ordem de alguns milicores por CPU e ordem de vários megabytes de memória), gravar logs em um arquivo e depois transmiti-los para o stdout pode duplicar o uso do disco. Se você tem um aplicativo que grava em um único arquivo, geralmente é melhor definir /dev/stdout como destino, em vez de implementar a abordagem de contêiner de transmissão no sidecar.
Os contêineres sidecar também podem ser usados para rotacionar arquivos de log que não podem ser rotacionados pelo próprio aplicativo. Um exemplo dessa abordagem é um pequeno contêiner executando logrotate periodicamente.
No entanto, é recomendável usar o stdout e o stderr diretamente e deixar as políticas de rotação e retenção no kubelet.
Contêiner sidecar com um agente de log
Se o agente de log no nível do nó não for flexível o suficiente para sua situação, você poderá criar um contêiner secundário com um agente de log separado que você configurou especificamente para executar com seu aplicativo.
Nota: O uso de um agente de log em um contêiner sidecar pode levar a um consumo significativo de recursos. Além disso, você não poderá acessar esses logs usando o comando kubectl logs, porque eles não são controlados pelo kubelet.
Como exemplo, você pode usar o Stackdriver, que usa fluentd como um agente de log. Aqui estão dois arquivos de configuração que você pode usar para implementar essa abordagem. O primeiro arquivo contém um ConfigMap para configurar o fluentd.
apiVersion:v1kind:ConfigMapmetadata:name:fluentd-configdata:fluentd.conf:| <source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
Nota: A configuração do fluentd está além do escopo deste artigo. Para obter informações sobre como configurar o fluentd, consulte a documentação oficial do fluentd.
O segundo arquivo descreve um pod que possui um contêiner sidecar rodando fluentemente.
O pod monta um volume onde o fluentd pode coletar seus dados de configuração.
Depois de algum tempo, você pode encontrar mensagens de log na interface do Stackdriver.
Lembre-se de que este é apenas um exemplo e você pode realmente substituir o fluentd por qualquer agente de log, lendo de qualquer fonte dentro de um contêiner de aplicativo.
Expondo logs diretamente do aplicativo
Você pode implementar o log no nível do cluster, expondo ou enviando logs diretamente de todos os aplicativos; no entanto, a implementação desse mecanismo de log está fora do escopo do Kubernetes.
3.9.5 - Logs de Sistema
Logs de componentes do sistema armazenam eventos que acontecem no cluster, sendo muito úteis para depuração. Seus níveis de detalhe podem ser ajustados para mais ou para menos. Podendo se ater, por exemplo, a mostrar apenas os erros que ocorrem no componente, ou chegando a mostrar cada passo de um evento. (Como acessos HTTP, mudanças no estado dos pods, ações dos controllers, ou decisões do scheduler).
Klog
Klog é a biblioteca de logs do Kubernetes. Responsável por gerar as mensagens de log para os componentes do sistema.
A migração pro formato de logs estruturados é um processo em andamento. Nem todos os logs estão dessa forma na versão atual. Sendo assim, para realizar o processamento de arquivos de log, você também precisa lidar com logs não estruturados.
A formatação e serialização dos logs ainda estão sujeitas a alterações.
A estruturação dos logs trás uma estrutura uniforme para as mensagens de log, permitindo a extração programática de informações. Logs estruturados podem ser armazenados e processados com menos esforço e custo. Esse formato é totalmente retrocompatível e é habilitado por padrão.
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kube-system/kubedns" status="ready"
Logs em formato JSON
FEATURE STATE:Kubernetes v1.19 [alpha]
Aviso:
Algumas opções da biblioteca klog ainda não funcionam com os logs em formato JSON. Para ver uma lista completa de quais são estas, veja a documentação da ferramenta de linha de comando.
Nem todos os logs estarão garantidamente em formato JSON (como por exemplo durante o início de processos). Sendo assim, se você pretende realizar o processamento dos logs, seu código deverá saber tratar também linhas que não são JSON.
O nome dos campos e a serialização JSON ainda estão sujeitos a mudanças.
A opção --logging-format=json muda o formato dos logs, do formato padrão da klog para JSON. Abaixo segue um exemplo de um log em formato JSON (identado):
Aviso: A funcionalidade de limpeza dos logs pode causar impactos significativos na performance, sendo portanto contraindicada em produção.
A opção --experimental-logging-sanitization habilita o filtro de limpeza dos logs.
Quando habilitado, esse filtro inspeciona todos os argumentos dos logs, procurando por campos contendo dados sensíveis (como senhas, chaves e tokens). Tais campos não serão expostos nas mensagens de log.
Lista dos componentes que suportam a limpeza de logs atualmente:
Nota: O filtro de limpeza dos logs não impede a exposição de dados sensíveis nos logs das aplicações em execução.
Nível de detalhe dos logs
A opção -v controla o nível de detalhe dos logs. Um valor maior aumenta o número de eventos registrados, começando a registrar também os eventos menos importantes. Similarmente, um valor menor restringe os logs apenas aos eventos mais importantes. O valor padrão 0 registra apenas eventos críticos.
Localização dos Logs
Existem dois tipos de componentes do sistema: aqueles que são executados em um contêiner e aqueles que não são. Por exemplo:
Em máquinas com systemd, o kubelet e os agentes de execução gravam os logs no journald.
Em outros casos, eles escrevem os logs em arquivos .log no diretório /var/log.
Já os componentes executados dentro de contêineres, sempre irão escrever os logs em arquivos .log
no diretório /var/log, ignorando o mecanismo padrão de log.
De forma similar aos logs de contêiner, os logs de componentes do sistema no diretório /var/log devem ser rotacionados.
Nos clusters Kubernetes criados com o script kube-up.sh, a rotação dos logs é configurada pela ferramenta logrotate. Essa ferramenta rotaciona os logs diariamente
ou quando o tamanho do arquivo excede 100MB.
3.9.6 - Configurando o Garbage Collection do kubelet
O Garbage collection(Coleta de lixo) é uma função útil do kubelet que limpa imagens e contêineres não utilizados. O kubelet executará o garbage collection para contêineres a cada minuto e para imagens a cada cinco minutos.
Ferramentas externas de garbage collection não são recomendadas, pois podem potencialmente interromper o comportamento do kubelet removendo os contêineres que existem.
Coleta de imagens
O Kubernetes gerencia o ciclo de vida de todas as imagens através do imageManager, com a cooperação do cadvisor.
A política para o garbage collection de imagens leva dois fatores em consideração:
HighThresholdPercent e LowThresholdPercent. Uso do disco acima do limite acionará o garbage collection. O garbage collection excluirá as imagens que foram menos usadas recentemente até que o nível fique abaixo do limite.
Coleta de container
A política para o garbage collection de contêineres considera três variáveis definidas pelo usuário. MinAge é a idade mínima em que um contêiner pode ser coletado. MaxPerPodContainer é o número máximo de contêineres mortos que todo par de pod (UID, container name) pode ter. MaxContainers é o número máximo de contêineres mortos totais. Essas variáveis podem ser desabilitadas individualmente, definindo MinAge como zero e definindo MaxPerPodContainer e MaxContainers respectivamente para menor que zero.
O Kubelet atuará em contêineres não identificados, excluídos ou fora dos limites definidos pelos sinalizadores mencionados. Os contêineres mais antigos geralmente serão removidos primeiro. MaxPerPodContainer e MaxContainer podem potencialmente conflitar entre si em situações em que a retenção do número máximo de contêineres por pod (MaxPerPodContainer) estaria fora do intervalo permitido de contêineres globais mortos (MaxContainers). O MaxPerPodContainer seria ajustado nesta situação: O pior cenário seria fazer o downgrade do MaxPerPodContainer para 1 e remover os contêineres mais antigos. Além disso, os contêineres pertencentes a pods que foram excluídos são removidos assim que se tornem mais antigos que MinAge.
Os contêineres que não são gerenciados pelo kubelet não estão sujeitos ao garbage collection de contêiner.
Configurações do usuário
Os usuários podem ajustar os seguintes limites para ajustar o garbage collection da imagem com os seguintes sinalizadores do kubelet:
image-gh-high-threshold, a porcentagem de uso de disco que aciona o garbage collection da imagem. O padrão é 85%.
image-gc-low-threshold, a porcentagem de uso de disco com o qual o garbage collection da imagem tenta liberar. O padrão é 80%.
Também permitimos que os usuários personalizem a política do garbagem collection através dos seguintes sinalizadores do kubelet:
minimum-container-ttl-duration, idade mínima para um contêiner finalizado antes de ser colectado. O padrão é 0 minuto, o que significa que todo contêiner finalizado será coletado como lixo.
maximum-dead-containers-per-container, número máximo de instâncias antigas a serem retidas por contêiner. O padrão é 1.
maximum-dead-containers, número máximo de instâncias antigas de contêineres para retenção global. O padrão é -1, o que significa que não há limite global.
Os contêineres podem ser potencialmente coletados como lixo antes que sua utilidade expire. Esses contêineres podem conter logs e outros dados que podem ser úteis para solucionar problemas. Um valor suficientemente grande para maximum-dead-containers-per-container é altamente recomendado para permitir que pelo menos 1 contêiner morto seja retido por contêiner esperado. Um valor maior para maximum-dead-containers também é recomendados por um motivo semelhante.
Consulte esta issue para obter mais detalhes.
Descontinuado
Alguns recursos do Garbage Collection neste documento serão substituídos pelo kubelet eviction no futuro.
Incluindo:
Flag Existente
Nova Flag
Fundamentação
--image-gc-high-threshold
--eviction-hard ou --eviction-soft
os sinais existentes de despejo podem acionar o garbage collection da imagem
--image-gc-low-threshold
--eviction-minimum-reclaim
recuperações de despejo atinge o mesmo comportamento
--maximum-dead-containers
descontinuado quando os logs antigos forem armazenados fora do contexto do contêiner
--maximum-dead-containers-per-container
descontinuado quando os logs antigos forem armazenados fora do contexto do contêiner
--minimum-container-ttl-duration
descontinuado quando os logs antigos forem armazenados fora do contexto do contêiner
--low-diskspace-threshold-mb
--eviction-hard ou eviction-soft
O despejo generaliza os limites do disco para outros recursos
--outofdisk-transition-frequency
--eviction-pressure-transition-period
O despejo generaliza a transição da pressão do disco para outros recursos
Nota:
Esta seção tem links para projetos de terceiros que fornecem a funcionalidade exigida pelo Kubernetes. Os autores do projeto Kubernetes não são responsáveis por esses projetos. Esta página obedece as diretrizes de conteúdo do site CNCF, listando os itens em ordem alfabética. Para adicionar um projeto a esta lista, leia o guia de conteúdo antes de enviar sua alteração.
Complementos estendem as funcionalidades do Kubernetes.
Esta página lista alguns dos complementos disponíveis e links com suas respectivas instruções de instalação.
Rede e Política de Rede
ACI fornece rede integrada de contêineres e segurança de rede com a Cisco ACI.
Antrea opera nas camadas 3 e 4 do modelo de rede OSI para fornecer serviços de rede e de segurança para o Kubernetes, aproveitando o Open vSwitch como camada de dados de rede.
Calico é um provedor de serviços de rede e de políticas de rede. Este complemento suporta um conjunto flexível de opções de rede, de modo a permitir a escolha da opção mais eficiente para um dado caso de uso, incluindo redes overlay (sobrepostas) e não-overlay, com ou sem o uso do protocolo BGP. Calico usa o mesmo mecanismo para aplicar políticas de rede a hosts, pods, e aplicações na camada de service mesh (quando Istio e Envoy estão instalados).
Canal une Flannel e Calico, fornecendo rede e política de rede.
Cilium é um plug-in de rede de camada 3 e de políticas de rede que pode aplicar políticas HTTP/API/camada 7 de forma transparente. Tanto o modo de roteamento quanto o de sobreposição/encapsulamento são suportados. Este plug-in também consegue operar no topo de outros plug-ins CNI.
CNI-Genie permite que o Kubernetes se conecte facilmente a uma variedade de plug-ins CNI, como Calico, Canal, Flannel, Romana ou Weave.
Contiv oferece serviços de rede configuráveis para diferentes casos de uso (camada 3 nativa usando BGP, overlay (sobreposição) usando vxlan, camada 2 clássica e Cisco-SDN/ACI) e também um framework rico de políticas de rede. O projeto Contiv é totalmente open source. O instalador fornece opções de instalação com ou sem kubeadm.
Contrail é uma plataforma open source baseada no Tungsten Fabric que oferece virtualização de rede multi-nuvem e gerenciamento de políticas de rede. O Contrail e o Tungsten Fabric são integrados a sistemas de orquestração de contêineres, como Kubernetes, OpenShift, OpenStack e Mesos, e fornecem modos de isolamento para cargas de trabalho executando em máquinas virtuais, contêineres/pods e servidores físicos.
Flannel é um provedor de redes overlay (sobrepostas) que pode ser usado com o Kubernetes.
Knitter é um plug-in para suporte de múltiplas interfaces de rede em Pods do Kubernetes.
Multus é um plugin para suporte a várias interfaces de rede em Pods no Kubernetes. Este plug-in pode agir como um "meta-plug-in", ou um plug-in CNI que se comunica com múltiplos outros plug-ins CNI (por exemplo, Calico, Cilium, Contiv, Flannel), além das cargas de trabalho baseadas em SRIOV, DPDK, OVS-DPDK e VPP no Kubernetes.
NSX-T Container Plug-in (NCP) fornece integração entre o VMware NSX-T e sistemas de orquestração de contêineres como o Kubernetes. Além disso, oferece também integração entre o NSX-T e as plataformas CaaS/PaaS baseadas em contêiner, como o Pivotal Container Service (PKS) e o OpenShift.
Nuage é uma plataforma de rede definida por software que fornece serviços de rede baseados em políticas entre os Pods do Kubernetes e os ambientes não-Kubernetes, com visibilidade e monitoramento de segurança.
OVN-Kubernetes é um provedor de rede para o Kubernetes baseado no OVN (Open Virtual Network), uma implementação de redes virtuais que surgiu através do projeto Open vSwitch (OVS). O OVN-Kubernetes fornece uma implementação de rede baseada em overlay (sobreposição) para o Kubernetes, incluindo uma implementação baseada em OVS para serviços de balanceamento de carga e políticas de rede.
OVN4NFV-K8S-Plugin é um plug-in controlador CNI baseado no OVN (Open Virtual Network) que fornece serviços de rede cloud native, como Service Function Chaining (SFC), redes overlay (sobrepostas) OVN múltiplas, criação dinâmica de subredes, criação dinâmica de redes virtuais, provedor de rede VLAN e provedor de rede direto, e é plugável a outros plug-ins multi-rede. Ideal para cargas de trabalho que utilizam computação de borda cloud native em redes multi-cluster.
Romana é uma solução de rede de camada 3 para redes de pods que também suporta a API NetworkPolicy. Detalhes da instalação do complemento Kubeadm disponíveis aqui.
Weave Net fornece rede e política de rede, funciona em ambos os lados de uma partição de rede e não requer um banco de dados externo.
Descoberta de Serviço
CoreDNS é um servidor DNS flexível e extensível que pode ser instalado como o serviço de DNS dentro do cluster para ser utilizado por pods.
Visualização & Controle
Dashboard é uma interface web para gestão do Kubernetes.
Weave Scope é uma ferramenta gráfica para visualizar contêineres, pods, serviços, entre outros objetos do cluster. Pode ser utilizado com uma conta Weave Cloud. Como alternativa, é possível hospedar a interface do usuário por conta própria.
Infraestrutura
KubeVirt é um complemento para executar máquinas virtuais no Kubernetes. É geralmente executado em clusters em máquina física.
Complementos Legados
Existem vários outros complementos documentados no diretório cluster/addons que não são mais utilizados.
Projetos bem mantidos devem ser listados aqui. PRs são bem-vindos!
3.10 - Extendendo o Kubernetes
3.10.1 - Extendendo a API do Kubernetes
3.10.1.1 - Extendendo a API do Kubernetes com a camada de agregação
A camada de agregação permite ao Kubernetes ser estendido com APIs adicionais,
para além do que é oferecido pelas APIs centrais do Kubernetes.
As APIs adicionais podem ser soluções prontas tal como o
catálogo de serviços,
ou APIs que você mesmo desenvolva.
A camada de agregação executa em processo com o kube-apiserver.
Até que um recurso de extensão seja registado, a camada de agregação
não fará nada. Para registar uma API, terá de adicionar um objeto APIService
que irá "reclamar" o caminho URL na API do Kubernetes. Nesta altura, a camada
de agregação procurará qualquer coisa enviada para esse caminho da API
(e.g. /apis/myextension.mycompany.io/v1/…) para o APIService registado.
A maneira mais comum de implementar o APIService é executar uma
extensão do servidor API em Pods que executam no seu cluster.
Se estiver a usar o servidor de extensão da API para gerir recursos
no seu cluster, o servidor de extensão da API (também escrito como "extension-apiserver")
é tipicamente emparelhado com um ou mais controladores.
A biblioteca apiserver-builder providencia um esqueleto para ambos
os servidores de extensão da API e controladores associados.
Latência da resposta
Servidores de extensão de APIs devem ter baixa latência de rede de e para o kube-apiserver.
Pedidos de descoberta são necessários que façam a ida e volta do kube-apiserver em 5
segundos ou menos.
Se o seu servidor de extensão da API não puder cumprir com o requisito de latência,
considere fazer alterações que permitam atingi-lo. Pode também definir
portal de funcionalidadeEnableAggregatedDiscoveryTimeout=false no kube-apiserver para desativar
a restrição de intervalo. Esta portal de funcionalidade deprecado será removido
num lançamento futuro.
3.10.2 - Extensões de Computação, armazenamento e redes
3.10.2.1 - Plugins de rede
Plugins de redes no Kubernetes podem ser dos seguintes tipos:
Plugins CNI: Aderentes à especificação Container Network Interface (CNI), desenhados para interoperabilidade.
Kubernetes usa a versão v0.4.0 da especificação CNI.
Plugin kubenet: Implementa o cbr0 básico usando os plugins CNI bridge e host-local
Instalação
O kubelet possui um plugin único padrão, e um plugin padrão comum para todo o cluster.
Ele verifica o plugin quando inicia, se lembra o que encontrou, e executa o plugin selecionado
em momentos oportunos dentro do ciclo de vida de um Pod (isso é verdadeiro apenas com o Docker,
uma vez que o CRI gerencia seus próprios plugins de CNI). Existem dois parâmetros de linha de comando
no Kubelet para se ter em mente quando usando plugins:
cni-bin-dir: O Kubelet verifica esse diretório por plugins na inicialização
network-plugin: O plugin de rede que deve ser utilizado do diretório configurado em
cni-bin-dir. Deve ser igual ao nome configurado por um plugin no diretório de plugins.
Para plugins de CNI, isso equivale ao valor cni.
Requisitos de plugins de Rede
Além de prover a interface NetworkPlugin
para configuração da rede do pod, o plugin pode necessitar de suporte específico ao
kube-proxy.
O proxy iptables obviamente depende do iptables, e o plugin deve garantir que o
tráfego do contêiner esteja disponível para o iptables. Por exemplo, se o plugin
conecta os contêineres à Linux bridge, o plugin deve configurar a diretiva de
sysctlnet/bridge/bridge-nf-call-iptables com o valor 1 para garantir que o
proxy iptables opere normalmente. Se o plugin não faz uso da Linux Bridge (mas outro
mecanismo, como Open vSwitch) ele deve garantir que o tráfego do contêiner é roteado
apropriadamente para o proxy.
Por padrão, se nenhum plugin de rede é configurado no kubelet, o plugin noop é utilizado,
que configura net/bridge/bridge-nf-call-iptables=1 para garantir que configurações simples
(como Docker com bridge Linux) operem corretamente com o proxy iptables.
CNI
O plugin de CNI é selecionado utilizando-se da opção --network-plugin=cni no início do Kubeket.
O Kubelet lê um arquivo do diretório especificado em --cni-conf-dir (padrão /etc/cni/net.d)
e usa a configuração de CNI desse arquivo para configurar a rede de cada Pod. O arquivo de
configuração do CNI deve usar a especificação de CNI,
e qualquer plugin referenciado nesse arquivo deve estar presente no diretório
--cni-bin-dir (padrão /opt/cni/bin).
Se existirem múltiplos arquivos de configuração no diretório, o kubelet usa o arquivo de
configuração que vier primeiro pelo nome, em ordem alfabética.
Adicionalmente ao plugin de CNI especificado no arquivo de configuração, o Kubernetes requer
o plugin CNI padrão lo ao menos na versão 0.2.0.
Suporte a hostPort
O plugin de redes CNI suporta hostPort. Você pode utilizar o plugin oficial
portmap
ou usar seu próprio plugin com a funcionalidade de portMapping.
Caso você deseje habilitar o suporte a hostPort, você deve especificar
portMappings capability no seu cni-conf-dir.
Por exemplo:
O plugin de rede CNI também suporta o controle de banda de entrada e saída.
Você pode utilizar o plugin oficial bandwidth
desenvolvido ou usar seu próprio plugin de controle de banda.
Se você habilitar o suporte ao controle de banda, você deve adicionar o plugin bandwidth
no seu arquivo de configuração de CNI (padrão /etc/cni/net.d) e garantir que o programa
exista no diretório de binários do CNI (padrão /opt/cni/bin).
Kubenet é um plugin de rede muito simples, existente apenas no Linux. Ele não
implementa funcionalidades mais avançadas, como rede entre nós ou políticas de rede.
Ele é geralmente utilizado junto a um provedor de nuvem que configura as regras de
roteamento para comunicação entre os nós, ou em ambientes com apenas um nó.
O Kubenet cria uma interface bridge no Linux chamada cbr0 e cria um par veth
para cada um dos pods com o host como a outra ponta desse par, conectado à cbr0.
Na interface no lado do Pod um endereço IP é alocado de uma faixa associada ao nó,
sendo parte de alguma configuração no nó ou pelo controller-manager. Na interface cbr0
é associado o MTU equivalente ao menor MTU de uma interface de rede do host.
Esse plugin possui alguns requisitos:
Os plugins CNI padrão bridge, lo e host-local são obrigatórios, ao menos na
versão 0.2.0. O Kubenet buscará inicialmente esses plugins no diretório /opt/cni/bin.
Especifique a opção cni-bin-dir no kubelet para fornecer um diretório adicional
de busca. O primeiro local equivalente será o utilizado.
O kubelet deve ser executado com a opção --network-plugin=kubenet para habilitar esse plugin.
O Kubelet deve ainda ser executado com a opção --non-masquerade-cidr=<clusterCidr> para
garantir que o tráfego de IPs para fora dessa faixa seja mascarado.
O nó deve possuir uma subrede associada, através da opção --pod-cidr configurada
na inicialização do kubelet, ou as opções --allocate-node-cidrs=true --cluster-cidr=<cidr>
utilizadas na inicialização do controller-manager.
Customizando o MTU (com kubenet)
O MTU deve sempre ser configurado corretamente para obter-se a melhor performance de
rede. Os plugins de rede geralmente tentam detectar uma configuração correta de MTU,
porém algumas vezes a lógica não irá resultar em uma configuração adequada. Por exemplo,
se a Docker bridge ou alguma outra interface possuir um MTU pequeno, o kubenet irá
selecionar aquela MTU. Ou caso você esteja utilizando encapsulamento IPSEC, o MTU deve
ser reduzido, e esse cálculo não faz parte do escopo da maioria dos plugins de rede.
Sempre que necessário, você pode configurar explicitamente o MTU com a opção network-plugin-mtu
no kubelet. Por exemplo, na AWS o MTU da eth0 geralmente é 9001 então você deve
especificar --network-plugin-mtu=9001. Se você estiver usando IPSEC você deve reduzir
o MTU para permitir o encapsulamento excedente; por exemplo: --network-plugin-mtu=8773.
Essa opção faz parte do plugin de rede. Atualmente apenas o kubenet suporta a configuração
network-plugin-mtu.
Resumo de uso
--network-plugin=cni especifica que devemos usar o plugin de redes cni com os
binários do plugin localizados em --cni-bin-dir (padrão /opt/cni/bin) e as
configurações do plugin localizadas em --cni-conf-dir (default /etc/cni/net.d).
--network-plugin=kubenet especifica que iremos usar o plugin de rede kubenet
com os plugins CNI bridge, lo e host-local localizados em /opt/cni/bin ou cni-bin-dir.
--network-plugin-mtu=9001 especifica o MTU a ser utilizado, atualmente apenas em uso
pelo plugin de rede kubenet
Próximos passos
3.10.3 - Padrão Operador
Operadores são extensões de software para o Kubernetes que
fazem uso de recursos personalizados
para gerir aplicações e os seus componentes. Operadores seguem os
princípios do Kubernetes, notavelmente o ciclo de controle.
Motivação
O padrão Operador tem como objetivo capturar o principal objetivo de um operador
humano que gere um serviço ou um conjunto de serviços. Operadores humanos
responsáveis por aplicações e serviços específicos têm um conhecimento
profundo da forma como o sistema é suposto se comportar, como é instalado
e como deve reagir na ocorrência de problemas.
As pessoas que executam cargas de trabalho no Kubernetes habitualmente gostam
de usar automação para cuidar de tarefas repetitivas. O padrão Operador captura
a forma como pode escrever código para automatizar uma tarefa para além do que
o Kubernetes fornece.
Operadores no Kubernetes
O Kubernetes é desenhado para automação. Out of the box, você tem bastante
automação embutida no núcleo do Kubernetes. Pode usar
o Kubernetes para automatizar instalações e executar cargas de trabalho,
e pode ainda automatizar a forma como o Kubernetes faz isso.
O conceito de controlador no
Kubernetes permite a extensão do comportamento sem modificar o código do próprio
Kubernetes.
Operadores são clientes da API do Kubernetes que atuam como controladores para
um dado Custom Resource
Exemplo de um Operador
Algumas das coisas que um operador pode ser usado para automatizar incluem:
instalar uma aplicação a pedido
obter e restaurar backups do estado dessa aplicação
manipular atualizações do código da aplicação juntamente com alterações
como esquemas de base de dados ou definições de configuração extra
publicar um Service para aplicações que não suportam a APIs do Kubernetes
para as descobrir
simular uma falha em todo ou parte do cluster de forma a testar a resiliência
escolher um lider para uma aplicação distribuída sem um processo
de eleição de membro interno
Como deve um Operador parecer em mais detalhe? Aqui está um exemplo em mais
detalhe:
Um recurso personalizado (custom resource) chamado SampleDB, que você pode
configurar para dentro do cluster.
Um Deployment que garante que um Pod está a executar que contém a
parte controlador do operador.
Uma imagem do container do código do operador.
Código do controlador que consulta o plano de controle para descobrir quais
recursos SampleDB estão configurados.
O núcleo do Operador é o código para informar ao servidor da API (API server) como fazer
a realidade coincidir com os recursos configurados.
Se você adicionar um novo SampleDB, o operador configurará PersistentVolumeClaims
para fornecer armazenamento de base de dados durável, um StatefulSet para executar SampleDB e
um Job para lidar com a configuração inicial.
Se você apagá-lo, o Operador tira um snapshot e então garante que
o StatefulSet e Volumes também são removidos.
O operador também gere backups regulares da base de dados. Para cada recurso SampleDB,
o operador determina quando deve criar um Pod que possa se conectar
à base de dados e faça backups. Esses Pods dependeriam de um ConfigMap
e / ou um Secret que possui detalhes e credenciais de conexão com à base de dados.
Como o Operador tem como objetivo fornecer automação robusta para o recurso
que gere, haveria código de suporte adicional. Para este exemplo,
O código verifica se a base de dados está a executar uma versão antiga e, se estiver,
cria objetos Job que o atualizam para si.
Instalar Operadores
A forma mais comum de instalar um Operador é a de adicionar a
definição personalizada de recurso (Custom Resource Definition) e
o seu Controlador associado ao seu cluster.
O Controlador vai normalmente executar fora do
plano de controle,
como você faria com qualquer aplicação containerizada.
Por exemplo, você pode executar o controlador no seu cluster como um Deployment.
Usando um Operador
Uma vez que você tenha um Operador instalado, usaria-o adicionando, modificando
ou apagando a espécie de recurso que o Operador usa. Seguindo o exemplo acima,
você configuraria um Deployment para o próprio Operador, e depois:
kubectl get SampleDB # encontra a base de dados configurada
kubectl edit SampleDB/example-database # mudar manualmente algumas definições
…e é isso! O Operador vai tomar conta de aplicar
as mudanças assim como manter o serviço existente em boa forma.
Escrevendo o seu próprio Operador
Se não existir no ecosistema um Operador que implementa
o comportamento que pretende, pode codificar o seu próprio.
Qual é o próximo você vai encontrar
alguns links para bibliotecas e ferramentas que pode usar
para escrever o seu próprio Operador cloud native.
Pode também implementar um Operador (isto é, um Controlador) usando qualquer linguagem / runtime
que pode atuar como um cliente da API do Kubernetes.
Gerenciando dados de configurações usando Secrets.
4.1.1 - Gerenciando Secret usando kubectl
Criando objetos Secret usando a linha de comando kubectl.
Antes de você começar
Você precisa de um cluster Kubernetes e a ferramenta de linha de comando kubectl
precisa estar configurada para acessar o seu cluster. Se você ainda não tem um
cluster, pode criar um usando o minikube
ou você pode usar um dos seguintes ambientes:
Um Secret pode conter credenciais de usuário requeridas por Pods para acesso a um banco de dados.
Por exemplo, uma string de conexão de banco de dados é composta por um usuário e senha.
Você pode armazenar o usuário em um arquivo ./username.txt e a senha em um
arquivo ./password.txt na sua máquina local.
A opção -n nos comandos acima garante que os arquivos criados não vão conter
uma nova linha extra no final do arquivo de texto. Isso é importante porque
quando o kubectl lê um arquivo e codifica o conteúdo em uma string base64,
o caractere da nova linha extra também é codificado.
O comando kubectl create secret empacota os arquivos em um Secret e cria um
objeto no API server.
Você não precisa escapar o caractere especial em senhas a partir de arquivos (--from-file).
Você também pode prover dados para Secret usando a tag --from-literal=<key>=<value>.
Essa tag pode ser especificada mais de uma vez para prover múltiplos pares de chave-valor.
Observe que caracteres especiais como $, \, *, =, e ! vão ser interpretados
pelo seu shell e precisam ser escapados.
Na maioria dos shells, a forma mais fácil de escapar as senhas é usar aspas simples (').
Por exemplo, se sua senha atual é S!B\*d$zDsb=, você precisa executar o comando dessa forma:
Os comandos kubectl get e kubectl describe omitem o conteúdo de um Secret por padrão.
Isso para proteger o Secret de ser exposto acidentalmente para uma pessoa não autorizada,
ou ser armazenado em um log de terminal.
Decodificando o Secret
Para ver o conteúdo de um Secret que você criou, execute o seguinte comando:
kubectl get secret db-user-pass -o jsonpath='{.data}'
4.1.2 - Gerenciando Secret usando Arquivo de Configuração
Criando objetos Secret usando arquivos de configuração de recursos.
Antes de você começar
Você precisa de um cluster Kubernetes e a ferramenta de linha de comando kubectl
precisa estar configurada para acessar o seu cluster. Se você ainda não tem um
cluster, pode criar um usando o minikube
ou você pode usar um dos seguintes ambientes:
Você pode criar um Secret primeiramente em um arquivo, no formato JSON ou YAML, e depois
criar o objeto. O recurso Secret
contém dois mapas: data e stringData.
O campo data é usado para armazenar dados arbitrários, codificados usando base64. O
campo stringData é usado por conveniência, e permite que você use dados para um Secret
como strings não codificadas.
As chaves para data e stringData precisam ser compostas por caracteres alfanuméricos,
_, - ou ..
Por exemplo, para armazenar duas strings em um Secret usando o campo data, converta
as strings para base64 da seguinte forma:
echo -n 'admin' | base64
A saída deve ser similar a:
YWRtaW4=
echo -n '1f2d1e2e67df' | base64
A saída deve ser similar a:
MWYyZDFlMmU2N2Rm
Escreva o arquivo de configuração do Secret, que será parecido com:
Nota: Os valores serializados dos dados JSON e YAML de um Secret são codificados em strings
base64. Novas linhas não são válidas com essas strings e devem ser omitidas. Quando
usar o utilitário base64 em Darwin/MacOS, os usuários devem evitar usar a opção -b
para separar linhas grandes. Por outro lado, usuários de Linux devem adicionar a opção
-w 0 ao comando base64 ou o pipebase64 | tr -d '\n' se a opção w não estiver disponível
Para cenários específicos, você pode querer usar o campo stringData ao invés de data.
Esse campo permite que você use strings não-base64 diretamente dentro do Secret,
e a string vai ser codificada para você quando o Secret for criado ou atualizado.
Um exemplo prático para isso pode ser quando você esteja fazendo deploy de uma aplicação
que usa um Secret para armazenar um arquivo de configuração, e você quer popular partes desse
arquivo de configuração durante o processo de implantação.
Por exemplo, se sua aplicação usa o seguinte arquivo de configuração:
O campo stringData é um campo de conveniência apenas de leitura. Ele nunca vai ser exibido
ao buscar um Secret. Por exemplo, se você executar o seguinte comando:
Os comandos kubectl get e kubectl describe omitem o conteúdo de um Secret por padrão.
Isso para proteger o Secret de ser exposto acidentalmente para uma pessoa não autorizada,
ou ser armazenado em um log de terminal.
Para verificar o conteúdo atual de um dado codificado, veja decodificando secret.
Se um campo, como username, é especificado em data e stringData,
o valor de stringData é o usado. Por exemplo, dada a seguinte definição do Secret:
Criando objetos Secret usando o arquivo kustomization.yaml
Desde o Kubernetes v1.14, o kubectl provê suporte para gerenciamento de objetos usando Kustomize.
O Kustomize provê geradores de recursos para criar Secrets e ConfigMaps.
Os geradores Kustomize devem ser especificados em um arquivo kustomization.yaml dentro
de um diretório. Depois de gerar o Secret, você pode criar o Secret com kubectl apply.
Antes de você começar
Você precisa de um cluster Kubernetes e a ferramenta de linha de comando kubectl
precisa estar configurada para acessar o seu cluster. Se você ainda não tem um
cluster, pode criar um usando o minikube
ou você pode usar um dos seguintes ambientes:
Você pode criar um Secret definindo um secretGenerator em um
arquivo kustomization.yaml que referencia outros arquivos existentes.
Por exemplo, o seguinte arquivo kustomization referencia os
arquivos ./username.txt e ./password.txt:
Você também pode definir o secretGenerator no arquivo kustomization.yaml
por meio de alguns literais.
Por exemplo, o seguinte arquivo kustomization.yaml contém dois literais
para username e password respectivamente:
Observe que nos dois casos, você não precisa codificar os valores em base64.
Criando o Secret
Aplique o diretório que contém o arquivo kustomization.yaml para criar o Secret.
kubectl apply -k .
A saída deve ser similar a:
secret/db-user-pass-96mffmfh4k created
Observe que quando um Secret é gerado, o nome do segredo é criado usando o hash
dos dados do Secret mais o valor do hash. Isso garante que
um novo Secret é gerado cada vez que os dados são modificados.
Verifique o Secret criado
Você pode verificar que o secret foi criado:
kubectl get secrets
A saída deve ser similar a:
NAME TYPE DATA AGE
db-user-pass-96mffmfh4k Opaque 2 51s
Os comandos kubectl get e kubectl describe omitem o conteúdo de um Secret por padrão.
Isso para proteger o Secret de ser exposto acidentalmente para uma pessoa não autorizada,
ou ser armazenado em um log de terminal.
Para verificar o conteúdo atual de um dado codificado, veja decodificando secret.
Essa seção da documentação contém tutoriais (em inglês). Um tutorial mostra como realizar um objetivo mais complexo que uma simples tarefa. Eles podem ser divididos em diversas seções, cada uma com uma sequência de passos e etapas a serem seguidos.
Antes de iniciar um tutorial, é interessante que vocẽ salve a página de Glossário para futuras referências.
Básicos
Kubernetes básico é um tutorial interativo que auxilia no entendimento do ecossistema Kubernetes, bem como te permite testar algumas funcionalidades básicas do Kubernetes.
Introdução ao Kubernetes (edX) é um curso gratuíto da edX que te guia no entendimento do Kubernetes, seus conceitos, bem como na execução de tarefas mais simples.
Olá, Minikube! é um "Hello World" que te permite testar rapidamente o Kubernetes em sua estação com o uso do Minikube
Se você desejar escrever um tutorial, veja a página
Utilizando templates
para informações sobre o tipo de página e o formato a ser utilizado.
5.1 - Olá, Minikube!
Este tutorial mostra como executar uma aplicação exemplo no Kubernetes utilizando o Minikube e o Katacoda. O Katacoda disponibiliza um ambiente Kubernetes gratuito e acessível via navegador.
Nota: Você também consegue seguir os passos desse tutorial instalando o Minikube localmente. Para instruções de instalação, acesse: iniciando com minikube.
Objetivos
Instalar uma aplicação exemplo no minikube.
Executar a aplicação.
Visualizar os logs da aplicação.
Antes de você iniciar
Este tutorial disponibiliza uma imagem de contêiner que utiliza o NGINX para retornar todas as requisições.
Criando um cluster do Minikube
Clique no botão abaixo para iniciar o terminal do Katacoda.
Nota: Se você instalou o Minikube localmente, execute: minikube start.
Abra o painel do Kubernetes em um navegador:
minikube dashboard
Apenas no ambiente do Katacoda: Na parte superior do terminal, clique em Preview Port 30000.
Criando um Deployment
Um Pod Kubernetes consiste em um ou mais contêineres agrupados para fins de administração e gerenciamento de rede. O Pod desse tutorial possui apenas um contêiner. Um Deployment Kubernetes verifica a saúde do seu Pod e reinicia o contêiner do Pod caso o mesmo seja finalizado. Deployments são a maneira recomendada de gerenciar a criação e escalonamento dos Pods.
Usando o comando kubectl create para criar um Deployment que gerencia um Pod. O Pod executa um contêiner baseado na imagem docker disponibilizada.
NAME READY UP-TO-DATE AVAILABLE AGE
hello-node 1/1 1 1 1m
Visualizando o Pod:
kubectl get pods
A saída será semelhante a:
NAME READY STATUS RESTARTS AGE
hello-node-5f76cf6ccf-br9b5 1/1 Running 0 1m
Visualizando os eventos do cluster:
kubectl get events
Visualizando a configuração do kubectl:
kubectl config view
Nota: Para mais informações sobre o comando kubectl, veja o kubectl overview.
Criando um serviço
Por padrão, um Pod só é acessível utilizando o seu endereço IP interno no cluster Kubernetes. Para dispobiblilizar o contêiner hello-node fora da rede virtual do Kubernetes, você deve expor o Pod como um serviço Kubernetes.
O parâmetro --type=LoadBalancer indica que você deseja expor o seu serviço fora do cluster Kubernetes.
A aplicação dentro da imagem k8s.gcr.io/echoserver "escuta" apenas na porta TCP 8080. Se você usou
kubectl expose para expor uma porta diferente, os clientes não conseguirão se conectar a essa outra porta.
Visualizando o serviço que você acabou de criar:
kubectl get services
A saída será semelhante a:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-node LoadBalancer 10.108.144.78 <pending> 8080:30369/TCP 21s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 23m
Em provedores de Cloud que fornecem serviços de balanceamento de carga para o Kubernetes, um IP externo seria provisionado para acessar o serviço. No Minikube, o tipo LoadBalancer torna o serviço acessível por meio do comando minikube service.
Executar o comando a seguir:
minikube service hello-node
(Apenas no ambiente do Katacoda) Clicar no sinal de mais e então clicar em Select port to view on Host 1.
(Apenas no ambiente do Katacoda) Observe o número da porta com 5 dígitos exibido ao lado de 8080 na saída do serviço. Este número de porta é gerado aleatoriamente e pode ser diferente para você. Digite seu número na caixa de texto do número da porta e clique em Display Port. Usando o exemplo anterior, você digitaria 30369.
Isso abre uma janela do navegador, acessa o seu aplicativo e mostra o retorno da requisição.
Habilitando Complementos (addons)
O Minikube inclui um conjunto integrado de complementos que podem ser habilitados, desabilitados e executados no ambiente Kubernetes local.
Este tutorial fornece instruções básicas sobre o sistema de orquestração de cluster do Kubernetes. Cada módulo contém algumas informações básicas sobre os principais recursos e conceitos do Kubernetes e inclui um tutorial online interativo. Esses tutoriais interativos permitem que você mesmo gerencie um cluster simples e seus aplicativos em contêineres.
Usando os tutoriais interativos, você pode aprender a:
Implantar um aplicativo em contêiner em um cluster.
Dimensionar a implantação.
Atualizar o aplicativo em contêiner com uma nova versão do software.
Depurar o aplicativo em contêiner.
Os tutoriais usam Katacoda para executar um terminal virtual em seu navegador da Web, executado em Minikube, uma implantação local em pequena escala do Kubernetes que pode ser executada em qualquer lugar. Não há necessidade de instalar nenhum software ou configurar nada; cada tutorial interativo é executado diretamente no navegador da web.
O que o Kubernetes pode fazer por você?
Com os serviços da Web modernos, os usuários esperam que os aplicativos estejam disponíveis 24 horas por dia, 7 dias por semana, e os desenvolvedores esperam implantar novas versões desses aplicativos várias vezes ao dia. A conteinerização ajuda a empacotar o software para atender a esses objetivos, permitindo que os aplicativos sejam lançados e atualizados de maneira fácil e rápida, sem tempo de inatividade. O Kubernetes ajuda a garantir que esses aplicativos em contêiner sejam executados onde e quando você quiser e os ajuda a encontrar os recursos e ferramentas de que precisam para funcionar. Kubernetes é uma plataforma de código aberto pronta para produção, projetada com a experiência acumulada do Google em orquestração de contêineres, combinada com as melhores idéias da comunidade.
Inicie um cluster Kubernetes usando um terminal online.
Clusters do Kubernetes
O Kubernetes coordena um cluster com alta disponibilidade de computadores conectados para funcionar como uma única unidade.
As abstrações no Kubernetes permitem implantar aplicativos em contêineres em um cluster sem amarrá-los especificamente as máquinas individuais.
Para fazer uso desse novo modelo de implantação, os aplicativos precisam ser empacotados de uma forma que os desacoplem dos hosts individuais: eles precisam ser empacotados em contêineres. Os aplicativos em contêineres são mais flexíveis e disponíveis do que nos modelos de implantação anteriores, nos quais os aplicativos eram instalados diretamente em máquinas específicas como pacotes profundamente integrados ao host.
O Kubernetes automatiza a distribuição e o agendamento de contêineres de aplicativos em um cluster de maneira mais eficiente.
O Kubernetes é uma plataforma de código aberto e está pronto para produção.
Um cluster Kubernetes consiste em dois tipos de recursos:
A Camada de gerenciamento (Control Plane) coordena o cluster
Os Nós (Nodes) são os nós de processamento que executam aplicativos
Resumo:
Cluster do Kubernetes
Minikube
O Kubernetes é uma plataforma de código aberto de nível de produção que orquestra o agendamento e a execução de contêineres de aplicativos dentro e entre clusters de computador.
Diagrama de Cluster
A camada de gerenciamento é responsável por gerenciar o cluster. A camada de gerenciamento coordena todas as atividades em seu cluster, como programação de aplicativos, manutenção do estado desejado dos aplicativos, escalonamento de aplicativos e lançamento de novas atualizações.
Um nó é uma VM ou um computador físico que atua como um nó de processamento em um cluster Kubernetes. Cada nó tem um Kubelet, que é um agente para gerenciar o nó e se comunicar com a camada de gerenciamento do Kubernetes. O nó também deve ter ferramentas para lidar com operações de contêiner, como containerd ou Docker. Um cluster Kubernetes que lida com o tráfego de produção deve ter no mínimo três nós.
As camadas de gerenciamento gerenciam o cluster e os nós que são usados para hospedar os aplicativos em execução.
Ao implantar aplicativos no Kubernetes, você diz à camada de gerenciamento para iniciar os contêineres de aplicativos. A camada de gerenciamento agenda os contêineres para serem executados nos nós do cluster. Os nós se comunicam com o camada de gerenciamento usando a API do Kubernetes , que a camada de gerenciamento expõe. Os usuários finais também podem usar a API do Kubernetes diretamente para interagir com o cluster.
Um cluster Kubernetes pode ser implantado em máquinas físicas ou virtuais. Para começar o desenvolvimento do Kubernetes, você pode usar o Minikube. O Minikube é uma implementação leve do Kubernetes que cria uma VM em sua máquina local e implanta um cluster simples contendo apenas um nó. O Minikube está disponível para sistemas Linux, macOS e Windows. A linha de comando (cli) do Minikube fornece operações básicas de inicialização para trabalhar com seu cluster, incluindo iniciar, parar, status e excluir. Para este tutorial, no entanto, você usará um terminal online fornecido com o Minikube pré-instalado.
Agora que você sabe o que é Kubernetes, vamos para o tutorial online e iniciar nosso primeiro cluster!
5.2.2.1 - Usando kubectl para criar uma implantação
Objetivos
Saiba mais sobre implantações de aplicativos.
Implante seu primeiro aplicativo no Kubernetes com o kubectl.
Implantações do Kubernetes
Assim que o seu cluster Kubernetes estiver em execução você pode implementar seu aplicativo em contêiners nele.
Para fazer isso, você precisa criar uma configuração do tipo Deployment do Kubernetes. O Deployment define como criar e
atualizar instâncias do seu aplicativo. Depois de criar um Deployment, o Master do Kubernetes
agenda as instâncias do aplicativo incluídas nesse Deployment para ser executado em nós individuais do Cluster.
Depois que as instâncias do aplicativo são criadas, um Controlador do Kubernetes Deployment monitora continuamente essas instâncias.
Se o nó que hospeda uma instância ficar inativo ou for excluído, o controlador de Deployment substituirá a instância por uma instância em outro nó no cluster.
Isso fornece um mecanismo de autocorreção para lidar com falhas ou manutenção da máquina.
Em um mundo de pré-orquestração, os scripts de instalação costumavam ser usados para iniciar aplicativos, mas não permitiam a recuperação de falha da máquina.
Ao criar suas instâncias de aplicativo e mantê-las em execução entre nós, as implantações do Kubernetes fornecem uma abordagem fundamentalmente diferente para o gerenciamento de aplicativos.
Resumo:
Deployments
Kubectl
O tipo Deployment é responsável por criar e atualizar instâncias de seu aplicativo
Implantar seu primeiro aplicativo no Kubernetes
Você pode criar e gerenciar uma implantação usando a interface de linha de comando do Kubernetes, Kubectl .
O Kubectl usa a API Kubernetes para interagir com o cluster. Neste módulo, você aprenderá os comandos Kubectl mais comuns necessários para criar implantações que executam seus aplicativos em um cluster Kubernetes.
Quando você cria um Deployment, você precisa especificar a imagem do contêiner para seu aplicativo e o número de réplicas que deseja executar.
Você pode alterar essas informações posteriormente, atualizando sua implantação; Módulos5 e 6 do bootcamp explica como você pode dimensionar e atualizar suas implantações.
Os aplicativos precisam ser empacotados em um dos formatos de contêiner suportados para serem implantados no Kubernetes
Para sua primeira implantação, você usará um aplicativo Node.js empacotado em um contêiner Docker.(Se você ainda não tentou criar um aplicativo Node.js e implantá-lo usando um contêiner, você pode fazer isso primeiro seguindo as instruções do tutorial Olá, Minikube!).
Agora que você sabe o que são implantações (Deployment), vamos para o tutorial online e implantar nosso primeiro aplicativo!
5.2.2.2 - Tutorial interativo - implantando um aplicativo
Um pod é a unidade de execução básica de um aplicativo Kubernetes. Cada pod representa uma parte de uma carga de trabalho em execução no cluster. Saiba mais sobre pods.
Para interagir com o Terminal, use a versão desktop/tablet
Solucionar problemas de aplicativos implantados no Kubernetes.
Kubernetes Pods
Quando você criou um Deployment no Módulo 2, o Kubernetes criou um Pod para hospedar a instância do seu aplicativo. Um Pod é uma abstração do Kubernetes que representa um grupo de um ou mais contêineres de aplicativos (como Docker) e alguns recursos compartilhados para esses contêineres. Esses recursos incluem:
Armazenamento compartilhado, como Volumes
Rede, como um endereço IP único no cluster
Informações sobre como executar cada contêiner, como a versão da imagem do contêiner ou portas específicas a serem usadas
Um Pod define um "host lógico" específico para o aplicativo e pode conter diferentes contêineres que, na maioria dos casos, são fortemente acoplados. Por exemplo, um Pod pode incluir o contêiner com seu aplicativo Node.js, bem como um outro contêiner que alimenta os dados a serem publicados pelo servidor web Node.js. Os contêineres de um Pod compartilham um endereço IP e intervalo de portas; são sempre localizados, programados e executam em um contexto compartilhado no mesmo Nó.
Pods são a unidade atômica na plataforma Kubernetes. Quando criamos um Deployment no Kubernetes, esse Deployment cria Pods com contêineres dentro dele (em vez de você criar contêineres diretamente). Cada Pod está vinculado ao nó onde está programado (scheduled) e lá permanece até o encerramento (de acordo com a política de reinicialização) ou exclusão. Em caso de falha do nó, Pods idênticos são programados em outros nós disponíveis no cluster.
Sumário:
Pods
Nós (Nodes)
Principais comandos do Kubectl
Um Pod é um grupo de um ou mais contêineres de aplicativos (como Docker) que inclui armazenamento compartilhado (volumes), endereço IP e informações sobre como executá-los.
Visão geral sobre os Pods
Nós (Nodes)
Um Pod sempre será executando em um Nó. Um Nó é uma máquina de processamento em um cluster Kubernetes e pode ser uma máquina física ou virtual. Cada Nó é gerenciado pelo Control Plane. Um Nó pode possuir múltiplos Pods e o Control Plane do Kubernetes gerencia automaticamente o agendamento dos Pods nos nós do cluster. Para o agendamento automático dos Pods, o Control Plane leva em consideração os recursos disponíveis em cada Nó.
Cada Nó do Kubernetes executa pelo menos:
Kubelet, o processo responsável pela comunicação entre o Control Plane e o Nó; gerencia os Pods e os contêineres rodando em uma máquina.
Um runtime de contêiner (por exemplo o Docker) é responsável por baixar a imagem do contêiner de um registro de imagens (por exemplo o Docker Hub), extrair o contêiner e executar a aplicação.
Os contêineres só devem ser agendados juntos em um único Pod se estiverem fortemente acoplados e precisarem compartilhar recursos, como disco e IP.
Visão Geral sobre os Nós
Solucionar problemas usando o comando kubectl
No Módulo 2, você usou o comando Kubectl. Você pode continuar utilizando o Kubectl no Módulo 3 para obter informação sobre Deployment realizado e seus recursos. As operações mais comuns podem ser realizadas com os comandos abaixo:
kubectl get - listar recursos
kubectl describe - mostrar informações detalhadas sobre um recurso
kubectl logs - mostrar os logs de um container em um Pod
kubectl exec - executar um comando em um contêiner em um Pod
Você pode usar esses comandos para verificar quando o Deployment foi realizado, qual seu status atual, ondes os Pods estão rodando e qual são as suas configurações.
Agora que sabemos mais sobre os componentes de um cluster Kubernetes e o comando kubectl, vamos explorar a nossa aplicação.
Um nó é uma máquina operária do Kubernetes e pode ser uma VM ou máquina física, dependendo do cluster. Vários Pods podem ser executados em um nó.
5.2.4.1 - Utilizando um serviço para expor seu aplicativo
Objetivos
Aprenda sobre um Serviço no Kubernetes
Entenda como os objetos labels e LabelSelector se relacionam a um Serviço
Exponha uma aplicação externamente ao cluster Kubernetes usando um Serviço
Visão Geral de Serviços Kubernetes
Pods Kubernetes são efêmeros. Na verdade, Pods possuem um ciclo de vida. Quando um nó de processamento morre, os Pods executados no nó também são perdidos. A partir disso, o ReplicaSet pode dinamicamente retornar o cluster ao estado desejado através da criação de novos Pods para manter sua aplicação em execução. Como outro exemplo, considere um backend de processamento de imagens com 3 réplicas. Estas réplicas são intercambiáveis; o sistema front-end não deveria se importar com as réplicas backend ou ainda se um Pod é perdido ou recriado. Dito isso, cada Pod em um cluster Kubernetes tem um único endereço IP, mesmo Pods no mesmo nó, então há necessidade de ter uma forma de reconciliar automaticamente mudanças entre Pods de modo que sua aplicação continue funcionando.
Um serviço no Kubernetes é uma abstração que define um conjunto lógico de Pods e uma política pela qual acessá-los. Serviços permitem um baixo acoplamento entre os Pods dependentes. Um serviço é definido usando YAML (preferencialmente) ou JSON, como todos objetos Kubernetes. O conjunto de Pods selecionados por um Serviço é geralmente determinado por um seletor de rótulos LabelSelector (veja abaixo o motivo pelo qual você pode querer um Serviço sem incluir um seletor selector na especificação spec).
Embora cada Pod tenha um endereço IP único, estes IPs não são expostos externamente ao cluster sem um Serviço. Serviços permitem que suas aplicações recebam tráfego. Serviços podem ser expostos de formas diferentes especificando um tipo type na especificação do serviço ServiceSpec:
ClusterIP (padrão) - Expõe o serviço sob um endereço IP interno no cluster. Este tipo faz do serviço somente alcançável de dentro do cluster.
NodePort - Expõe o serviço sob a mesma porta em cada nó selecionado no cluster usando NAT. Faz o serviço acessível externamente ao cluster usando <NodeIP>:<NodePort>. Superconjunto de ClusterIP.
LoadBalancer - Cria um balanceador de carga externo no provedor de nuvem atual (se suportado) e assinala um endereço IP fixo e externo para o serviço. Superconjunto de NodePort.
ExternalName - Expõe o serviço usando um nome arbitrário (especificado através de externalName na especificação spec) retornando um registro de CNAME com o nome. Nenhum proxy é utilizado. Este tipo requer v1.7 ou mais recente de kube-dns.
Adicionalmente, note que existem alguns casos de uso com serviços que envolvem a não definição de selector em spec. Serviços criados sem selector também não criarão objetos Endpoints correspondentes. Isto permite usuários mapear manualmente um serviço a endpoints específicos. Outra possibilidade na qual pode não haver seletores é ao se utilizar estritamente type: ExternalName.
Resumo
Expõe Pods ao tráfego externo
Tráfego de balanceamento de carga entre múltiplos Pods
Uso de rótulos labels
Um serviço Kubernetes é uma camada de abstração que define um conjunto lógico de Pods e habilita a exposição ao tráfego externo, balanceamento de carga e descoberta de serviço para esses Pods.
Serviços e Rótulos
Um serviço roteia tráfego entre um conjunto de Pods. Serviço é a abstração que permite pods morrerem e se replicarem no Kubernetes sem impactar sua aplicação. A descoberta e o roteamento entre Pods dependentes (tal como componentes frontend e backend dentro de uma aplicação) são controlados por serviços Kubernetes.
Serviços relacionam um conjunto de Pods usando Rótulos e seletores, um agrupamento primitivo que permite operações lógicas sobre objetos Kubernetes. Rótulos são pares de chave/valor anexados à objetos e podem ser usados de inúmeras formas:
Designar objetos para desenvolvimento, teste e produção
Adicionar tags de versão
Classificar um objeto usando tags
Rótulos podem ser anexados à objetos no momento de sua criação ou posteriormente. Eles podem ser modificados a qualquer tempo. Vamos agora expor sua aplicação usando um serviço e aplicar alguns rótulos.
5.2.5.1 - Executando múltiplas instâncias de seu aplicativo
Objetivos
Escalar uma aplicação usando kubectl.
Escalando uma aplicação
Nos módulos anteriores nós criamos um Deployment, e então o expusemos publicamente através de um serviço (Service). O Deployment criou apenas um único Pod para executar nossa aplicação. Quando o tráfego aumentar nós precisaremos escalar a aplicação para suportar a demanda de usuários.
O escalonamento é obtido pela mudança do número de réplicas em um Deployment
Resumo:
Escalando um Deployment
Você pode criar desde o início um Deployment com múltiplas instâncias usando o parâmetro --replicas para que o kubectl crie o comando de deployment
Escalar um Deployment garantirá que novos Pods serão criados e agendados para nós de processamento com recursos disponíveis. O escalonamento aumentará o número de Pods para o novo estado desejado. O Kubernetes também suporta o auto-escalonamento (autoscaling) de Pods, mas isso está fora do escopo deste tutorial. Escalar para zero também é possível, e isso terminará todos os Pods do Deployment especificado.
Executar múltiplas instâncias de uma aplicação irá requerer uma forma de distribuir o tráfego entre todas elas. Serviços possuem um balanceador de carga integrado que distribuirá o tráfego de rede entre todos os Pods de um Deployment exposto. Serviços irão monitorar continuamente os Pods em execução usando endpoints para garantir que o tráfego seja enviado apenas para Pods disponíveis.
O Escalonamento é obtido pela mudança do número de réplicas em um Deployment.
No momento em que múltiplas instâncias de uma aplicação estiverem em execução será possível realizar atualizações graduais no cluster sem que ocorra indisponibilidade. Nós cobriremos isso no próximo módulo. Agora, vamos ao terminal online e escalar nossa aplicação.
kubeadm - Ferramenta CLI para provisionar facilmente um cluster Kubernetes seguro.
Referência de configuração
kubelet - O principal agente do nó que é executado em cada nó. O kubelet usa um conjunto de PodSpecs e garante que os contêineres descritos estejam funcionando e saudáveis.
kube-apiserver - API REST que valida e configura dados para objetos de API, como pods, serviços, controladores de replicação.
kube-controller-manager - Daemon que incorpora os principais loops de controle enviados com o Kubernetes.
kube-proxy - É possível fazer o encaminhamento de fluxo TCP/UDP de forma simples ou utilizando o algoritimo de Round Robin encaminhando através de um conjunto de back-ends.
kube-scheduler - Agendador que gerencia disponibilidade, desempenho e capacidade.
Essa página demonstra uma visão geral sobre autenticação
Usuários no Kubernetes
Todos os clusters Kubernetes possuem duas categorias de usuários: contas de serviço gerenciadas pelo Kubernetes e usuários normais.
Assume-se que um serviço independente do cluster gerencia usuários normais das seguintes formas:
Um administrador distribuindo chaves privadas
Uma base de usuários como Keystone
Keystone é o serviço de identidade usado pelo OpenStack para autenticação (authN) e autorização de alto nível (authZ). Atualmente, ele oferece suporte a authN com base em token e autorização de serviço do usuário. Recentemente, foi reprojetado para permitir a expansão para oferecer suporte a serviços externos de proxy e mecanismos AuthN / AuthZ, como oAuth, SAML e openID em versões futuras.
ou Google Accounts
Um arquivo com uma lista de nomes de usuários e senhas
Neste quesito, Kubernetes não possui objetos que possam representar as contas de um usuário normal. Usuários normais não podem ser adicionados ao cluster através de uma chamada para a API.
Apesar de um usuário normal não poder ser adicionado através de uma chamada para a API, qualquer usuário que apresente um certificado válido e assinado pela autoridade de certificados (CA) do cluster é considerado autenticado. Nesta configuração, Kubernetes determina o nome do usuário baseado no campo de nome comum no sujeito (subject) do certificado (por exemplo: "/CN=bob"). A partir daí, o subsistema de controle de acesso baseado em função (RBAC) determina se o usuário é autorizado a realizar uma operação específica sobre o recurso. Para mais detalhes, veja a referência sobre o tópico de usuários normais dentro de requisição de certificado.
Em contraste a usuários normais, contas de serviço são considerados usuários gerenciados pela API do Kubernetes. Elas estão vinculadas à namespaces específicas e criadas automaticamente pelo servidor de API ou manualmente através de chamadas da API. Contas de serviço estão ligadas a um conjunto de credenciais armazenados como Secrets, aos quais são montados dentro dos pods assim permitindo que processos internos ao cluster comuniquem-se com a API do Kubernetes.
Requisições para a API estão ligadas a um usuário normal, conta de serviço ou serão tratadas como requisições anônimas. Isto significa que cada processo dentro ou fora do cluster, desde um usuário humano utilizando o kubectl de uma estação de trabalho, a kubelets rodando nos nós, a membros da camada de gerenciamento (s/painel de controle) devem autenticar-se ao realizarem suas requisições para o servidor API ou serão tratados como usuário anônimo.
Estratégias de autenticação
Kubernetes usa certificados de clientes, bearer Token, um proxy realizando autenticação, ou uma autenticação básica HTTP para autenticar requisições para o servidor de API através de plugins. Como requisições HTTP são feitas no servidor de API, plugins tentam associar os seguintes atributos junto a requisição:
Username
Um nome de usuário é um nome que identifica exclusivamente alguém em um sistema de computador. Por exemplo, um computador pode ser configurado com várias contas, com nomes de usuário diferentes para cada conta. Muitos sites permitem que os usuários escolham um nome de usuário para que possam personalizar suas configurações ou configurar uma conta online. Por exemplo, seu banco pode permitir que você escolha um nome de usuário para acessar suas informações bancárias. Você pode precisar escolher um nome de usuário para postar mensagens em um determinado quadro de mensagens na web. Os serviços de e-mail, como o Hotmail, exigem que os usuários escolham um nome de usuário para usar o serviço.
Um nome de usuário geralmente é pareado com uma senha. Essa combinação de nome de usuário / senha é conhecida como login e geralmente é necessária para que os usuários façam login em sites. Por exemplo, para acessar seu e-mail pela Web, é necessário inserir seu nome de usuário e senha. Depois de fazer o login, seu nome de usuário pode aparecer na tela, mas sua senha é mantida em segredo. Ao manter sua senha privada, as pessoas podem criar contas seguras para vários sites. A maioria dos nomes de usuário pode conter letras e números, mas não espaços. Quando você escolhe um nome de usuário para uma conta de e-mail, a parte antes de "@" é o seu nome de usuário.
: um valor (String) que identifica o usuário final. Valores comuns podem ser kube-admin ou jane@example.com
UID
Um identificador exclusivo (UID) é uma sequência numérica ou alfanumérica associada a uma única entidade em um determinado sistema. Os UIDs tornam possível endereçar essa entidade para que ela possa ser acessada e interagida. Cada usuário é identificado no sistema por seu UID e os nomes de usuário geralmente são usados apenas como uma interface para humanos.
: um valor (String) que identifica o usuário final e tenta ser mais consistente e único do que username.
Groups: Um conjunto de valores em que cada item indica a associação de um usuário à uma coleção lógica de usuários. Valores comuns podem ser system:masters ou devops-team.
Campos extras: um mapa que pode conter uma lista de atributos que armazena informações adicionais em que autorizadores podem achar útil.
Todos os valores são transparentes para o sistema de autenticação e somente trazem significado quando interpretados por um autorizador.
É possível habilitar múltiplos métodos de autenticação. Deve-se normalmente usar pelo menos dois métodos:
Tokens para contas de serviço;
Pelo menos um outro método de autenticação para usuários.
Quando múltiplos módulos de autenticação estão habilitados, o primeiro módulo a autenticar com sucesso uma requisição termina, o fluxo de avaliação da mesma.
O servidor de API não garante a ordem em que os autenticadores são processados.
O grupo system:authenticated é incluído na lista de grupos de todos os usuários autenticados.
Integrações com outros protocolos de autenticação, como LDAP
Abreviatura para "Lightweight Directory Access Protocol". Se você deseja disponibilizar informações de diretório na Internet, esta é a maneira de fazê-lo. O LDAP é uma versão simplificada de um padrão de diretório anterior denominado X.500. O que torna o LDAP tão útil é que ele funciona muito bem em redes TCP / IP (ao contrário do X.500), de modo que as informações podem ser acessadas por meio do LDAP por qualquer pessoa com uma conexão à Internet. Também é um protocolo aberto, o que significa que os diretórios podem ser armazenados em qualquer tipo de máquina (por exemplo, Windows 2000, Red Hat Linux, Mac OS X).
Para dar uma ideia de como um diretório LDAP é organizado, aqui estão os diferentes níveis de uma hierarquia de árvore LDAP simples:
O diretório raiz
Países
Organizações
Divisões, departamentos, etc.
Indivíduos
Recursos individuais, como arquivos e impressoras.
A maior parte da conectividade LDAP é feita nos bastidores, então o usuário típico provavelmente não notará ao navegar na web. No entanto, é uma boa tecnologia para se conhecer. Se nada mais, é outro termo para impressionar seus pais.
, SAML
SAML significa Linguagem de Marcação para Asserção de Segurança. É um padrão aberto baseado em XML para transferência de dados de identidade entre duas partes: um provedor de identidade (IdP) e um provedor de serviços (SP).
Provedor de identidade - executa autenticação e passa a identidade do usuário e o nível de autorização para o provedor de serviços.
Provedor de serviços - confia no provedor de identidade e autoriza o usuário fornecido a acessar o recurso solicitado.
A autenticação de logon único SAML normalmente envolve um provedor de serviços e um provedor de identidade. O fluxo do processo geralmente envolve os estágios de estabelecimento de confiança e fluxo de autenticação.
Considere este exemplo:
Nosso provedor de identidade é Auth0
Nosso provedor de serviços é um serviço fictício, Zagadat
Nota: O provedor de identidade pode ser qualquer plataforma de gerenciamento de identidade.
Agora, um usuário está tentando obter acesso ao Zagadat usando a autenticação SAML.
Este é o fluxo do processo:
O usuário tenta fazer login no Zagadat a partir de um navegador.
O Zagadat responde gerando uma solicitação SAML.
, Kerberos
Kerberos é um protocolo de rede que usa criptografia de chave secreta para autenticar aplicativos cliente-servidor. O Kerberos solicita um tíquete criptografado por meio de uma sequência de servidor autenticada para usar os serviços.
Kerberos foi desenvolvido pelo Project Athena - um projeto conjunto entre o Massachusetts Institute of Technology (MIT), Digital Equipment Corporation e IBM que funcionou entre 1983 e 1991.
Um servidor de autenticação usa um tíquete Kerberos para conceder acesso ao servidor e, em seguida, cria uma chave de sessão com base na senha do solicitante e outro valor aleatório. O tíquete de concessão de tíquete (TGT) é enviado ao servidor de concessão de tíquete (TGS), que é necessário para usar o mesmo servidor de autenticação.
O solicitante recebe uma chave TGS criptografada com um registro de data e hora e um tíquete de serviço, que é retornado ao solicitante e descriptografado. O solicitante envia ao TGS essas informações e encaminha a chave criptografada ao servidor para obter o serviço desejado. Se todas as ações forem tratadas corretamente, o servidor aceita o tíquete e realiza o atendimento ao usuário desejado, que deve descriptografar a chave, verificar a data e hora e entrar em contato com o centro de distribuição para obter as chaves de sessão. Essa chave de sessão é enviada ao solicitante, que descriptografa o tíquete.
Se as chaves e o carimbo de data / hora forem válidos, a comunicação cliente-servidor continuará. O tíquete TGS tem carimbo de data / hora, o que permite solicitações simultâneas dentro do período de tempo alocado.
, alternate x509 schemes
X.509 é um formato padrão para certificados de chave pública, documentos digitais que associam com segurança pares de chaves criptográficas a identidades como sites, indivíduos ou organizações.
Introduzido pela primeira vez em 1988 junto com os padrões X.500 para serviços de diretório eletrônico, o X.509 foi adaptado para uso na Internet pelo grupo de trabalho Public-Key Infrastructure (X.509) (PKIX) da IETF. O RFC 5280 define o perfil do certificado X.509 v3, a lista de revogação de certificado X.509 v2 (CRL) e descreve um algoritmo para a validação do caminho do certificado X.509.
As aplicações comuns de certificados X.509 incluem:
- SSL / TLS e HTTPS para navegação na web autenticada e criptografada
- E-mail assinado e criptografado por meio do protocolo S / MIME
- Assinatura de código
- Assinatura de documento
- Autenticação de cliente
- Identificação eletrônica emitida pelo governo
, etc, podem ser alcançadas utilizando-se de um proxy ou webhook de autenticação.
Certificados de cliente X509
Autenticação via certificados de cliente pode ser habilitada ao passar a opção --client-ca-file=ARQUIVO para o servidor de API. O arquivo referenciado deve conter um ou mais autoridades de certificação usadas para validar o certificado de cliente passado para o servidor de API. Se o certificado de cliente é apresentado e verificado, o common name
O nome comum é normalmente composto de Host + Nome de domínio e será semelhante a www.seusite.com ou seusite.com. Os certificados de servidor SSL são específicos para o nome comum para o qual foram emitidos no nível do host.
O nome comum deve ser igual ao endereço da Web que você acessará ao se conectar a um site seguro. Por exemplo, um certificado de servidor SSL para o domínio domínio.com receberá um aviso do navegador se o acesso a um site chamado www.domain.com ou secure.domain.com, pois www.domain.com e secure.domain.com são diferentes de dominio.com. Você precisaria criar um CSR para o nome comum correto.
do sujeito é usado como o nome de usuário para a requisição. A partir da versão 1.4, certificados de cliente podem também indicar o pertencimento de um usuário a um grupo utilizando o campo de organização do certificado. Para incluir múltiplos grupos para o usuário, deve-se incluir múltiplos campos de organização no certificado.
Por exemplo, utilizando o comando de linha openssl para gerar uma requisição de assinatura de certificado:
O servidor de API lê bearer tokens de um arquivo quando recebe uma requisição contendo a opção --token-auth-file=ARQUIVO via linha de comando. Atualmente, tokens têm duração indefinida, e a lista de tokens não pode ser modificada sem reiniciar o servidor de API.
O arquivo de token é do tipo CSV contendo no mínimo 3 colunas: token, nome de usuário, identificador de usuário (uid), seguido pelos nomes de grupos (opcional).
Nota:
Se uma entrada possuir mais de um grupo, a coluna deve ser cercada por aspas duplas, por exemplo:
token,usuario,uid,"grupo1,grupo2,grupo3"
Adicionando um bearer token em uma requisição
Quando utilizando-se de bearer token para autenticação de um cliente HTTP, o servidor de API espera um cabeçalho Authorization com um valor Bearer TOKEN. O token deve ser uma sequência de caracteres que pode ser colocada como valor em um cabeçalho HTTP não utilizando-se mais do que as facilidades de codificação e citação de HTTP. Por exemplo, se o valor de um token é 31ada4fd-adec-460c-809a-9e56ceb75269 então iria aparecer dentro de um cabeçalho HTTP como:
Para permitir a inicialização simplificada para novos clusters, Kubernetes inclui um token dinamicamente gerenciado denominado Bootstrap Token. Estes tokens são armazenados como Secrets dentro do namespace kube-system, onde eles podem ser dinamicamente criados e gerenciados. O componente Gerenciador de Controle (Controller Manager) possui um controlador "TokenCleaner" que apaga os tokens de inicialização expirados.
Os tokens seguem o formato [a-z0-9]{6}.[a-z0-9]{16}. O primeiro componente é um identificador do token e o segundo é o segredo. Você pode especificar o token como um cabeçalho HTTP como:
Authorization: Bearer 781292.db7bc3a58fc5f07e
Deve-se habilitar os tokens de inicialização com a opção --enable-bootstrap-token-auth no servidor de API. Deve-se habilitar o controlador TokenCleaner através da opção --controllers no Gerenciador de Controle. Isso é feito, por exemplo, como: --controllers=*,tokencleaner. O kubeadm, por exemplo, irá realizar isso caso seja utilizado para a inicialização do cluster.
O autenticador o autentica como system:bootstrap:<Token ID> e é incluído no grupo system:bootstrappers. O nome e grupo são intencionalmente limitados para desencorajar usuários a usarem estes tokens após inicialização. Os nomes de usuários e grupos podem ser utilizados (e são utilizados pelo kubeadm) para elaborar as políticas de autorização para suportar a inicialização de um cluster.
Por favor veja Bootstrap Tokens para documentação detalhada sobre o autenticador e controladores de Token de inicialização, bem como gerenciar estes tokens com kubeadm.
Tokens de Contas de serviço
Uma conta de serviço é um autenticador habilitado automaticamente que usa bearer tokens para verificar as requisições. O plugin aceita dois parâmetros opcionais:
--service-account-key-file Um arquivo contendo uma chave codificada no formato PEM para assinar bearer tokens. Se não especificado, a chave privada de TLS no servidor de API será utilizada
--service-account-lookup Se habilitado, tokens deletados do servidor de API serão revogados.
Contas de serviço são normalmente criadas automaticamente pelo servidor de API e associada a pods rodando no cluster através do controlador de admissão Admission Controller de ServiceAccount. Os tokens de contas de serviços são montados nos Pods, em localizações já pré definidas e conhecidas e permitem processos dentro do cluster a se comunicarem com o servidor de API. Contas podem ser explicitamente associadas com pods utilizando o campo serviceAccountName na especificação do pod (PodSpec):
Nota:serviceAccountName é normalmente omitida por ser feito automaticamente
Os tokens de contas de serviço são perfeitamente válidos para ser usados fora do cluster e podem ser utilizados para criar identidades para processos de longa duração que desejem comunicar-se com a API do Kubernetes. Para criar manualmente uma conta de serviço, utilize-se simplesmente o comando kubectl create serviceaccount (NOME). Isso cria uma conta de serviço e um segredo associado a ela no namespace atual.
O segredo criado irá armazenar a autoridade de certificado do servidor de API e um JSON Web Token (JWT) digitalmente assinado.
kubectl get secret jenkins-token-1yvwg -o yaml
apiVersion:v1data:ca.crt:(APISERVER'S CA BASE64 ENCODED)namespace:ZGVmYXVsdA==token:(BEARER TOKEN BASE64 ENCODED)kind:Secretmetadata:# ...type:kubernetes.io/service-account-token
Nota: Valores são codificados em base64 porque segredos são sempre codificados neste formato.
O JWT assinado pode ser usado como um bearer token para autenticar-se como a conta de serviço. Veja acima como o token pode ser incluído em uma requisição. Normalmente esses segredos são montados no pod para um acesso interno ao cluster ao servidor de API, porém pode ser utilizado fora do cluster também.
Contas de serviço são autenticadas com o nome de usuário system:serviceaccount:(NAMESPACE):(SERVICEACCOUNT) e são atribuídas aos grupos system:serviceaccounts e system:serviceaccounts:(NAMESPACE).
AVISO: porque os tokens das contas de serviço são armazenados em segredos, qualquer usuário com acesso de leitura a esses segredos podem autenticar-se como a conta de serviço. Tome cuidado quando conceder permissões a contas de serviços e capacidade de leitura de segredos.
Tokens OpenID Connect
OpenID Connect é uma variação do framework de autorização OAuth2 que suporta provedores como Azure Active Directory, Salesforce, e Google. A principal extensão do OAuth2 é um campo adicional de token de acesso chamado ID Token. Este token é um tipo de JSON Web Token (JWT) com campos bem definidos, como usuário, e-mail e é assinado pelo servidor de autorização.
Para identificar o usuário, o autenticador usa o id_token (e não access_token) do bearer token da resposta de autorização do OAuth2 token response. Veja acima como incluir um token em uma requisição.
sequenceDiagram
participant usuário as Usuário
participant IDP as Provedor de Identidade
participant kube as Kubectl
participant API as API Server
usuário ->> IDP: 1. Realizar Login no IdP
activate IDP
IDP -->> usuário: 2. Fornece access_token, id_token, e refresh_token
deactivate IDP
activate usuário
usuário ->> kube: 3. Entrar Kubectl com --token sendo id_token ou adiciona tokens no arquivo .kube/config
deactivate usuário
activate kube
kube ->> API: 4. Emite requisição incluindo o cabeçalho HTTP Authorization: Bearer...
deactivate kube
activate API
API ->> API: 5. O token do tipo JWT possui assinatura válida ?
API ->> API: 6. O token está expirado ? (iat+exp)
API ->> API: 7. Usuário autorizado ?
API -->> kube: 8. Autorizado: Realiza ação e retorna resultado
deactivate API
activate kube
kube --x usuário: 9. Retorna resultado
deactivate kube
Login no seu provedor de identidade.
Seu provedor de identidade ira fornecer um access_token, id_token e um refresh_token.
Quando utilizando kubectl, utilize do seu id_token com a opção --token ou adicione o token diretamente no seu arquivo de configuração kubeconfig.
kubectl envia o seu id_token em um cabeçalho HTTP chamado Authorization para o servidor de API.
O servidor de API irá garantir que a assinatura do token JWT é válida, verificando-o em relação ao certificado mencionado na configuração.
Verificação para garantir que oid_token não esteja expirado.
Garantir que o usuário é autorizado.
Uma vez autorizado o servidor de API retorna a resposta para o kubectl.
kubectl fornece retorno ao usuário.
Uma vez que todos os dados necessários para determinar sua identidade encontram-se no id_token, Kubernetes não precisa realizar outra chamada para o provedor de identidade. Em um modelo onde cada requisição não possui estado, isso fornece uma solução escalável para autenticação. Isso, porem, apresenta alguns desafios:
Kubernetes não possui uma "interface web" para disparar o processo de autenticação. Não há browser ou interface para coletar credenciais que são necessárias para autenticar-se primeiro no seu provedor de identidade.
O id_token não pode ser revogado, funcionando como um certificado, portanto deve possuir curta validade (somente alguns minutos) o que pode tornar a experiência um pouco desconfortável, fazendo com que se requisite um novo token toda vez em um curto intervalo (poucos minutos de validade do token)
Para autenticar-se ao dashboard Kubernetes, você deve executar o comando kubectl proxy ou um proxy reverso que consiga injetar o id_token.
Configurando o Servidor de API
Para habilitar o plugin de autorização, configure as seguintes opções no servidor de API:
Parâmetro
Descrição
Exemplo
Obrigatório
--oidc-issuer-url
URL do provedor que permite ao servidor de API descobrir chaves públicas de assinatura. Somente URLs que usam o esquema https:// são aceitas. Isto normalmente é o endereço de descoberta do provedor sem o caminho, por exemplo "https://accounts.google.com" ou "https://login.salesforce.com". Esta URL deve apontar para o nível abaixo do caminho .well-known/openid-configuration
Se o valor da URL de descoberta é https://accounts.google.com/.well-known/openid-configuration, entao o valor deve ser https://accounts.google.com
Sim
--oidc-client-id
Identificador do cliente para o qual todos os tokens são gerados.
kubernetes
Sim
--oidc-username-claim
Atributo do JWT a ser usado como nome de usuário. Por padrão o valor sub, o qual é esperado que seja um identificador único do usuário final. Administradores podem escolher outro atributo, como email ou name, dependendo de seu provedor de identidade. No entanto, outros atributos além de email serão prefixados com a URL do emissor issuer URL para prevenir conflitos de nome com outros plugins.
sub
Não
--oidc-username-prefix
Prefixos adicionados ao atributo de nome de usuário para prevenir conflitos de nomes existentes (como por exemplo usuários system:). Por exemplo, o valor oidc: irá criar usuários como oidc:jane.doe. Se esta opção não for fornecida --oidc-username-claim e um valor diferente de email irá conter um prefixo padrão com o valor de ( Issuer URL )# onde ( Issuer URL ) era o valor da opção --oidc-issuer-url. O valor - pode ser utilizado para desabilitar todos os prefixos.
oidc:
Não
--oidc-groups-claim
Atributo do JWT a ser utilizado para mapear os grupos dos usuários. Se o atributo está presente, ele deve ser do tipo vetor de Strings.
groups
Não
--oidc-groups-prefix
Prefixo adicionados ao atributo de grupo para prevenir conflitos de nomes existentes (como por exemplo system: grupos). Por exemplo, o valor oidc: irá criar nomes de grupos como oidc:engineering e oidc:infra.
oidc:
Não
--oidc-required-claim
Um par de chave=valor que descreve atributos obrigatórios no ID Token. Se configurado, a presença do atributo é verificado dentro do ID Token com um valor relacionado. Repita esta opção para configurar múltiplos atributos obrigatórios.
claim=value
Não
--oidc-ca-file
O caminho para o arquivo de certificado da autoridade de certificados (CA) que assinou o certificado do provedor de identidades.
/etc/kubernetes/ssl/kc-ca.pem
Não
É importante ressaltar que o servidor de API não é um cliente Oauth2, ao contrário, ele só pode ser configurado para confiar em um emissor. Isso permite o uso de emissores públicos, como Google, sem confiar em credenciais emitidas por terceiros. Administradores que desejam utilizar-se de múltiplos clientes OAuth2 devem explorar provedores os quais suportam atributos azp (parte autorizada), que é um mecanismo para permitir um cliente a emitir tokens em nome de outro.
Kubernetes não oferece um provedor de identidade OpenID Connect. Pode-se utilizar provedores públicos existentes como Google ou outros. Ou, pode-se rodar o próprio provedor de identidade no cluster, como dex,
Keycloak,
CloudFoundry UAA, ou
Tremolo Security's OpenUnison.
Para um provedor de identidades funcionar no Kubernetes, ele deve:
Executar TLS com cifras criptográficas não obsoletos.
Possuir certificados assinados por uma Autoridade certificadora (mesmo que o CA não seja comercial ou seja auto-assinado)
Uma nota sobre o requisito #3 acima. Se você instalar o seu próprio provedor de identidades (ao invés de utilizar um provedor como Google ou Microsoft) você DEVE ter o certificado web do seu provedor de identidades assinado por um certificado contendo a opção CA configurada para TRUE, mesmo que seja um certificado auto assinado. Isso deve-se a implementação do cliente TLS em Golang que é bastante restrito quanto aos padrões em torno da validação de certificados. Se você não possui um CA em fácil alcance, você pode usar este script criado pelo time Dex para criar um simples CA, um par de chaves e certificado assinados.
Ou você pode usar este script similar o qual gera certificados SHA256 com uma vida mais longa e tamanho maior de chave.
Instruções de configuração para sistemas específicos podem ser encontrados em:
A primeira opção é utilizar-se do autenticador oidc do kubectl, o qual define o valor do id_token como um bearer token para todas as requisições e irá atualizar o token quando o mesmo expirar. Após você efetuar o login no seu provedor, utilize o kubectl para adicionar os seus id_token, refresh_token, client_id, e client_secret para configurar o plugin.
Provedores os quais não retornem um id_token como parte da sua resposta de refresh token não são suportados por este plugin e devem utilizar a opção 2 abaixo.
kubectl config set-credentials USER_NAME \
--auth-provider=oidc \
--auth-provider-arg=idp-issuer-url=( issuer url )\
--auth-provider-arg=client-id=( your client id )\
--auth-provider-arg=client-secret=( your client secret )\
--auth-provider-arg=refresh-token=( your refresh token )\
--auth-provider-arg=idp-certificate-authority=( path to your ca certificate )\
--auth-provider-arg=id-token=( your id_token )
Um exemplo, executando o comando abaixo após autenticar-se no seu provedor de identidades:
Uma vez que seu id_token expire, kubectl irá tentar atualizar o seu id_token utilizando-se do seu refresh_token e client_secret armazenando os novos valores para refresh_token e id_token no seu arquivo de configuração .kube/config.
Opção 2 - Utilize a opção --token
O comando kubectl o permite passar o valor de um token utilizando a opção --token. Copie e cole o valor do seu id_token nesta opção:
kubectl --token=eyJhbGciOiJSUzI1NiJ9.eyJpc3MiOiJodHRwczovL21sYi50cmVtb2xvLmxhbjo4MDQzL2F1dGgvaWRwL29pZGMiLCJhdWQiOiJrdWJlcm5ldGVzIiwiZXhwIjoxNDc0NTk2NjY5LCJqdGkiOiI2RDUzNXoxUEpFNjJOR3QxaWVyYm9RIiwiaWF0IjoxNDc0NTk2MzY5LCJuYmYiOjE0NzQ1OTYyNDksInN1YiI6Im13aW5kdSIsInVzZXJfcm9sZSI6WyJ1c2VycyIsIm5ldy1uYW1lc3BhY2Utdmlld2VyIl0sImVtYWlsIjoibXdpbmR1QG5vbW9yZWplZGkuY29tIn0.f2As579n9VNoaKzoF-dOQGmXkFKf1FMyNV0-va_B63jn-_n9LGSCca_6IVMP8pO-Zb4KvRqGyTP0r3HkHxYy5c81AnIh8ijarruczl-TK_yF5akjSTHFZD-0gRzlevBDiH8Q79NAr-ky0P4iIXS8lY9Vnjch5MF74Zx0c3alKJHJUnnpjIACByfF2SCaYzbWFMUNat-K1PaUk5-ujMBG7yYnr95xD-63n8CO8teGUAAEMx6zRjzfhnhbzX-ajwZLGwGUBT4WqjMs70-6a7_8gZmLZb2az1cZynkFRj2BaCkVT3A2RrjeEwZEtGXlMqKJ1_I2ulrOVsYx01_yD35-rw get nodes
Token de autenticação via Webhook
Webhook de autenticação é usado para verificar bearer tokens
--authentication-token-webhook-config-file arquivo de configuração descrevendo como acessar o serviço remoto de webhook.
--authentication-token-webhook-cache-ttl por quanto tempo guardar em cache decisões de autenticação. Configuração padrão definida para dois minutos.
--authentication-token-webhook-version determina quando usar o apiVersion authentication.k8s.io/v1beta1 ou authentication.k8s.io/v1 para objetos TokenReview quando enviar/receber informações do webhook. Valor padrão v1beta1.
O arquivo de configuração usa o formato de arquivo do kubeconfig. Dentro do arquivo, clusters refere-se ao serviço remoto e users refere-se ao servidor de API do webhook. Um exemplo seria:
# versão da API do KubernetesapiVersion:v1# tipo do objeto da APIkind:Config# clusters refere-se ao serviço remotoclusters:- name:name-of-remote-authn-servicecluster:certificate-authority:/path/to/ca.pem # CA para verificar o serviço remotoserver:https://authn.example.com/authenticate# URL para procurar o serviço remoto. Deve utilizar 'https'.# users refere-se a configuração do webhook do servidor de APIusers:- name:name-of-api-serveruser:client-certificate:/path/to/cert.pem# certificado para ser utilizado pelo plugin de webhookclient-key:/path/to/key.pem # chave referente ao certificado# arquivos kubeconfig requerem um contexto. Especifique um para o servidor de API.current-context:webhookcontexts:- context:cluster:name-of-remote-authn-serviceuser:name-of-api-servername:webhook
Quando um cliente tenta autenticar-se com o servidor de API utilizando um bearer token como discutido acima, o webhook de autenticação envia um objeto JSON serializado do tipo TokenReview contendo o valor do token para o serviço remoto.
Note que objetos de API do tipo webhook estão sujeitos às mesmas regras de compatibilidade de versão como outros objetos de API Kubernetes.
Implementadores devem verificar o campo de versão da API (apiVersion) da requisição para garantir a correta deserialização e devem responder com um objeto do tipo TokenReview da mesma versão da requisição.
O servidor de API Kubernetes envia por padrão revisão de tokens para a API authentication.k8s.io/v1beta1 para fins de compatibilidade com versões anteriores.
Para optar receber revisão de tokens de versão authentication.k8s.io/v1, o servidor de API deve ser inicializado com a opção --authentication-token-webhook-version=v1.
{"apiVersion": "authentication.k8s.io/v1","kind": "TokenReview","spec": {# Bearer token opaco enviado para o servidor de API"token": "014fbff9a07c...",# Lista opcional de identificadores de audiência para o servidor ao qual o token foi apresentado# Autenticadores de token sensíveis a audiência (por exemplo, autenticadores de token OIDC)# deve-se verificar que o token foi direcionado a pelo menos um membro da lista de audiência# e retornar a interseção desta lista a audiência válida para o token no estado da resposta# Isto garante com que o token é válido para autenticar-se no servidor ao qual foi apresentado# Se nenhuma audiência for especificada, o token deve ser validado para autenticar-se ao servidor de API do Kubernetes"audiences": ["https://myserver.example.com","https://myserver.internal.example.com"]}}
{"apiVersion": "authentication.k8s.io/v1beta1","kind": "TokenReview","spec": {# Bearer token opaco enviado para o servidor de API"token": "014fbff9a07c...",# Lista opcional de identificadores de audiência para o servidor ao qual o token foi apresentado# Autenticadores de token sensíveis a audiência (por exemplo, autenticadores de token OIDC)# deve-se verificar que o token foi direcionado a pelo menos um membro da lista de audiência# e retornar a interseção desta lista a audiência válida para o token no estado da resposta# Isto garante com que o token é válido para autenticar-se no servidor ao qual foi apresentado# Se nenhuma audiência for especificada, o token deve ser validado para autenticar-se ao servidor de API do Kubernetes"audiences": ["https://myserver.example.com","https://myserver.internal.example.com"]}}
É esperado que o serviço remoto preencha o campo status da requisição para indicar o sucesso do login.
O campo spec do corpo de resposta é ignorado e pode ser omitido.
O serviço remoto deverá retornar uma resposta usando a mesma versão de API do objeto TokenReview que foi recebido.
Uma validação bem sucedida deveria retornar:
{"apiVersion": "authentication.k8s.io/v1","kind": "TokenReview","status": {"authenticated": true,"user": {# Obrigatório"username": "janedoe@example.com",# Opcional"uid": "42",# Opcional: lista de grupos associados"groups": ["developers","qa"],# Opcional: informação adicional provida pelo autenticador.# Isto não deve conter dados confidenciais, pois pode ser registrados em logs ou em objetos de API e estarão disponíveis para webhooks de admissão"extra": {"extrafield1": ["extravalue1","extravalue2"]}},# Lista opcional de Autenticadores de token sensíveis a audiência que podem ser retornados,# contendo as audiências da lista `spec.audiences` válido para o token apresentado.# Se este campo for omitido, o token é considerado válido para autenticar-se no servidor de API Kubernetes"audiences": ["https://myserver.example.com"]}}
{"apiVersion": "authentication.k8s.io/v1beta1","kind": "TokenReview","status": {"authenticated": true,"user": {# Obrigatório"username": "janedoe@example.com",# Opcional"uid": "42",# Opcional: lista de grupos associados"groups": ["developers","qa"],# Opcional: informação adicional provida pelo autenticador.# Isto não deve conter dados confidenciais, pois pode ser registrados em logs ou em objetos de API e estarão disponíveis para webhooks de admissão"extra": {"extrafield1": ["extravalue1","extravalue2"]}},# Lista opcional de Autenticadores de token sensíveis a audiência que podem ser retornados,# contendo as audiências da lista `spec.audiences` válido para o token apresentado.# Se este campo for omitido, o token é considerado válido para autenticar-se no servidor de API Kubernetes"audiences": ["https://myserver.example.com"]}}
{"apiVersion": "authentication.k8s.io/v1","kind": "TokenReview","status": {"authenticated": false,# Opcionalmente inclui detalhes sobre o porque a autenticação falhou# Se nenhum erro é fornecido, a API irá retornar uma mensagem genérica de "Não autorizado"# O campo de erro é ignorado quando authenticated=true."error": "Credenciais expiradas"}}
{"apiVersion": "authentication.k8s.io/v1beta1","kind": "TokenReview","status": {"authenticated": false,# Opcionalmente inclui detalhes sobre o porque a autenticação falhou# Se nenhum erro é fornecido, a API irá retornar uma mensagem genérica de "Não autorizado"# O campo de erro é ignorado quando authenticated=true."error": "Credenciais expiradas"}}
Autenticando com Proxy
O servidor de API pode ser configurado para identificar usuários através de valores de cabeçalho de requisição, como por exemplo X-Remote-User.
Isto é projetado para o uso em combinação com um proxy de autenticação, o qual irá atribuir o valor do cabeçalho da requisição.
--requestheader-username-headers Obrigatório, não faz distinção entre caracteres maiúsculos/minúsculos. Nomes de cabeçalhos a serem verificados, em ordem, para a identidade do usuário. O primeiro cabeçalho contendo um valor será usado para o nome do usuário.
--requestheader-group-headers 1.6+. Opcional, não faz distinção entre caracteres maiúsculos/minúsculos. "X-Remote-Group" é recomendado. Nomes de cabeçalhos a serem verificados, em ordem, para os grupos do usuário. Todos os valores especificados em todos os cabeçalhos serão utilizados como nome dos grupos do usuário.
--requestheader-extra-headers-prefix 1.6+. Opcional, não faz distinção entre caracteres maiúsculos/minúsculos. "X-Remote-Extra-" é recomendado. Prefixos de cabeçalhos para serem utilizados para definir informações extras sobre o usuário (normalmente utilizado por um plugin de autorização). Todos os cabeçalhos que começam com qualquer um dos prefixos especificados têm o prefixo removido. O restante do nome do cabeçalho é transformado em letra minúscula, decodificado percent-decoded e torna-se uma chave extra, e o valor do cabeçalho torna-se um valor extra.
Nota: Antes da versão 1.11.3 (e 1.10.7, 1.9.11), a chave extra só poderia conter caracteres os quais fossem legais em rótulos de cabeçalhos HTTP.
Para prevenir falsificação de cabeçalhos, o proxy de autenticação deverá apresentar um certificado de cliente válido para o servidor de API para que possa ser validado com a autoridade de certificados (CA) antes que os cabeçalhos de requisições sejam verificados. AVISO: não re-utilize uma autoridade de certificados (CA) que esteja sendo utilizado em um contexto diferente ao menos que você entenda os riscos e os mecanismos de proteção da utilização de uma autoridade de certificados.
--requestheader-client-ca-file Obrigatório. Pacote de certificados no formato PEM. Um certificado válido deve ser apresentado e validado com a autoridade de certificados no arquivo especificado antes da verificação de cabeçalhos de requisição para os nomes do usuário.
--requestheader-allowed-names Opcional. Lista de valores de nomes comuns (CNs). Se especificado, um certificado de cliente válido contendo uma lista de nomes comuns denominados deve ser apresentado na verificação de cabeçalhos de requisição para os nomes do usuário. Se vazio, qualquer valor de nomes comuns será permitido.
Requisições anônimas
Quando habilitado, requisições que não são rejeitadas por outros métodos de autenticação configurados são tratadas como requisições anônimas e são dadas o nome de usuário system:anonymous e filiação ao grupo system:unauthenticated.
Por exemplo, uma requisição especificando um bearer token invalido chega a um servidor com token de autenticação configurado e acesso anônimo habilitado e receberia um erro de acesso não autorizado 401 Unauthorized. Já uma requisição não especificando nenhum bearer token seria tratada como uma requisição anônima.
Nas versões 1.5.1-1.5.x, acesso anônimo é desabilitado por padrão e pode ser habilitado passando a opção --anonymous-auth=true durante a inicialização do servidor de API.
Na versão 1.6 e acima, acesso anônimo é habilitado por padrão se um modo de autorização diferente de AlwaysAllow é utilizado e pode ser desabilitado passando a opção --anonymous-auth=false durante a inicialização do servidor de API.
Começando na versão 1.6, os autorizadores ABAC (Controle de Acesso Baseado em Atributos) e RBAC (Controle de Acesso Baseado em Função) requerem autorização explícita do usuário system:anonymous e do grupo system:unauthenticated, portanto, regras de políticas legadas que permitam acesso a usuário * e grupo * nao incluíram usuários anônimos.
Personificação de usuário
Um usuário pode agir como outro através de cabeçalhos de personificação. Os mesmos permitem que requisições manualmente sobrescrevam as informações ao quais o usuário irá se autenticar como. Por exemplo, um administrador pode utilizar-se desta funcionalidade para investigar um problema com uma política de autorização e assim, temporariamente, personificar um outro usuário e ver se/como sua requisição está sendo negada.
Requisições de personificação primeiramente são autenticadas como o usuário requerente, então trocando para os detalhes de informação do usuário personificado.
O fluxo é:
Um usuário faz uma chamada de API com suas credenciais e cabeçalhos de personificação.
O servidor de API autentica o usuário.
O servidor de API garante que o usuário autenticado possui permissão de personificação.
Detalhes de informação do usuário da requisição tem seus valores substituídos com os detalhes de personificação.
A requisição é avaliada e a autorização é feita sobre os detalhes do usuário personificado.
Os seguintes cabeçalhos HTTP podem ser usados para realizar uma requisição de personificação:
Impersonate-User: O nome do usuário para se executar ações em seu nome.
Impersonate-Group: Um nome de grupo para se executar ações em seu nome. Pode ser especificado múltiplas vezes para fornecer múltiplos grupos. Opcional. Requer "Impersonate-User".
Impersonate-Extra-( extra name ): Um cabeçalho dinâmico usado para associar campos extras do usuário. Opcional. Requer "Impersonate-User". Para que seja preservado consistentemente, ( extra name ) deve ser somente minúsculo, e qualquer caracter que não seja legal em rótulos de cabeçalhos HTTP DEVE ser utf8 e codificado.
Quando utilizando-se o kubectl especifique a opção --as para determinar o cabeçalho Impersonate-User, especifique a opção --as-group para determinar o cabeçalho Impersonate-Group.
kubectl drain mynode
Error from server (Forbidden): User "clark" cannot get nodes at the cluster scope. (get nodes mynode)
Para personificar um usuário, grupo ou especificar campos extras, o usuário efetuando a personificação deve possuir a permissão de executar o verbo "impersonate" no tipo de atributo sendo personificado ("user", "group", etc.). Para clusters com o plugin de autorização RBAC habilitados, a seguinte ClusterRole abrange as regras necessárias para definir os cabeçalhos de personificação de usuário e grupo:
Campos extras são avaliados como sub-recursos de um recurso denominado "userextras". Para permitir ao usuário que utilize os cabeçalhos de personificação para o campo extra "scopes", o usuário deve receber a seguinte permissão:
apiVersion:rbac.authorization.k8s.io/v1kind:ClusterRolemetadata:name:scopes-impersonatorrules:# Pode definir o cabeçalho "Impersonate-Extra-scopes".- apiGroups:["authentication.k8s.io"]resources:["userextras/scopes"]verbs:["impersonate"]
Os valores dos cabeçalhos de personificação podem também ser restringidos ao limitar o conjunto de nomes de recursos (resourceNames) que um recurso pode ter.
apiVersion:rbac.authorization.k8s.io/v1kind:ClusterRolemetadata:name:limited-impersonatorrules:# Pode personificar o usuário "jane.doe@example.com"- apiGroups:[""]resources:["users"]verbs:["impersonate"]resourceNames:["jane.doe@example.com"]# Pode assumir os grupos "developers" and "admins"- apiGroups:[""]resources:["groups"]verbs:["impersonate"]resourceNames:["developers","admins"]# Pode personificar os campos extras "scopes" com valores "view" e "development"- apiGroups:["authentication.k8s.io"]resources:["userextras/scopes"]verbs:["impersonate"]resourceNames:["view","development"]
Plugins de credenciais client-go
FEATURE STATE:Kubernetes v1.11 [beta]
Ferramentas como kubectl e kubelet utilizando-se do k8s.io/client-go são capazes de executar um comando externo para receber credenciais de usuário.
Esta funcionalidade é direcionada à integração do lado cliente, com protocolos de autenticação não suportados nativamente pelo k8s.io/client-go como: LDAP, Kerberos, OAuth2, SAML, etc. O plugin implementa a lógica específica do protocolo e então retorna credenciais opacas para serem utilizadas. Quase todos os casos de usos de plugins de credenciais requerem um componente de lado do servidor com suporte para um autenticador de token webhook para interpretar o formato das credenciais produzidas pelo plugin cliente.
Exemplo de caso de uso
Num caso de uso hipotético, uma organização executaria um serviço externo que efetuaria a troca de credenciais LDAP por tokens assinados para um usuário específico. Este serviço seria também capaz de responder requisições do autenticador de token webhook para validar tokens. Usuários seriam obrigados a instalar um plugin de credencial em sua estação de trabalho.
Para autenticar na API:
O usuário entra um comando kubectl.
O plugin de credencial solicita ao usuário a entrada de credenciais LDAP e efetua troca das credenciais por um token via um serviço externo.
O plugin de credenciais retorna um token para o client-go, o qual o utiliza como um bearer token no servidor de API.
apiVersion:v1kind:Configusers:- name:my-useruser:exec:# Comando a ser executado. Obrigatório.command:"example-client-go-exec-plugin"# Versão da API a ser utilizada quando decodificar o recurso ExecCredentials. Obrigatório## A versão da API retornada pelo plugin DEVE ser a mesma versão listada aqui.## Para integrar com ferramentas que suportem múltiplas versões (tal como client.authentication.k8s.io/v1alpha1),# defina uma variável de ambiente ou passe um argumento para a ferramenta que indique qual versão o plugin de execução deve esperar.apiVersion:"client.authentication.k8s.io/v1beta1"# Variáveis de ambiente a serem configuradas ao executar o plugin. Opcionalenv:- name:"FOO"value:"bar"# Argumentos a serem passados ao executar o plugin. Opcionalargs:- "arg1"- "arg2"# Texto exibido para o usuário quando o executável não parece estar presente. OpcionalinstallHint:|example-client-go-exec-plugin é necessário para autenticar no cluster atual. Pode ser instalado via:Em macOS:brew install example-client-go-exec-pluginEm Ubuntu:apt-get install example-client-go-exec-pluginEm Fedora:dnf install example-client-go-exec-plugin...# Deve-se ou não fornecer informações do cluster, que podem potencialmente conter grande quantidade de dados do CA,# para esse plugin de execução como parte da variável de ambiente KUBERNETES_EXEC_INFOprovideClusterInfo:trueclusters:- name:my-clustercluster:server:"https://172.17.4.100:6443"certificate-authority:"/etc/kubernetes/ca.pem"extensions:- name:client.authentication.k8s.io/exec# nome de extensão reservado para configuração exclusiva do clusterextension:arbitrary:configthis:pode ser fornecido através da variável de ambiente KUBERNETES_EXEC_INFO na configuracao de provideClusterInfoyou:["coloque","qualquer","coisa","aqui"]contexts:- name:my-clustercontext:cluster:my-clusteruser:my-usercurrent-context:my-cluster
Os caminhos relativos do comando são interpretados como relativo ao diretório do arquivo de configuração. Se
KUBECONFIG está configurado para o caminho /home/jane/kubeconfig e o comando executado é ./bin/example-client-go-exec-plugin,
o binario /home/jane/bin/example-client-go-exec-plugin será executado.
- name:my-useruser:exec:# Caminho relativo para o diretorio do kubeconfigcommand:"./bin/example-client-go-exec-plugin"apiVersion:"client.authentication.k8s.io/v1beta1"
Formatos de entrada e saída
O comando executado imprime um objeto ExecCredential para o stdout. k8s.io/client-go
autentica na API do Kubernetes utilizando as credenciais retornadas no status.
Quando executando uma sessão interativa, stdin é exposto diretamente para o plugin. plugins devem utilizar
um TTY check para determinar se é
apropriado solicitar um usuário interativamente.
Para usar credenciais do tipo bearer token, o plugin retorna um token no status do objeto ExecCredential.
Alternativamente, um certificado de cliente e chave codificados em PEM podem ser retornados para serem utilizados em autenticação de cliente TLS.
Se o plugin retornar um certificado e chave diferentes numa chamada subsequente, k8s.io/client-go
Irá fechar conexões existentes com o servidor para forçar uma nova troca TLS.
Se especificado, clientKeyData e clientCertificateData devem ambos estar presentes.
clientCertificateData pode conter certificados intermediários adicionais a serem enviados para o servidor.
Opcionalmente, a resposta pode incluir a validade da credencial em formato
RFC3339 de data/hora. A presença ou ausência de validade pode ter o seguinte impacto:
Se uma validade está incluída, o bearer token e as credenciais TLS são guardadas em cache até
a o tempo de expiração é atingido ou se o servidor responder com um codigo de status HTTP 401
ou se o processo terminar.
Se uma validate está ausente, o bearer token e as credenciais TLS são guardadas em cache até
o servidor responder com um código de status HTTP 401 ou até o processo terminar.
Para habilitar o plugin de execução para obter informações específicas do cluster, define provideClusterInfo no campo user.exec
dentro do arquivo de configuração kubeconfig.
O plugin irá então prover a variável de ambiente KUBERNETES_EXEC_INFO.
As informações desta variável de ambiente podem ser utilizadas para executar lógicas de aquisição
de credentiais específicas do cluster.
O manifesto ExecCredential abaixo descreve um exemplo de informação de cluster.
{
"apiVersion": "client.authentication.k8s.io/v1beta1",
"kind": "ExecCredential",
"spec": {
"cluster": {
"server": "https://172.17.4.100:6443",
"certificate-authority-data": "LS0t...",
"config": {
"arbitrary": "config",
"this": "pode ser fornecido por meio da variável de ambiente KUBERNETES_EXEC_INFO na configuração de provideClusterInfo",
"you": ["coloque", "qualquer", "coisa", "aqui"]
}
}
}
}
6.3 - Autenticando com Tokens de Inicialização
FEATURE STATE:Kubernetes v1.18 [stable]
Os tokens de inicialização são um bearer token simples que devem ser utilizados
ao criar novos clusters ou para quando novos nós são registrados a clusters existentes. Eles foram construídos
para suportar a ferramenta kubeadm, mas podem ser utilizados em outros contextos para usuários que desejam inicializar clusters sem utilizar o kubeadm.
Foram também construídos para funcionar, via políticas RBAC, com o sistema de Inicialização do Kubelet via TLS.
Visão geral dos tokens de inicialização
Os tokens de inicialização são definidos com um tipo especifico de secrets (bootstrap.kubernetes.io/token) que existem no namespace kube-system. Estes secrets são então lidos pelo autenticador de inicialização do servidor de API.
Tokens expirados são removidos pelo controlador TokenCleaner no gerenciador de controle - kube-controller-manager.
Os tokens também são utilizados para criar uma assinatura para um ConfigMap específico usado no processo de descoberta através de um controlador denominado BootstrapSigner.
Formato do Token
Tokens de inicialização tem o formato abcdef.0123456789abcdef. Mais formalmente, eles devem corresponder a expressão regular [a-z0-9]{6}\.[a-z0-9]{16}.
A primeira parte do token é um identificador ("Token ID") e é considerado informação pública.
Ele é utilizado para se referir a um token sem vazar a parte secreta usada para autenticação.
A segunda parte é o secret do token e somente deve ser compartilhado com partes confiáveis.
Habilitando autenticação com tokens de inicialização
O autenticador de tokens de inicialização pode ser habilitado utilizando a seguinte opção no servidor de API:
--enable-bootstrap-token-auth
Quando habilitado, tokens de inicialização podem ser utilizado como credenciais bearer token
para autenticar requisições no servidor de API.
Authorization: Bearer 07401b.f395accd246ae52d
Tokens são autenticados como o usuário system:bootstrap:<token id> e são membros
do grupo system:bootstrappers. Grupos adicionais podem ser
especificados dentro do secret do token.
Tokens expirados podem ser removidos automaticamente ao habilitar o controlador tokencleaner
do gerenciador de controle - kube-controller-manager.
--controllers=*,tokencleaner
Formato do secret dos tokens de inicialização
Cada token válido possui um secret no namespace kube-system. Você pode
encontrar a documentação completa aqui.
Um secret de token se parece com o exemplo abaixo:
apiVersion:v1kind:Secretmetadata:# Nome DEVE seguir o formato "bootstrap-token-<token id>"name:bootstrap-token-07401bnamespace:kube-system# Tipo DEVE ser 'bootstrap.kubernetes.io/token'type:bootstrap.kubernetes.io/tokenstringData:# Descrição legível. Opcional.description:"The default bootstrap token generated by 'kubeadm init'."# identificador do token e _secret_. Obrigatório.token-id:07401btoken-secret:f395accd246ae52d# Validade. Opcional.expiration:2017-03-10T03:22:11Z# Usos permitidos.usage-bootstrap-authentication:"true"usage-bootstrap-signing:"true"# Grupos adicionais para autenticar o token. Devem começar com "system:bootstrappers:"auth-extra-groups:system:bootstrappers:worker,system:bootstrappers:ingress
O tipo do secret deve ser bootstrap.kubernetes.io/token e o nome deve seguir o formato bootstrap-token-<token id>. Ele também tem que existir no namespace kube-system.
Os membros listados em usage-bootstrap-* indicam qual a intenção de uso deste secret. O valor true deve ser definido para que seja ativado.
usage-bootstrap-authentication indica que o token pode ser utilizado para autenticar no servidor de API como um bearer token.
usage-bootstrap-signing indica que o token pode ser utilizado para assinar o ConfigMap cluster-info como descrito abaixo.
O campo expiration controla a expiração do token. Tokens expirados são
rejeitados quando usados para autenticação e ignorados durante assinatura de ConfigMaps.
O valor de expiração é codificado como um tempo absoluto UTC utilizando a RFC3339. Para automaticamente
remover tokens expirados basta habilitar o controlador tokencleaner.
Gerenciamento de tokens com kubeadm
Você pode usar a ferramenta kubeadm para gerenciar tokens em um cluster. Veja documentação de tokens kubeadm para mais detalhes.
Assinatura de ConfigMap
Além de autenticação, os tokens podem ser utilizados para assinar um ConfigMap. Isto pode
ser utilizado em estágio inicial do processo de inicialização de um cluster, antes que o cliente confie
no servidor de API. O Configmap assinado pode ser autenticado por um token compartilhado.
Habilite a assinatura de ConfigMap ao habilitar o controlador bootstrapsigner no gerenciador de controle - kube-controller-manager.
--controllers=*,bootstrapsigner
O ConfigMap assinado é o cluster-info no namespace kube-public.
No fluxo típico, um cliente lê o ConfigMap enquanto ainda não autenticado
e ignora os erros da camada de transporte seguro (TLS).
Ele então valida o conteúdo do ConfigMap ao verificar a assinatura contida no ConfigMap.
O membro kubeconfig do ConfigMap é um arquivo de configuração contendo somente
as informações do cluster preenchidas. A informação chave sendo comunicada aqui
está em certificate-authority-data. Isto poderá ser expandido no futuro.
A assinatura é feita utilizando-se assinatura JWS em modo "separado". Para validar
a assinatura, o usuário deve codificar o conteúdo do kubeconfig de acordo com as regras do JWS
(codificando em base64 e descartando qualquer = ao final). O conteúdo codificado
e então usado para formar um JWS inteiro, inserindo-o entre os 2 pontos. Você pode
verificar o JWS utilizando o esquema HS256 (HMAC-SHA256) com o token completo
(por exemplo: 07401b.f395accd246ae52d) como o secret compartilhado. Usuários devem
verificar que o algoritmo HS256 (que é um método de assinatura simétrica) está sendo utilizado.
Aviso: Qualquer parte em posse de um token de inicialização pode criar uma assinatura válida
daquele token. Não é recomendável, quando utilizando assinatura de ConfigMap, que se compartilhe
o mesmo token com muitos clientes, uma vez que um cliente comprometido pode abrir brecha para potenciais
"homem no meio" entre outro cliente que confia na assinatura para estabelecer inicialização via camada de transporte seguro (TLS).
Quando o Kubernetes está sendo executado em um ambiente com uma rede mais restritiva,
como por exemplo um data center on-premises com firewalls de rede físicos ou redes virtuais em nuvens públicas,
é útil saber quais portas e protocolos são utilizados pelos componentes do Kubernetes.
Camada de gerenciamento
Protocolo
Direção
Intervalo de Portas
Propósito
Utilizado por
TCP
Entrada
6443
Servidor da API do Kubernetes
Todos
TCP
Entrada
2379-2380
API servidor-cliente do etcd
kube-apiserver, etcd
TCP
Entrada
10250
API do kubelet
kubeadm, Camada de gerenciamento
TCP
Entrada
10259
kube-scheduler
kubeadm
TCP
Entrada
10257
kube-controller-manager
kubeadm
Embora as portas do etcd estejam inclusas na seção da Camada de gerenciamento, você também
pode hospedar o seu próprio cluster etcd externamente ou em portas customizadas.
Todas as portas padrão podem ser sobrescritas. Quando portas customizadas são utilizadas, essas portas
precisam estar abertas, ao invés das mencionadas aqui.
Um exemplo comum é a porta do servidor da API, que as vezes é trocado para a porta 433.
Com isso, a porta padrão é mantida e o servidor da API é colocado atrás de um balanceador de carga
que escuta na porta 433 e faz o roteamento das requisições para o servidor da API na porta padrão.
source <(kubectl completion bash)# configuração de autocomplete no bash do shell atual, o pacote bash-completion precisa ter sido instalado primeiro.echo"source <(kubectl completion bash)" >> ~/.bashrc # para adicionar o autocomplete permanentemente no seu shell bash.
Você também pode usar uma abreviação para o atalho para kubectl que também funciona com o auto completar:
aliask=kubectl
complete -F __start_kubectl k
ZSH
source <(kubectl completion zsh)# configuração para usar autocomplete no terminal zsh no shell atualecho"if [ $commands[kubectl] ]; then source <(kubectl completion zsh); fi" >> ~/.zshrc # adicionar auto completar permanentemente para o seu shell zsh
Contexto e Configuração do Kubectl
Defina com qual cluster Kubernetes o kubectl se comunica e modifique os detalhes da configuração.
Veja a documentação Autenticando entre clusters com o kubeconfig para
informações detalhadas do arquivo de configuração.
kubectl config view # Mostrar configurações do kubeconfig mergeadas.# use vários arquivos kubeconfig ao mesmo tempo e visualize a configuração mergeadaKUBECONFIG=~/.kube/config:~/.kube/kubconfig2
kubectl config view
# obtenha a senha para o usuário e2e
kubectl config view -o jsonpath='{.users[?(@.name == "e2e")].user.password}'
kubectl config view -o jsonpath='{.users[].name}'# exibir o primeiro usuário
kubectl config view -o jsonpath='{.users[*].name}'# obtenha uma lista de usuários
kubectl config get-contexts # exibir lista de contextos
kubectl config current-context # exibir o contexto atual
kubectl config use-context my-cluster-name # defina o contexto padrão como my-cluster-name# adicione um novo cluster ao seu kubeconfig que suporte autenticação básica
kubectl config set-credentials kubeuser/foo.kubernetes.com --username=kubeuser --password=kubepassword
# salve o namespace permanentemente para todos os comandos subsequentes do kubectl nesse contexto.
kubectl config set-context --current --namespace=ggckad-s2
# defina um contexto utilizando um nome de usuário e o namespace.
kubectl config set-context gce --user=cluster-admin --namespace=foo \
&& kubectl config use-context gce
kubectl config unset users.foo # excluir usuário foo
Aplicar
apply gerencia aplicações através de arquivos que definem os recursos do Kubernetes. Ele cria e atualiza recursos em um cluster através da execução kubectl apply.
Esta é a maneira recomendada de gerenciar aplicações Kubernetes em ambiente de produção. Veja a documentação do Kubectl.
Criando objetos
Manifestos Kubernetes podem ser definidos em YAML ou JSON. A extensão de arquivo .yaml,
.yml, e .json pode ser usado.
kubectl apply -f ./my-manifest.yaml # criar recurso(s)
kubectl apply -f ./my1.yaml -f ./my2.yaml # criar a partir de vários arquivos
kubectl apply -f ./dir # criar recurso(s) em todos os arquivos de manifesto no diretório
kubectl apply -f https://git.io/vPieo # criar recurso(s) a partir de URL
kubectl create deployment nginx --image=nginx # iniciar uma única instância do nginx
kubectl explain pods,svc # obtenha a documentação de manifesto do pod# Crie vários objetos YAML a partir de stdin
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: busybox-sleep
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000000"
---
apiVersion: v1
kind: Pod
metadata:
name: busybox-sleep-less
spec:
containers:
- name: busybox
image: busybox
args:
- sleep
- "1000"
EOF# Crie um segredo com várias chaves
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
password: $(echo -n "s33msi4" | base64 -w0)
username: $(echo -n "jane" | base64 -w0)
EOF
Visualizando e Localizando Recursos
# Obter comandos com saída simples
kubectl get services # Listar todos os serviços do namespace
kubectl get pods --all-namespaces # Listar todos os pods em todos namespaces
kubectl get pods -o wide # Listar todos os pods no namespace atual, com mais detalhes
kubectl get deployment my-dep # Listar um deployment específico
kubectl get pods # Listar todos os pods no namespace
kubectl get pod my-pod -o yaml # Obter o YAML de um pod# Descrever comandos com saída detalhada
kubectl describe nodes my-node
kubectl describe pods my-pod
# Listar serviços classificados por nome
kubectl get services --sort-by=.metadata.name
# Listar pods classificados por contagem de reinicializações
kubectl get pods --sort-by='.status.containerStatuses[0].restartCount'# Listar PersistentVolumes classificado por capacidade
kubectl get pv --sort-by=.spec.capacity.storage
# Obtenha a versão da label de todos os pods com a label app=cassandra
kubectl get pods --selector=app=cassandra -o \
jsonpath='{.items[*].metadata.labels.version}'# Obter todos os nós workers (use um seletor para excluir resultados que possuem uma label# nomeado 'node-role.kubernetes.io/master')
kubectl get node --selector='!node-role.kubernetes.io/master'# Obter todos os pods em execução no namespace
kubectl get pods --field-selector=status.phase=Running
# Obter ExternalIPs de todos os nós
kubectl get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="ExternalIP")].address}'# Listar nomes de pods pertencentes a um RC particular # O comando "jq" é útil para transformações que são muito complexas para jsonpath, pode ser encontrado em https://stedolan.github.io/jq/sel=${$(kubectl get rc my-rc --output=json | jq -j '.spec.selector | to_entries | .[] | "\(.key)=\(.value),"')%?}echo$(kubectl get pods --selector=$sel --output=jsonpath={.items..metadata.name})# Mostrar marcadores para todos os pods(ou qualquer outro objeto Kubernetes que suporte rotulagem)
kubectl get pods --show-labels
# Verifique quais nós estão prontosJSONPATH='{range .items[*]}{@.metadata.name}:{range @.status.conditions[*]}{@.type}={@.status};{end}{end}'\
&& kubectl get nodes -o jsonpath="$JSONPATH" | grep "Ready=True"# Listar todos os segredos atualmente em uso por um pod
kubectl get pods -o json | jq '.items[].spec.containers[].env[]?.valueFrom.secretKeyRef.name' | grep -v null | sort | uniq
# Listar todos os containerIDs de initContainer de todos os pods# Útil ao limpar contêineres parados, evitando a remoção de initContainers.
kubectl get pods --all-namespaces -o jsonpath='{range .items[*].status.initContainerStatuses[*]}{.containerID}{"\n"}{end}' | cut -d/ -f3
# Listar eventos classificados por timestamp
kubectl get events --sort-by=.metadata.creationTimestamp
# Compara o estado atual do cluster com o estado em que o cluster estaria se o manifesto fosse aplicado.
kubectl diff -f ./my-manifest.yaml
Atualizando Recursos
A partir da versão 1.11 rolling-update foi descontinuado (veja CHANGELOG-1.11.md), utilize o comando rollout no lugar deste.
kubectl set image deployment/frontend www=image:v2 # Aplica o rollout nos containers "www" do deployment "frontend", atualizando a imagem
kubectl rollout history deployment/frontend # Verifica o histórico do deployment, incluindo a revisão
kubectl rollout undo deployment/frontend # Rollback para o deployment anterior
kubectl rollout undo deployment/frontend --to-revision=2# Rollback para uma revisão específica
kubectl rollout status -w deployment/frontend # Acompanhe o status de atualização do "frontend" até sua conclusão sem interrupção
kubectl rollout restart deployment/frontend # Reinício contínuo do deployment "frontend"# versão inicial descontinuada 1.11
kubectl rolling-update frontend-v1 -f frontend-v2.json # (descontinuada) Atualização contínua dos pods de frontend-v1
kubectl rolling-update frontend-v1 frontend-v2 --image=image:v2 # (descontinuada) Altera o nome do recurso e atualiza a imagem
kubectl rolling-update frontend --image=image:v2 # (descontinuada) Atualize a imagem dos pods do frontend
kubectl rolling-update frontend-v1 frontend-v2 --rollback # (descontinuada) Interromper o lançamento existente em andamento
cat pod.json | kubectl replace -f - # Substitua um pod com base no JSON passado para std# Força a substituição, exclui e recria o recurso. Causará uma interrupção do serviço.
kubectl replace --force -f ./pod.json
# Crie um serviço para um nginx replicado, que serve na porta 80 e se conecta aos contêineres na porta 8000
kubectl expose rc nginx --port=80 --target-port=8000# Atualizar a versão da imagem (tag) de um pod de contêiner único para a v4
kubectl get pod mypod -o yaml | sed 's/\(image: myimage\):.*$/\1:v4/' | kubectl replace -f -
kubectl label pods my-pod new-label=awesome # Adicionar uma label
kubectl annotate pods my-pod icon-url=http://goo.gl/XXBTWq # Adicionar uma anotação
kubectl autoscale deployment foo --min=2 --max=10# Escalar automaticamente um deployment "foo"
Recursos de Correção
# Atualizar parcialmente um nó
kubectl patch node k8s-node-1 -p '{"spec":{"unschedulable":true}}'# Atualizar a imagem de um contêiner; spec.containers[*].name é obrigatório porque é uma chave de mesclagem
kubectl patch pod valid-pod -p '{"spec":{"containers":[{"name":"kubernetes-serve-hostname","image":"new image"}]}}'# Atualizar a imagem de um contêiner usando um patch json com matrizes posicionais
kubectl patch pod valid-pod --type='json' -p='[{"op": "replace", "path": "/spec/containers/0/image", "value":"new image"}]'# Desative um livenessProbe de deployment usando um patch json com matrizes posicionais
kubectl patch deployment valid-deployment --type json -p='[{"op": "remove", "path": "/spec/template/spec/containers/0/livenessProbe"}]'# Adicionar um novo elemento a uma matriz posicional
kubectl patch sa default --type='json' -p='[{"op": "add", "path": "/secrets/1", "value": {"name": "whatever" } }]'
Editando Recursos
Edite qualquer recurso da API no seu editor preferido.
kubectl edit svc/docker-registry # Edite o serviço chamado docker-registryKUBE_EDITOR="nano" kubectl edit svc/docker-registry # Use um editor alternativo
Escalando Recursos
kubectl scale --replicas=3 rs/foo # Escale um replicaset chamado 'foo' para 3
kubectl scale --replicas=3 -f foo.yaml # Escale um recurso especificado em "foo.yaml" para 3
kubectl scale --current-replicas=2 --replicas=3 deployment/mysql # Se o tamanho atual do deployment chamado mysql for dois, assim escale para 3
kubectl scale --replicas=5 rc/foo rc/bar rc/baz # Escalar vários replicaset
Exclusão de Recursos
kubectl delete -f ./pod.json # Exclua um pod usando o tipo e o nome especificados em pod.json
kubectl delete pod,service baz foo # Excluir pods e serviços com os mesmos nomes "baz" e "foo"
kubectl delete pods,services -l name=myLabel # Excluir pods e serviços com o nome da label = myLabel
kubectl -n my-ns delete pod,svc --all # Exclua todos os pods e serviços no namespace my-ns,# Excluir todos os pods que correspondem ao awk pattern1 ou pattern2
kubectl get pods -n mynamespace --no-headers=true | awk '/pattern1|pattern2/{print $1}' | xargs kubectl delete -n mynamespace pod
Interagindo com Pods em execução
kubectl logs my-pod # despejar logs de pod (stdout)
kubectl logs -l name=myLabel # despejar logs de pod, com a label de name=myLabel (stdout)
kubectl logs my-pod --previous # despejar logs de pod (stdout) para a instância anterior de um contêiner
kubectl logs my-pod -c my-container # despejar logs de um específico contêiner em um pod (stdout, no caso de vários contêineres)
kubectl logs -l name=myLabel -c my-container # despejar logs de pod, com nome da label = myLabel (stdout)
kubectl logs my-pod -c my-container --previous # despejar logs de um contêiner específico em um pod (stdout, no caso de vários contêineres) para uma instanciação anterior de um contêiner
kubectl logs -f my-pod # Fluxo de logs de pod (stdout)
kubectl logs -f my-pod -c my-container # Fluxo de logs para um específico contêiner em um pod (stdout, caixa com vários contêineres)
kubectl logs -f -l name=myLabel --all-containers # transmitir todos os logs de pods com a label name=myLabel (stdout)
kubectl run -i --tty busybox --image=busybox -- sh # Executar pod como shell interativo
kubectl run nginx --image=nginx --restart=Never -n
mynamespace # Execute o pod nginx em um namespace específico
kubectl run nginx --image=nginx --restart=Never # Execute o pod nginx e salve suas especificações em um arquivo chamado pod.yaml
--dry-run -o yaml > pod.yaml
kubectl attach my-pod -i # Anexar ao contêiner em execução
kubectl port-forward my-pod 5000:6000 # Ouça na porta 5000 na máquina local e encaminhe para a porta 6000 no my-pod
kubectl exec my-pod -- ls / # Executar comando no pod existente (1 contêiner)
kubectl exec my-pod -c my-container -- ls / # Executar comando no pod existente (pod com vários contêineres)
kubectl top pod POD_NAME --containers # Mostrar métricas para um determinado pod e seus contêineres
Interagindo com Nós e Cluster
kubectl cordon my-node # Marcar o nó my-node como não agendável
kubectl drain my-node # Drene o nó my-node na preparação para manutenção
kubectl uncordon my-node # Marcar nó my-node como agendável
kubectl top node my-node # Mostrar métricas para um determinado nó
kubectl cluster-info # Exibir endereços da master e serviços
kubectl cluster-info dump # Despejar o estado atual do cluster no stdout
kubectl cluster-info dump --output-directory=/path/to/cluster-state # Despejar o estado atual do cluster em /path/to/cluster-state# Se uma `taint` com essa chave e efeito já existir, seu valor será substituído conforme especificado.
kubectl taint nodes foo dedicated=special-user:NoSchedule
Tipos de Recursos
Listar todos os tipos de recursos suportados, juntamente com seus nomes abreviados, Grupo de API, se eles são por namespaces, e objetos:
kubectl api-resources
Outras operações para explorar os recursos da API:
kubectl api-resources --namespaced=true# Todos os recursos com namespace
kubectl api-resources --namespaced=false# Todos os recursos sem namespace
kubectl api-resources -o name # Todos os recursos com saída simples (apenas o nome do recurso)
kubectl api-resources -o wide # Todos os recursos com saída expandida (também conhecida como "ampla")
kubectl api-resources --verbs=list,get # Todos os recursos que suportam os verbos de API "list" e "get"
kubectl api-resources --api-group=extensions # Todos os recursos no grupo de API "extensions"
Formatação de Saída
Para enviar detalhes para a janela do terminal em um formato específico, adicione a flag -o (ou --output) para um comando kubectl suportado.
Formato de saída
Descrição
-o=custom-columns=<spec>
Imprimir uma tabela usando uma lista separada por vírgula de colunas personalizadas
-o=custom-columns-file=<filename>
Imprima uma tabela usando o modelo de colunas personalizadas no arquivo <nome do arquivo>
-o=json
Saída de um objeto de API formatado em JSON
-o=jsonpath=<template>
Imprima os campos definidos em uma expressão jsonpath
-o=jsonpath-file=<filename>
Imprima os campos definidos pela expressão jsonpath no arquivo <nome do arquivo>
-o=name
Imprima apenas o nome do recurso e nada mais
-o=wide
Saída no formato de texto sem formatação com qualquer informação adicional e, para pods, o nome do nó está incluído
-o=yaml
Saída de um objeto de API formatado em YAML
Verbosidade da Saída do Kubectl e Debugging
A verbosidade do Kubectl é controlado com os sinalizadores -v ou --v seguidos por um número inteiro representando o nível do log. As convenções gerais de log do Kubernetes e os níveis de log associados são descritos aqui.
Verbosidade
Descrição
--v=0
Geralmente útil para sempre estar visível para um operador de cluster.
--v=1
Um nível de log padrão razoável se você não deseja verbosidade.
--v=2
Informações úteis sobre o estado estacionário sobre o serviço e mensagens importantes de log que podem se correlacionar com alterações significativas no sistema. Este é o nível de log padrão recomendado para a maioria dos sistemas.
--v=3
Informações estendidas sobre alterações.
--v=4
Detalhamento no nível de debugging.
--v=6
Exibir os recursos solicitados.
--v=7
Exibir cabeçalhos de solicitação HTTP.
--v=8
Exibir conteúdo da solicitação HTTP.
--v=9
Exiba o conteúdo da solicitação HTTP sem o truncamento do conteúdo.
O Kubernetes contém várias ferramentas internas para ajudá-lo a trabalhar com o sistema Kubernetes.
Kubectl
kubectl é a ferramenta de linha de comando para o Kubernetes. Ela controla o gerenciador de cluster do Kubernetes.
Kubeadm
kubeadm é a ferramenta de linha de comando para provisionar facilmente um cluster Kubernetes seguro sobre servidores físicos ou na nuvem ou em máquinas virtuais (atualmente em alfa).
Minikube
minikube é uma ferramenta que facilita a execução local de um cluster Kubernetes de nó único em sua estação de trabalho para fins de desenvolvimento e teste.
Dashboard
Dashboard, a interface Web do Kubernetes, permite implantar aplicativos em contêiner em um cluster do Kubernetes, solucionar problemas e gerenciar o cluster e seus próprios recursos.
Helm
Kubernetes Helm é uma ferramenta para gerenciar pacotes de recursos pré-configurados do Kubernetes, também conhecidos como Kubernetes charts.
Use o Helm para:
Encontrar e usar softwares populares empacotados como Kubernetes charts
Compartilhar seus próprios aplicativos como Kubernetes charts
Criar builds reproduzíveis de seus aplicativos Kubernetes
Gerenciar de forma inteligente os arquivos de manifesto do Kubernetes
Gerenciar versões dos pacotes Helm
Kompose
Kompose é uma ferramenta para ajudar os usuários do Docker Compose a migrar para o Kubernetes.
Use o Kompose para:
Converter um arquivo Docker Compose em objetos Kubernetes
Ir do desenvolvimento local do Docker ao gerenciamento de seu aplicativo via Kubernetes
Contribuidores da documentação do Kubernetes podem:
Melhorar o conteúdo existente
Criar novo conteúdo
Traduzir a documentação
Gerenciar e publicar a documentação como parte do ciclo de lançamento do Kubernetes
Começando
Qualquer pessoa pode abrir uma issue sobre a documentação, ou contribuir com uma mudança por meio de um pull request (PR) para o repositório do Github kubernetes/website.
É recomendável que você se sinta confortável com git e
Github para trabalhar efetivamente na comunidade Kubernetes.
Algumas tarefas requerem mais confiança e mais acessos na organização do Kubernetes.
Veja Participando no SIG Docs para mais detalhes
sobre funções e permissões.
O SIG Docs é um grupo de contribuidores que publica e mantém
a documentação e o site do Kubernetes. Se envolver com o SIG Docs é uma ótima forma de contribuidores Kubernetes (pessoas desenvolvedoras de features ou outros) terem um grande impacto dentro do projeto Kubernetes.
A comunicação do SIG Docs é feita de diferentes formas:
Para contribuir com a comunidade Kubernetes por meio de fóruns on-line, como Twitter ou Stack Overflow, ou aprender sobre encontros locais e eventos do Kubernetes, visite a area de comunidade Kubernetes.
Para contribuir com o desenvolvimento de novas funcionalidades, leia o cheatsheet do colaborador para começar.
Leia o cheatsheet de contribuidor para saber mais sobre as funcionalidades de desenvolvimento do Kubernetes.
Essa página contém informações sobre a dashboard de analystics do kubernetes.io.
Essa dashboard foi feita usando
o Google Data Studio e possui informações coletadas do
kubernetes.io usando o Google Analytics.
Usando a dashboard
Por padrão, a dashboard mostra todos os analytics coletados nos últimos 30 dias. Use o seletor de data
para ver dados de outros intervalos de data. Outras
opções de filtros permitem que você veja dados baseados
em localização do usuário para acessar o site, a tradução
da documentação usada e outros.
Se você identificar um problema com essa dashboard ou quer solicitar qualquer melhoria, abra uma issue no repositório.
8 -
Clique nas tags ou use as listas suspensas para filtrar. Clique nos cabeçalhos das tabelas para classificar ou inverter a classificação.
Filtrar por Conceito:
Filtrar por objeto:
Filtrar por Comando:
 Essa página mostra o processo de instalação do conjunto de ferramentas
Essa página mostra o processo de instalação do conjunto de ferramentas